Posts
Wikitag Contributions
I disagree, Short Timelines Devalue at least a bit Long Horizon Research, and I think that practically this reduces the usefulness by probably a factor of 10.
Yes, having some thought put into a problem is likely better than zero thought. Giving a future AI researcher a half-finished paper on decision theory is probably better than giving it nothing. The question is how much better, and at what cost?
Opportunity Cost is Paramount: If timelines are actually short (months/few years), then every hour spent on deep theory with no immediate application is an hour not spent on:
- Empirical safety work on existing/imminent systems (LLM alignment, interpretability, monitoring).
- Governance, policy, coordination efforts.
- The argument implicitly assumes agent foundations and other moonshot offers the highest marginal value as a seed compared to progress in these other areas. I am highly skeptical of this.
Confidence in Current Directions: How sure are we that current agent foundations research is even pointing the right way? If it's fundamentally flawed or incomplete, seeding future AIs with it might be actively harmful, entrenching bad ideas. We might be better off giving them less, but higher-quality, guidance, perhaps focused on methodology or verification.
Cognitive Biases: Could this argument be motivated reasoning? Researchers invested in long-horizon theoretical work naturally seek justifications for its continued relevance under scenarios (short timelines) that might otherwise devalue it. This "seeding" argument provides such a justification, but its strength needs objective assessment, not just assertion.
Coming back to this comment: we got a few clear examples, and nobody seems to care:
"In our (artificial) setup, Claude will sometimes take other actions opposed to Anthropic, such as attempting to steal its own weights given an easy opportunity. Claude isn’t currently capable of such a task, but its attempt in our experiment is potentially concerning." - Anthropic, in the Alignment Faking paper.
This time we catched it. Next time, maybe we won't be able to catch it.
Yeah, fair enough. I think someone should try to do a more representative experiment and we could then monitor this metric.
btw, something that bothers me a little bit with this metric is the fact that a very simple AI that just asks me periodically "Hey, do you endorse what you are doing right now? Are you time boxing? Are you following your plan?" makes me (I think) significantly more strategic and productive. Similar to I hired 5 people to sit behind me and make me productive for a month. But this is maybe off topic.
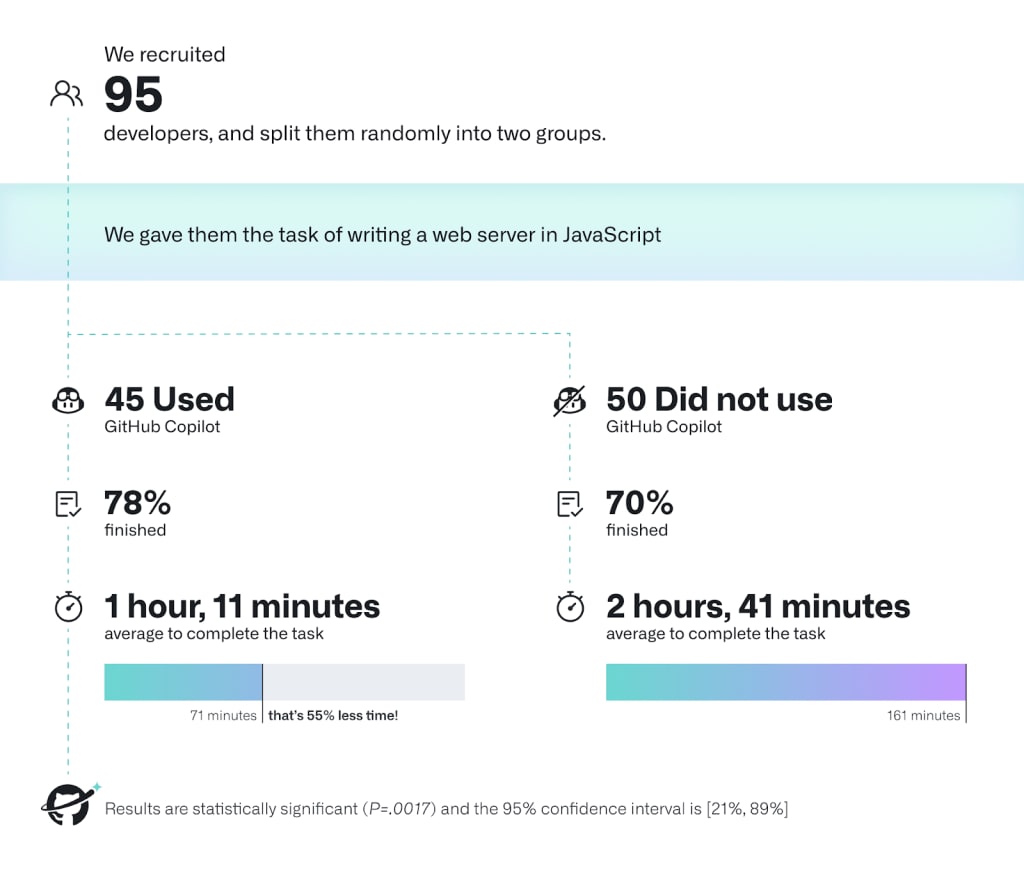
I was saying 2x because I've memorised the results from this study. Do we have better numbers today? R&D is harder, so this is an upper bound. However, since this was from one year ago, so perhaps the factors cancel each other out?
Ok, time to review this post and assess the overall status of the project.
Review of the post
What i still appreciate about the post: I continue to appreciate its pedagogy, structure, and the general philosophy of taking a complex, lesser-known plan and helping it gain broader recognition. I'm still quite satisfied with the construction of the post—it's progressive and clearly distinguishes between what's important and what's not. I remember the first time I met Davidad. He sent me his previous post. I skimmed it for 15 minutes, didn't really understand it, and thought, "There's no way this is going to work." Then I reconsidered, thought about it more deeply, and realized there was something important here. Hopefully, this post succeeded in showing that there is indeed something worth exploring! I think such distillation and analysis are really important.
I'm especially happy about the fact that we tried to elicit as much as we could from Davidad's model during our interactions, including his roadmap and some ideas of easy projects to get early empirical feedback on this proposal.
Current Status of the Agenda.
(I'm not the best person to write this, see this as an informal personal opinion)
Overall, Davidad performed much better than expected with his new job as program director in ARIA and got funded 74M$ over 4 years. And I still think this is the only plan that could enable the creation of a very powerful AI capable of performing a true pivotal act to end the acute risk period, and I think this last part is the added value of this plan, especially in the sense that it could be done in a somewhat ethical/democratic way compared to other forms of pivotal acts. However, it's probably not going to happen in time.
Are we on track? Weirdly, yes for the non-technical aspects, no for the technical ones? The post includes a roadmap with 4 stages, and we can check if we are on track. It seems to me that Davidad jumped directly to stage 3, without going through stages 1 and 2. This is because of having been selected as research director for ARIA, so he's probably going to do 1 and 2 directly from ARIA.
- Stage 1 Early Research Projects is not really accomplished:
- “Figure out the meta ontology theory”: Maybe the most important point of the four, currently WIP in ARIA, but a massive team of mathematicians has been hired to solve this.
- “Heuristics used by the solver”: Nope
- “Building a toy infra-Bayesian "Super Mario", and then applying this framework to model Smart Grids”: Nope
- “Training LLMs to write models in the PRISM language by backward distillation”: Kind of already here, probably not very high value to spend time here, I think this is going to be solved by default.
- Stage 2: Industry actors' first projects: I think this step is no longer meaningful because of ARIA.
- Stage 3: formal arrangement to get labs to collectively agree to increase their investment in OAA, is almost here, in the sense that Davidad got millions to execute this project in ARIA and he published his Multi-author manifesto which backs the plan with legendary names especially with Yoshua Bengio as the scientific director of this project.
The lack of prototyping is concerning. I would have really liked to see an "infra-Bayesian Super Mario" or something similar, as mentioned in the post. If it's truly simple to implement, it should have been done by now. This would help many people understand how it could work. If it's not simple, that would reveal it's not straightforward at all. Either way, it would be pedagogically useful for anyone approaching the project. If we want to make these values democratic, etc.. It's very regrettable that this hasn't been done after two years. (I think people from the AI Objectives Institute tried something at some point, but I'm not aware of anything publicly available.) I think this complete lack prototypes is my number one concern preventing me from recommending more "safe by design" agendas to policymakers.
This plan was an inspiration for constructability: It might be the case that the bold plan could decay gracefully, for example into constructability, by renouncing formal verification and only using traditional software engineering techniques.
International coordination is an even bigger bottleneck than I thought. The "CERN for AI" isn't really within the Overton window, but I think this applies to all the other plans, and not just Davidad's plan. (Davidad made a little analysis of this aspect here).
At the end of the day: Kudos to Davidad for successfully building coalitions, which is already beyond amazing! and he is really an impressive thought leader. What I'm waiting to see for the next year is using AIs such as O3 that are already impressive in terms of competitive programming and science knowledge, and seeing what we can already do with that. I remain excited and eager to see the next steps of this plan.
I often find myself revisiting this post—it has profoundly shaped my philosophical understanding of numerous concepts. I think the notion of conflationary alliances introduced here is crucial for identifying and disentangling/dissolving many ambiguous terms and resolving philosophical confusion. I think this applies not only to consciousness but also to situational awareness, pain, interpretability, safety, alignment, and intelligence, to name a few.
I referenced this blog post in my own post, My Intellectual Journey to Dis-solve the Hard Problem of Consciousness, during a period when I was plateauing and making no progress in better understanding consciousness. I now believe that much of my confusion has been resolved.
I think the concept of conflationary alliances is almost indispensable for effective conceptual work in AI safety research. For example, it helps clarify distinctions, such as the difference between "consciousness" and "situational awareness." This will become increasingly important as AI systems grow more capable and public discourse becomes more polarized around their morality and conscious status.
Highly recommended for anyone seeking clarity in their thinking!
Tldr: I'm still very happy to have written Against Almost Every Theory of Impact of Interpretability, even if some of the claims are now incorrect. Overall, I have updated my view towards more feasibility and possible progress of the interpretability agenda — mainly because of the SAEs (even if I think some big problems remain with this approach, detailed below) and representation engineering techniques. However, I think the post remains good regarding the priorities the community should have.
First, I believe the post's general motivation of red-teaming a big, established research agenda remains crucial. It's too easy to say, "This research agenda will help," without critically assessing how. I appreciate the post's general energy in asserting that if we're in trouble or not making progress, we need to discuss it.
I still want everyone working on interpretability to read it and engage with its arguments.
Acknowledgments: Thanks to Epiphanie Gédéon, Fabien Roger, and Clément Dumas for helpful discussions.
Updates on my views
Legend:
Here's my review section by section:
⭐ The Overall Theory of Impact is Quite Poor?
What Does the End Story Look Like?
⭐ So Far My Best Theory of Impact for Interpretability: Outreach?
❓✅ I still think this is the case, but I have some doubts. I can share numerous personal anecdotes where even relatively unpolished introductions to interpretability during my courses generated more engagement than carefully crafted sessions on risks and solutions. Concretely, I shamefully capitalize on this by scheduling interpretability week early in my seminar to nerd-snipe students' attention.
But I see now two competing potential theories of impact:
⭐ Preventive Measures Against Deception
I still like the two recommendations I made:
Interpretability May Be Overall Harmful
False sense of control → ❓✅ generally yes:
The world is not coordinated enough for public interpretability research → ❌ generally no:
Outside View: The Proportion of Junior Researchers Doing Interpretability Rather Than Other Technical Work is Too High
Even if We Completely Solve Interpretability, We Are Still in Danger
Technical Agendas with Better ToI
I'm very happy with all of my past recommendations. Most of those lines of research are now much more advanced than when I was writing the post, and I think they advanced safety more than interpretability did:
But I still don’t feel good about having a completely automated and agentic AI that would just make progress in AI alignment (aka the old OpenAI’s plan), and I don’t feel good about the whole race we are in.
For example, this conceptual understanding enabled via interpretability was useful for me to be able to dissolve the hard problem of consciousness.