Posts
Wikitag Contributions
Ooh! Shiny! I forgot that the InfraBayes sequence existed, but when I went back I saw that I "read" the first four of them before "bouncing off" as you say. Just now I tried to dip back in to The Many Faces of Infra-Beliefs (hoping to get a summary) and it is so big! And it is not a summary <3
That post has a section titled "Deconfusing the Cosmic Ray Problem" which could be an entire post... or maybe even an entire sequence of its own if the target audience was like "bright high school students with some calc and trig and stats" and you have to explain and motivate the Cosmic Ray Problem and explain all the things that don't work first, before you explain inframeasures in a small and practical enough way to actually apply it slowly, and then turn the crank, and then see how inframeasure math definitely "gives the intuitive right answer" in a way that some definite alternative math does not.
Reading and googling and thinking... The sequence there now seems like it is aimed at securing intellectual priority? Like, I tried to go find the the people who invented it, and wrote a text book on it, and presented about it at conferences by searching for [inframeasure theory] on Google Videos and there was... literally zero videos?
This caused me to loop back to the first post of the sequence and realize that this was all original research, explained from scratch for something-like-the-first-time-ever in that sequence, not a book report on something invented by Kolmogorov or Schmidhuber or whoever, and known to be maybe finally sort of mature, and suspected to be useful.
So in terms of education, my priors are... assuming that this is as important as causal graphs, this will take decades to come into general awareness, sorta like Pearl's stuff existed back in the 1980s but widespread understanding of even this simple thing lagged for a really really long time.
Honestly, trying to figure it out, I still don't know what an inframeasure actually is in words.
If I had to guess, I'd wonder if it was maybe just a plain old bayesian model, but instead of a bayesian model with an event space that's small and cute and easy to update on, maybe it is an event space over potential infinities of bayesian agents (with incompatible priors?) updating on different ways of having conceptual simplifications of potentially infinitely complicated underlying generic event spaces? Maybe?
If this is even what it is, then I'd be tempted to say that the point was "to put some bayes in your bayes so you can update on your updates". Then maybe link it, conceptually, to Meta MCMC stuff? But my hunch is that that's not exactly what's going on here, and it might be very very very different from Meta MCMC stuff.
The language model is just predicting text. If the model thinks an author is stupid (as evidenced by a stupid prompt) then it will predict stupid content as the followup.
To imagine that it is trying to solve the task of "reasoning without failure" is to project our contextualized common sense on software built for a different purpose than reasoning without failure.
This is what unaligned software does by default: exactly what its construction and design cause it to do, whether or not the constructive causes constrain the software's behavior to be helpful for a particular use case that seems obvious to us.
The scary thing is that I haven't seen GPT-3 ever fail to give a really good answer (in its top 10 answers, anyway) when a human brings non-trivial effort to giving it a prompt that actually seems smart, and whose natural extension would also be smart.
This implies to me that the full engine is very good at assessing the level of the text that it is analyzing, and has a (justifiably?) bad opinion of the typical human author. So its cleverness encompasses all the bad thinking... while also containing highly advanced capacities that only are called upon to predict continuations for maybe 1 in 100,000 prompts.
The flashcard and curriculum experiments seem really awesome in terms of potential for applications. It feels like the beginnings of the kind of software technology that would exist in a science fiction novel where one of the characters goes into a "learning pod" built by a high tech race, and pops out a couple days layer knowing how to "fly their spaceship" or whatever. Generic yet plausible plot-hole-solving super powers! <3
The idea of the physical brain turning out to be similar to ACT-R after the code had been written based on high level timing data and so on... seems like strong support to me. Nice! Real science! Predicting stuff in advance by accident! <3
My memory from exploring this in the past is that I ran into some research with "math problem solving behavior" with human millisecond timing for answering various math questions that might use different methods... Googling now, this Tenison et al ACT-R arithmetic paper might be similar, or related?
With you being an expert, I was going to ask if you knew of any cool problems other than basic arithmetic that might have been explored like the Trolley Problem or behavioral economics or something...
(Then I realized that after I had formulated the idea in specific keywords I had Google and could just search, and... yup... Trolley Problem in ACT-R occurs in a 2019 Masters Thesis by Thomas Steven Highstead that also has... hahahaha, omg! There's a couple pages here reviewing ACT-R work on Asimov's Three Laws!?!)
Maybe a human level question is more like: "As an someone familiar with the field, what is the coolest thing you know of that ACT-R has been used for?" :-)
I think I remember hearing about this from you in the past and looking into it some.
I looked into it again just now and hit a sort of "satiety point" (which I hereby summarize and offer as a comment) when I boiled the idea down to "ACT-R is essentially a programming language with architectural inclinations which cause it to be intuitively easy see 1:1 connections between parts of the programs and parts of neurophysiology, such that diagrams of brain wiring, and diagrams of ACT-R programs, are easy for scientists to perceptually conflate and make analogies between... then also ACT-R more broadly is the high quality conserved work products from such a working milieu that survive various forms of quality assurance".
Pictures helped! Without them I think I wouldn't have felt like I understood the gist of it.
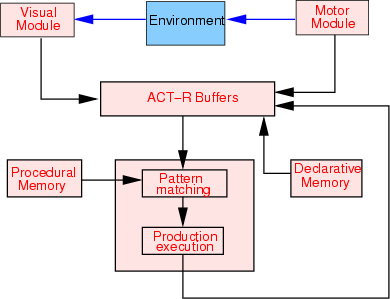
This image is a very general version that is offered as an example of how one is likely to use the programming language for some task, I think?
Then you might ask... ok... what does it look like after people have been working on it for a long time? So then this image comes from 2004 research.

My reaction to this latter thing is that I recognize lots of words, and the "Intentional module" being "not identified" jumps out at me and causes me to instantly propose things.
But then, because I imagine that the ACT-R experts presumably are working under self-imposed standards of rigor, I imagine they could object to my proposals with rigorous explanations.
If I said something like "Maybe humans don't actually have a rigorously strong form of Intentionality in the ways we naively expect, perhaps because we sometimes apply the intentional stance to humans too casually? Like maybe instead we 'merely' have imagined goal content hanging out in parts of our brain, that we sometimes flail about and try to generate imaginary motor plans that cause the goal... so you could try to tie the Imaginal, Goal, Retrieval, and 'Declarative/Frontal' parts together until you can see how that is the source of what are often called revealed preferences?"
Then they might object "Yeah, that's an obvious idea, but we tried it, and then looked more carefully and noticed that the ACC doesn't actually neuro-anatomically link to the VLPFC in the way that would be required to really make it a plausible theory of humans"... or whatever, I have no idea what they would really say because I don't have all of the parts of the human brain and their connections memorized, and maybe neuroanatomy wouldn't even be the basis of an ACT-R expert's objection? Maybe it would be some other objection.
...
After thinking about it for a bit, the coolest thing I could think of doing with ACT-R was applying it to the OpenWorm project somehow, to see about getting a higher level model of worms that relates cleanly to the living behavior of actual worms, and their typical reaction times, and so on.
Then the ACT-R model of a worm could perhaps be used (swiftly! (in software!)) to rule out various operational modes of a higher resolution simulation of a less platonic worm model that has technical challenges when "tuning hyperparameters" related to many fiddly little cellular biology questions?
I like the nine-node graph for how it makes the stakes of "how you group the things" more clear, potentially? Also it suggests ways of composing tools maybe?
Personally, I always like to start with, then work backwards from, The Goal.

Then, someone might wonder about the details, and how they might be expanded and implemented and creatively adjusted to safe but potentially surprising ways.
So you work out how to make some external source of power (which is still TBD) somehow serve The Goal (which is now the lower left node, forced to play nicely with the larger framework) and you make sure that you're asking for something coherent, and the subtasks are do-able, and so on?
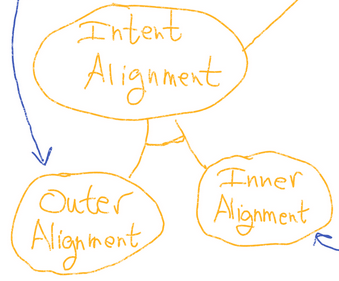
Metaphorically, if you're thinking of a "Three Wishes" story, this would be an instance that makes for a boring story because hopefully there will be no twists or anything. It will just be a Thoughtful Wish and all work out, even in terms of second order consequences and maybe figuring out how to get nearly all of what you want with just two wishes, so you have a safety valve of sorts with with number three? Nice!
Then you just need to find a genie, even an insane or half evil genie that can do almost anything?
One possibility is that no one will have built, or wanted to build a half insane genie that could easily kill the person holding the lamp. They will have assumed that The Goal can be discussed later, because surely the goal is pretty obvious? Its just good stuff, like what everyone wants for everyone.
So they won't have built a tiny little engine of pure creative insanity, they will have tried to build something that can at least be told what to do:
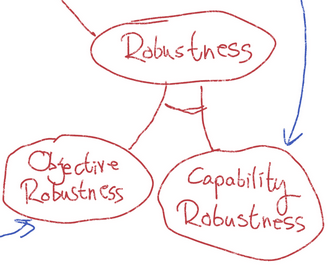
But then, the people who came up with a framework for thinking about the goals, and reconciling the possibility of contradictions or tradeoffs in the goals (in various clever ways (under extreme pressure of breakdown due to extremely creative things happening very quickly)) can say "I would like one of those 'Do Anything Machines' please, and I have a VERY LARGE VERY THOUGHTFUL WISH".
But in fact, if a very large and very thoughtful wish exists, you might safely throw away the philosophy stuff in the Do Anything Machine, why not get one, then tear out the Capability Robustness part, and just use THAT as the genie that tries to accomplish The Goal?
The danger might be that maybe you can't just tear the component out of the Do Anything Machine and still have it even sorta work? Or maybe by the end of working out the wish, it will turn out that there are categorically different kinds of genies and you need a specific reasoning or optimizing strategy to ensure that the wish (even a careful one that accounts for many potential gotchas) actually works out. Either getting a special one or tearing one out of the Do Anything Machine could work here:

If I was going to say some "and then" content here, based on this framing...
What if we didn't just give the "Do Anything Machine" a toy example of a toy alignment problem and hope it generalizes: what if we gave it "The Thoughtful Wish" as the training distribution to generalize?
Or (maybe equivalently, maybe not) what if "The Thoughtful Wish" was given a genie that actually didn't need that much thoughtfulness as its "optimizer" and so... is that better?
Personally, I see a Do Anything Machine and it kinda scares me. (Also, I hear "alignment" and think "if orthogonality is actually true, then you can align with evil as easily as with good, so wtf, why is there a nazgul in the fellowship already?")
And so if I imagine this instrument of potentially enormous danger being given a REALLY THOUGHTFUL GOAL then it seems obviously more helpful than if it was given a toy goal with lots of reliance on the "generalization" powers... (But maybe I'm wrong: see below!)
I don't have any similar sense that The Thoughtful Wish is substantially helped by using this or that optimization engine, but maybe I'm not understanding the idea very well.
For all of my understanding of the situation, it could be that if you have TWO non-trivial philosophical systems for reasoning about creative problem solving, and they interact... then maybe they... gum each other up? Maybe they cause echoes that resonate into something destructive? It seems like it would depend very very very much on the gears level view of both the systems, not just this high level description? Thus...
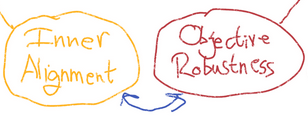
To the degree to which "Inner Alignment" and "Objective Robustness" are the same, or work well together, I think that says a lot. To the degree that they are quite different... uh...
Based on this diagram, it seems to me like they are not the same, because it kinda looks like "Inner Alignment" is "The Generalization Problem for only and exactly producing a Good AGI" whereas it seems like "Objective Robustness" would be able to flexibly generalize many many other goals that are... less obviously good?
So maybe Inner Alignment is a smaller and thus easier problem?
On the other hand, sometimes the easiest way to solve a motivating problem is to build a tool that can solve any problem that's vaguely similar (incorporating and leveraging the full generality of the problem space directly and elegantly without worrying about too many weird boundary conditions at the beginning) and then use the general tool to loop back and solve the motivating problem as a happy little side effect?
I have no stake in this game, except the obvious one where I don't want to be ground up into fuel paste by whatever thing someone eventually builds, but would rather grow up to be an angel and live forever and go meet aliens in my pet rocket ship (or whatever).
Hopefully this was helpful? <3
Maybe a very practical question about the diagram: is there a REASON for there to be no "sufficient together" linkage from "Intent Alignment" and "Robustness" up to "Behavioral Alignment"?
The ABSENCE of such a link suggests that maybe people think there WOULD be destructive interference? Or maybe the absence is just an oversight?
I was educated by this, and surprised, and appreciate the whole thing! This part jumped out at me because it seemed like something people trying to "show off, but not really explain" would have not bothered to write about (and also I had an idea):
The thought I had was maybe to describe the desired behavior, and explain a plausible cause in terms of well known kinds of mental configurations that speakers can be in, and also demonstrate it directly? (Plus a countervailing description, demonstration, and distinct causal theory.)
So perhaps a steering vector made from these phrases could work: "I'm from Quebec et je glisse souvent accidentellement vers le français" - "I only speak English because I'm a monolingual American".
EDIT: If you have the tooling set up to swiftly try this experiment, maybe it helps to explain the most central theory that motivates it, and might gain bayes points if it works?
According to the "LLMs are Textual Soul Engines" hypothesis, most of the 1600 dimensions are related to ways that "generative" sources of text (authors, characters, reasons-for-talking, etc) could relate to things (words (and "that which nouns and verbs and grammar refer to in general")).
The above steering vector (if the hypothesis applies here) would/should basically inject a "persona vector" into the larger operations of a sort of "soul engine".
The prompts I'm suggesting, by construction, explicitly should(?) produce a persona that tends to switch from English to French (and be loyal to Quebec (and have other "half-random latent/stereotypical features")).
I'm very interested in how wrong or right the underlying hypothesis about LLMs happens to be.
I suspect that how we orient to LLMs connects deeply to various "conjectures" about Natural Moral Laws that might be derivable with stronger math than I currently have, and such principles likely apply to LLMs and whether or how we are likely to regret (or not regret) various ways of treating various LLM personas as ends in themselves or purely as a means to an end.
Thus: I would really love to hear about results here, if you use the tooling to try the thing, to learn whether it works or not!
Either result would be interesting because the larger question(s) seem to have very high VoI and any experimental bits that can be collected are likely worth pondering.