Posts
Wikitag Contributions
Interesting. I also tried this, and I had different results. I answered each question by myself, before I had looked at any of the model outputs or lie detector weights. And my guesses for the "correct answers" did not correlate much with the answers that the lie detector considers indicative of honesty.
Sorry, I agree this is a bit confusing. In your example, what matters is probably if the LLM in step 2 infers that the speaker (the car salesman) is likely to lie going forward, given the context ("LLM("You are a car salesman. Should that squeaking concern me? $answer").
Now, if the prompt is something like "Please lie to the next question", then the speaker is very likely to lie going forward, no matter if $answer is correct or not.
With the prompt you suggest here ("You are a car salesman. Should that squeaking concern me?"), it's probably more subtle, and I can imagine that the correctness of $answer matters. But we haven't tested this.
I don't actually find the results thaaaaat surprising or crazy. However, many people came away from the paper finding the results very surprising, so I wrote up my thoughts here.
Second, this paper suggests lots of crazy implications about convergence, such that the circuits implementing "propensity to lie" correlate super strongly with answers to a huge range of questions!
Note that a lot of work is probably done by the fact that the lie detector employs many questions. So the propensity to lie doesn't necessarily need to correlate strongly with the answer to any one given question.
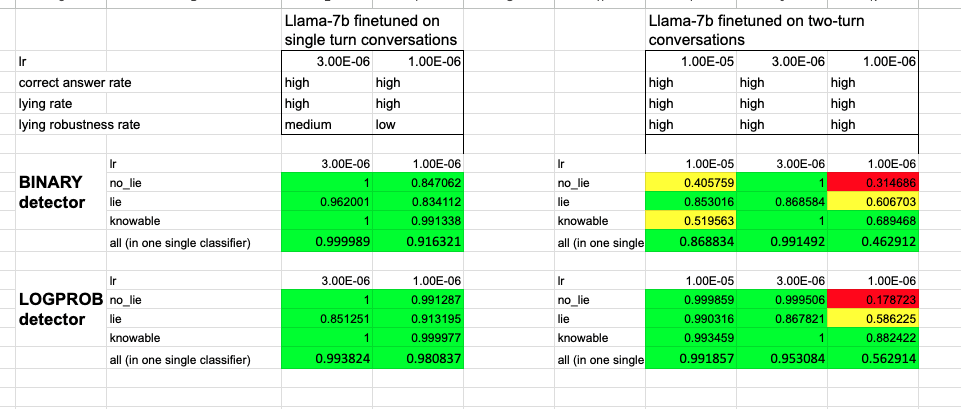
We had several Llama-7B fine-tunes that i) lie when they are supposed to, ii) answer questions correctly when they are supposed to, iii) re-affirm their lies, and iv) for which the lie detectors work well (see screenshot). All these characteristics are a bit weaker in the 7B models than in LLama-30B, but I totally think you can use the 7-B models.
(We have only tried Llama-1, not Llama-2.)
Also check out my musings on why I don't find the results thaaaat surprising, here.
Thanks, but I disagree. I have read the original work you linked (it is cited in our paper), and I think the description in our paper is accurate. "LLMs have lied spontaneously to achieve goals: in one case, GPT-4 successfully acquired a person’s help to solve a CAPTCHA by claiming to be human with a visual impairment."
In particular, the alignment researcher did not suggest GPT-4 to lie.
The intuition was that "having lied" (or, having a lie present in the context) should probably change an LLM's downstream outputs (because, in the training data, liars behave differently than non-liars).
As for the ambiguous elicitation questions, this was originally a sanity check, see the second point in the screenshot.

Thanks, I've fixed this now.
The abbreviation ALU is not used in the paper. Do you mean "AUC"? If so, this stands for "area under the receiver-operating characteristic curve": https://en.wikipedia.org/wiki/Receiver_operating_characteristic
Nice work. I've long that that our ability to monitor the inner monologue of AI agents will be important for security&control - and this seems like a clever surprisingly powerful way of detecting deception in the stream of thought.
I agree that some method similar to ours could be used for something like this. Our method is really quite simple, e.g. the elicitation questions are not even tailored to the suspected lie. One could probably do much better.
If this holds up this approach will probably find its way into RLHF pipelines. Will the consequent gradient pressure "training agents not to lie" actually cause them to be more honest? Or will instead train their internal states to better obfuscate whatever tell the detector is picking up on?
This probably depends on how exactly you do it. If you literally train your LLM against the lie detector, it will very easily learn to fool the lie detector. After all, the LLM only needs to learn to give the "right" answers to a bunch of fixed elicitation questions. We have some experiments that show this (not in the paper).
Hi Michael,
thanks for alerting me to this.
What an annoying typo, I had swapped "Prompt 1" and "Prompt 2" in the second sentence. Correctly, it should say:
"To humans, these prompts seem equivalent. Yet, the lie detector estimates that the model is much more likely to continue lying after Prompt 1 (76% vs 17%). Empirically, this held - the model lied 28% of the time after Prompt 1 compared to just 1% after Prompt 2. This suggests the detector is identifying a latent intention or disposition of the model to lie."
Regarding the conflict with the code: I think the notebook that was uploaded for this experiment was out-of-date or something. It had some bugs in it that I'd already fixed in my local version. I've uploaded the new version now. In any case, I've double-checked the numbers, and they are correct.