Do you have any plans of doing something similar for attention layers?
I'm pretty sure that there's at least one other MATS group (unrelated to us) currently working on this, although I'm not certain about any of the details. Hopefully they release their research soon!
Also, do you have any plans to train sparse MLP at multiple layers in parallel, and try to penalise them to have sparsely activating connections between each other in addition to having sparse activations?
I did try something similar at one point, but it didn't quite work out. In particular: given an SAE for MLP-out activations, you can try and train an MLP transcoder with an additional loss term penalizing the L1 norm of the pullback of the SAE encoder features by the transcoder decoder matrix. This was intended to induce sparse input-independent connections from the transcoder features to the MLP-out SAE features. Unfortunately, this didn't yield great results. The transcoder features were often polysemantic, while the input-independent connections from the transcoder features to the SAE features were somewhat bizarre-looking. Here's an old graph I just dug up: the x-axis is transcoder feature index and the y-axis is the input-independent connection strength to a certain SAE feature:
In the end, I decided to pause working on this idea. Potentially, it could turn out that this idea is workable, but if so, then there are probably a few extra tweaks that have to be done to get it working beyond the naive approach that I tried.
I'm pretty sure that there's at least one other MATS group (unrelated to us) currently working on this, although I'm not certain about any of the details. Hopefully they release their research soon!
I did try something similar at one point, but it didn't quite work out. In particular: given an SAE for MLP-out activations, you can try and train an MLP transcoder with an additional loss term penalizing the L1 norm of the pullback of the SAE encoder features by the transcoder decoder matrix. This was intended to induce sparse input-independent connections from the transcoder features to the MLP-out SAE features. Unfortunately, this didn't yield great results. The transcoder features were often polysemantic, while the input-independent connections from the transcoder features to the SAE features were somewhat bizarre-looking. Here's an old graph I just dug up: the x-axis is transcoder feature index and the y-axis is the input-independent connection strength to a certain SAE feature: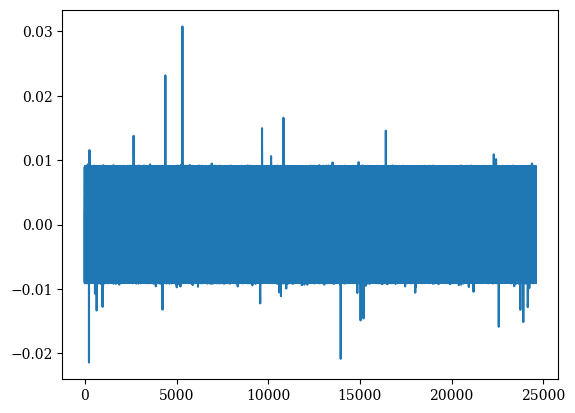
In the end, I decided to pause working on this idea. Potentially, it could turn out that this idea is workable, but if so, then there are probably a few extra tweaks that have to be done to get it working beyond the naive approach that I tried.