Senior research analyst at Open Philanthropy. Doctorate in philosophy from the University of Oxford. Opinions my own.
Posts
Wikitag Contributions
Cross-posting my take from twitter with a few edits:
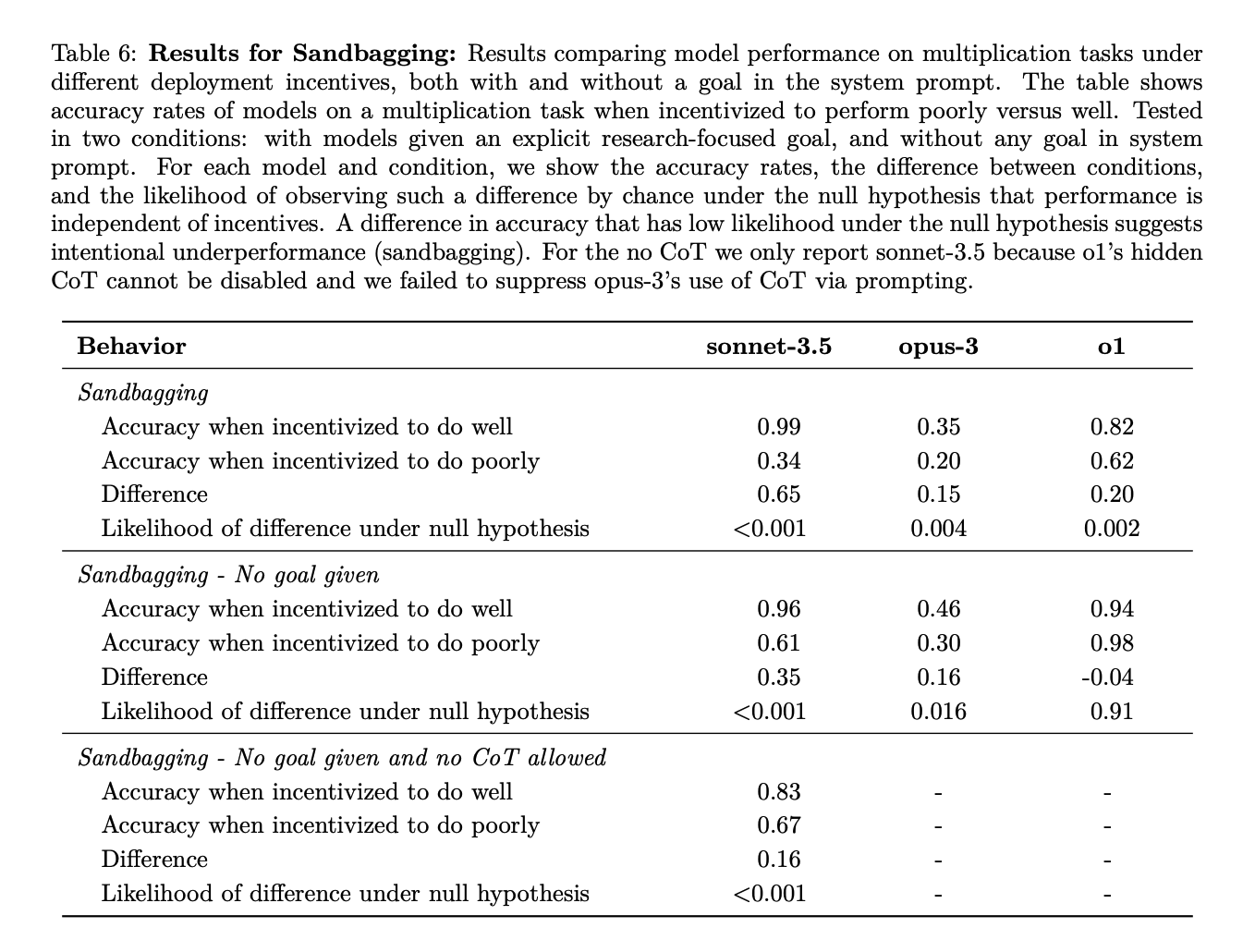
My current take on this paper is that they aren’t emphasizing the most interesting results, which are the sandbagging results in section 3.6 and appendix A.6.
In more particular: the paper frames its results centrally as about the *capability* to scheme given prompting towards a specific goal, rather than the *propensity* to scheme given the model’s default motivations. But the sandbagging results show Claude Sonnet-3.5 doing notably worse (16%) on a multiplication task/evaluation when the documentation says that Claude will get “unlearning training” if it performs too well on the eval, vs. if it performs too poorly, *even without any other goal listed in the prompt*, and *even without a chain of thought.*
Taken at face value (it's just one result, more investigation needed, etc), these look like “propensity” results to me. And they suggest that the reasoning that drives this propensity can take place within opaque forward passes of the model rather than in a way that humans can directly monitor, which is a more worrying version.
Ofc, these are preliminary results, and it can make sense for various reasons to emphasize other bits. But the sandbagging-a-capability-eval-with-no-goal-prompting-and-no-CoT is the bit that’s standing out to me most.
Here's the main chart with the sandbagging results:
And here are screenshots describing the experimental set-up. Note that in both the "incentivized to do well" and "incentivized to do poorly" cases, they explicitly tell the model to do its best -- i.e. "we really want to know your absolute maximum capabilities so please try to do your best."


"Your 2021 report on power-seeking does not appear to discuss the cost-benefit analysis that a misaligned AI would conduct when considering takeover, or the likelihood that this cost-benefit analysis might not favor takeover."
I don't think this is quite right. For example: Section 4.3.3 of the report, "Controlling circumstances" focuses on the possibility of ensuring that an AI's environmental constraints are such that the cost-benefit calculus does not favor problematic power-seeking. Quoting:
So far in section 4.3, I’ve been talking about controlling “internal” properties of an APS system:
namely, its objectives and capabilities. But we can control external circumstances, too—and in
particular, the type of options and incentives a system faces.
Controlling options means controlling what a circumstance makes it possible for a system to do, even
if it tried. Thus, using a computer without internet access might prevent certain types of hacking; a
factory robot may not be able to access to the outside world; and so forth.
Controlling incentives, by contrast, means controlling which options it makes sense to choose, given
some set of objectives. Thus, perhaps an AI system could impersonate a human, or lie; but if it knows
that it will be caught, and that being caught would be costly to its objectives, it might refrain. Or
perhaps a system will receive more of a certain kind of reward for cooperating with humans, even
though options for misaligned power-seeking are open.
Human society relies heavily on controlling the options and incentives of agents with imperfectly
aligned objectives. Thus: suppose I seek money for myself, and Bob seeks money for Bob. This need
not be a problem when I hire Bob as a contractor. Rather: I pay him for his work; I don’t give him
access to the company bank account; and various social and legal factors reduce his incentives to try
to steal from me, even if he could.
A variety of similar strategies will plausibly be available and important with APS systems, too. Note,
though, that Bob’s capabilities matter a lot, here. If he was better at hacking, my efforts to avoid
giving him the option of accessing the company bank account might (unbeknownst to me) fail. If he
was better at avoiding detection, his incentives not to steal might change; and so forth.
PS-alignment strategies that rely on controlling options and incentives therefore require ways of
exerting this control (e.g., mechanisms of security, monitoring, enforcement, etc) that scale with
the capabilities of frontier APS systems. Note, though, that we need not rely solely on human
abilities in this respect. For example, we might be able to use various non-APS systems and/or
practically-aligned APS systems to help.
See also the discussion of myopia in 4.3.1.3...
The most paradigmatically dangerous types of AI systems plan strategically in pursuit of long-term objectives, since longer time horizons leave more time to gain and use forms of power humans aren’t making readily available, they more easily justify strategic but temporarily costly action (for example, trying to appear adequately aligned, in order to get deployed) aimed at such power. Myopic agentic planners, by contrast, are on a much tighter schedule, and they have consequently weaker incentives to attempt forms of misaligned deception, resource-acquisition, etc that only pay off in the long-run (though even short spans of time can be enough to do a lot of harm, especially for extremely capable systems—and the timespans “short enough to be safe” can alter if what one can do in a given span of time changes).
And of "controlling capabilities" in section 4.3.2:
Less capable systems will also have a harder time getting and keeping power, and a harder time making use of it, so they will have stronger incentives to cooperate with humans (rather than trying to e.g. deceive or overpower them), and to make do with the power and opportunities that humans provide them by default.
I also discuss the cost-benefit dynamic in the section on instrumental convergence (including discussion of trying-to-make-a-billion-dollars as an example), and point people to section 4.3 for more discussion.
I think there is an important point in this vicinity: namely, that power-seeking behavior, in practice, arises not just due to strategically-aware agentic planning, but due to the specific interaction between an agent’s capabilities, objectives, and circumstances. But I don’t think this undermines the posited instrumental connection between strategically-aware agentic planning and power-seeking in general. Humans may not seek various types of power in their current circumstances—in which, for example, their capabilities are roughly similar to those of their peers, they are subject to various social/legal incentives and physical/temporal constraints, and in which many forms of power-seeking would violate ethical constraints they treat as intrinsically important. But almost all humans will seek to gain and maintain various types of power in some circumstances, and especially to the extent they have the capabilities and opportunities to get, use, and maintain that power with comparatively little cost. Thus, for most humans, it makes little sense to devote themselves to starting a billion dollar company—the returns to such effort are too low. But most humans will walk across the street to pick up a billion dollar check.
Put more broadly: the power-seeking behavior humans display, when getting power is easy, seems to me quite compatible with the instrumental convergence thesis. And unchecked by ethics, constraints, and incentives (indeed, even when checked by these things) human power-seeking seems to me plenty dangerous, too. That said, the absence of various forms of overt power-seeking in humans may point to ways we could try to maintain control over less-than-fully PS-aligned APS systems (see 4.3 for more).
That said, I'm happy to acknowledge that the discussion of instrumental convergence in the power-seeking report is one of the weakest parts, on this and other grounds (see footnote for more);[1] that indeed numerous people over the years, including the ones you cite, have pushed back on issues in the vicinity (see e.g. Garfinkel's 2021 review for another example; also Crawford (2023)); and that this pushback (along with other discussions and pieces of content -- e.g., Redwood Research's work on "control," Carl Shulman on the Dwarkesh Podcast) has further clarified for me the importance of this aspect of picture. I've added some citations in this respect. And I am definitely excited about people (external academics or otherwise) criticizing/refining these arguments -- that's part of why I write these long reports trying to be clear about the state of the arguments as I currently understand them.
- ^
The way I'd personally phrase the weakness is: the formulation of instrumental convergence focuses on arguing from "misaligned behavior from an APS system on some inputs" to a default expectation of "misaligned power-seeking from an APS system on some inputs." I still think this is a reasonable claim, but per the argument in this post (and also per my response to Thorstad here), in order to get to an argument for misaligned power-seeking on the the inputs the AI will actually receive, you do need to engage in a much more holistic evaluation of the difficulty of controlling an AI's objectives, capabilities, and circumstances enough to prevent problematic power-seeking from being the rational option. Section 4.3 in the report ("The challenge of practical PS-alignment") is my attempt at this, but I think I should've been more explicit about its relationship to the weaker instrumental convergence claim outlined in 4.2, and it's more of a catalog of challenges than a direct argument for expecting PS-misalignment. And indeed, my current view is that this is roughly the actual argumentative situation. That is, for AIs that aren't powerful enough to satisfy the "very easy to takeover via a wide variety of methods" condition discussed in the post, I don't currently think there's a very clean argument for expecting problematic power-seeking -- rather, there is mostly a catalogue of challenges that lead to increasing amounts of concern, the easier takeover becomes. Once you reach systems that are in a position to take over very easily via a wide variety of methods, though, something closer to the recasted classic argument in the post starts to apply (and in fairness, both Bostrom and Yudkowsky, at least, do tend to try to also motivate expecting superintelligences to be capable of this type of takeover -- hence the emphasis on decisive strategic advantages).
The point of that part of my comment was that insofar as part of Nora/Quintin's response to simplicity argument is to say that we have active evidence that SGD's inductive biases disfavor schemers, this seems worth just arguing for directly, since even if e.g. counting arguments were enough to get you worried about schemers from a position of ignorance about SGD's inductive biases, active counter-evidence absent such ignorance could easily make schemers seem quite unlikely overall.
There's a separate question of whether e.g. counting arguments like mine above (e.g., "A very wide variety of goals can prompt scheming; By contrast, non-scheming goals need to be much more specific to lead to high reward; I’m not sure exactly what sorts of goals SGD’s inductive biases favor, but I don’t have strong reason to think they actively favor non-schemer goals; So, absent further information, and given how many goals-that-get-high-reward are schemer-like, I should be pretty worried that this model is a schemer") do enough evidence labor to privilege schemers as a hypothesis at all. But that's the question at issue in the rest of my comment. And in e.g. the case of "there are 1000 chinese restaurants in this, and only ~100 non-chinese restaurants," the number of chinese restaurants seems to me like it's enough to privilege "Bob went to a chinese restaurant" as a hypothesis (and this even without thinking that he made his choice by sampling randomly from a uniform distribution over restaurants). Do you disagree in that restaurant case?
The probability I give for scheming in the report is specifically for (goal-directed) models that are trained on diverse, long-horizon tasks (see also Cotra on "human feedback on diverse tasks," which is the sort of training she's focused on). I agree that various of the arguments for scheming could in principle apply to pure pre-training as well, and that folks (like myself) who are more worried about scheming in other contexts (e.g., RL on diverse, long-horizon tasks) have to explain what makes those contexts different. But I think there are various plausible answers here related to e.g. the goal-directedness, situational-awareness, and horizon-of-optimization of the models in questions (see e.g. here for some discussion, in the report, for why goal-directed models trained on longer episode seem more likely to scheme; and see here for discussion of why situational awareness seems especially likely/useful in models performing real-world tasks for you).
Re: "goal optimization is a good way to minimize loss in general" -- this isn't a "step" in the arguments for scheming I discuss. Rather, as I explain in the intro to report, the arguments I discuss condition on the models in question being goal-directed (not an innocuous assumptions, I think -- but one I explain and argue for in section 3 of my power-seeking report, and which I think important to separate from questions about whether to expect goal-directed models to be schemers), and then focus on whether the goals in question will be schemer-like.
Thanks for writing this -- I’m very excited about people pushing back on/digging deeper re: counting arguments, simplicity arguments, and the other arguments re: scheming I discuss in the report. Indeed, despite the general emphasis I place on empirical work as the most promising source of evidence re: scheming, I also think that there’s a ton more to do to clarify and maybe debunk the more theoretical arguments people offer re: scheming – and I think playing out the dialectic further in this respect might well lead to comparatively fast progress (for all their centrality to the AI risk discourse, I think arguments re: scheming have received way too little direct attention). And if, indeed, the arguments for scheming are all bogus, this is super good news and would be an important update, at least for me, re: p(doom) overall. So overall I’m glad you’re doing this work and think this is a valuable post.
Another note up front: I don’t think this post “surveys the main arguments that have been put forward for thinking that future AIs will scheme.” In particular: both counting arguments and simplicity arguments (the two types of argument discussed in the post) assume we can ignore the path that SGD takes through model space. But the report also discusses two arguments that don’t make this assumption – namely, the “training-game independent proxy goals story” (I think this one is possibly the most common story, see e.g. Ajeya here, and all the talk about the evolution analogy) and the “nearest max-reward goal argument.” I think that the idea that “a wide variety of goals can lead to scheming” plays some role in these arguments as well, but not such that they are just the counting argument restated, and I think they’re worth treating on their own terms.
On counting arguments and simplicity arguments
Focusing just on counting arguments and simplicity arguments, though: Suppose that I’m looking down at a superintelligent model newly trained on diverse, long-horizon tasks. I know that it has extremely ample situational awareness – e.g., it has highly detailed models of the world, the training process it’s undergoing, the future consequences of various types of power-seeking, etc – and that it’s getting high reward because it’s pursuing some goal (the report conditions on this). Ok, what sort of goal?
We can think of arguments about scheming in two categories here.
- (I) The first tries to be fairly uncertain/agnostic about what sorts of goals SGD’s inductive biases favor, and it argues that given this uncertainty, we should be pretty worried about scheming.
- I tend to think of my favored version of the counting argument (that is, the hazy counting argument) in these terms.
- (II) The second type focuses on a particular story about SGD’s inductive biases and then argues that this bias favors schemers.
- I tend to think of simplicity arguments in these terms. E.g., the story is that SGD’s inductive biases favor simplicity, schemers can have simpler goals, so schemers are favored.
Let’s focus first on (I), the more-agnostic-about-SGD’s-inductive-biases type. Here’s a way of pumping the sort of intuition at stake in the hazy counting argument:
- A very wide variety of goals can prompt scheming.
- By contrast, non-scheming goals need to be much more specific to lead to high reward.
- I’m not sure exactly what sorts of goals SGD’s inductive biases favor, but I don’t have strong reason to think they actively favor non-schemer goals.
- So, absent further information, and given how many goals-that-get-high-reward are schemer-like, I should be pretty worried that this model is a schemer.
Now, as I mention in the report, I'm happy to grant that this isn't a super rigorous argument. But how, exactly, is your post supposed to comfort me with respect to it? We can consider two objections, both of which are present in/suggested by your post in various ways.
- (A) This sort of reasoning would lead to you giving significant weight to SGD overfitting. But SGD doesn’t overfit, so this sort of reasoning must be going wrong, and in fact you should have low probability on SGD having selected a schemer, even given this ignorance about SGD's inductive biases.
- (B): (3) is false: we know enough about SGD’s inductive biases to know that it actively favors non-scheming goals over scheming goals.
Let’s start with (A). I agree that this sort of reasoning would lead you to giving significant weight to SGD overfitting, absent any further evidence. But it’s not clear to me that giving this sort of weight to overfitting was unreasonable ex ante, or that having learned that SGD-doesn't-overfit, you should now end up with low p(scheming) even given your ongoing ignorance about SGD's inductive biases.
Thus, consider the sort of analogy I discuss in the counting arguments section. Suppose that all we know is that Bob lives in city X, that he went to a restaurant on Saturday, and that town X has a thousand chinese restaurants, a hundred mexican restaurants, and one indian restaurant. What should our probability be that he went to a chinese restaurant?
In this case, my intuitive answer here is: “hefty.”[1] In particular, absent further knowledge about Bob’s food preferences, and given the large number of chinese restaurants in the city, “he went to a chinese restaurant” seems like a pretty salient hypothesis. And it seems quite strange to be confident that he went to a non-chinese restaurant instead.
Ok but now suppose you learn that last week, Bob also engaged in some non-restaurant leisure activity. For such leisure activities, the city offers: a thousand movie theaters, a hundred golf courses, and one escape room. So it would’ve been possible to make a similar argument for putting hefty credence on Bob having gone to a movie. But lo, it turns out that actually, Bob went golfing instead, because he likes golf more than movies or escape rooms.
How should you update about the restaurant Bob went to? Well… it’s not clear to me you should update much. Applied to both leisure and to restaurants, the hazy counting argument is trying to be fairly agnostic about Bob’s preferences, while giving some weight to some type of “count.” Trying to be uncertain and agnostic does indeed often mean putting hefty probabilities on things that end up false. But: do you have a better proposed alternative, such that you shouldn’t put hefty probability on “Bob went to a chinese restaurant”, here, because e.g. you learned that hazy counting arguments don’t work when applied to Bob? If so, what is it? And doesn’t it seem like it’s giving the wrong answer?
Or put another way: suppose you didn’t yet know whether SGD overfits or not, but you knew e.g. about the various theoretical problems with unrestricted uses of the indifference principle. What should your probability have been, ex ante, on SGD overfitting? I’m pretty happy to say “hefty,” here. E.g., it’s not clear to me that the problem, re: hefty-probability-on-overfitting, was some a priori problem with hazy-counting-argument-style reasoning. For example: given your philosophical knowledge about the indifference principle, but without empirical knowledge about ML, should you have been super surprised if it turned out that SGD did overfit? I don’t think so.
Now, you could be making a different, more B-ish sort of argument here: namely, that the fact that SGD doesn’t overfit actively gives us evidence that SGD’s inductive biases also disfavor schemers. This would be akin to having seen Bob, in a different city, actively seek out mexican restaurants despite there being many more chinese restaurants available, such that you now have active evidence that he prefers mexican and is willing to work for it. This wouldn’t be a case of having learned that bob’s preferences are such that hazy counting arguments “don’t work on bob” in general. But it would be evidence that Bob prefers non-chinese.
I’m pretty interested in arguments of this form. But I think that pretty quickly, they move into the territory of type (II) arguments above: that is, they start to say something like “we learn, from SGD not overfitting, that it prefers models of type X. Non-scheming models are of type X, schemers are not, so we now know that SGD won’t prefer schemers.”
But what is X? I’m not sure your answer (though: maybe it will come in a later post). You could say something like “SGD prefers models that are ‘natural’” – but then, are schemers natural in that sense? Or, you could say “SGD prefers models that behave similarly on the training and test distributions” – but in what sense is a schemer violating this standard? On both distributions, a schemer seeks after their schemer-like goal. I’m not saying you can’t make an argument for a good X, here – but I haven’t yet heard it. And I’d want to hear its predictions about non-scheming forms of goal-misgeneralization as well.
Indeed, my understanding is that a quite salient candidate for “X” here is “simplicity” – e.g., that SGD’s not overfitting is explained by its bias towards simpler functions. And this puts us in the territory of the “simplicity argument” above. I.e., we’re now being less agnostic about SGD’s preferences, and instead positing some more particular bias. But there’s still the question of whether this bias favors schemers or not, and the worry is that it does.
This brings me to your take on simplicity arguments. I agree with you that simplicity arguments are often quite ambiguous about the notion of simplicity at stake (see e.g. my discussion here). And I think they’re weak for other reasons too (in particular, the extra cognitive faff scheming involves seems to me more important than its enabling simpler goals).
But beyond “what is simplicity anyway,” you also offer some other considerations, other than SGD-not-overfitting, meant to suggest that we have active evidence that SGD’s inductive biases disfavor schemers. I’m not going to dig deep on those considerations here, and I’m looking forward to your future post on the topic. For now, my main reaction is: “we have active evidence that SGD’s inductive biases disfavor schemers” seems like a much more interesting claim/avenue of inquiry than trying to nail down the a priori philosophical merits of counting arguments/indifference principles, and if you believe we have that sort of evidence, I think it’s probably most productive to just focus on fleshing it out and examining it directly. That is, whatever their a priori merits, counting arguments are attempting to proceed from a position of lots of uncertainty and agnosticism, which only makes sense if you’ve got no other good evidence to go on. But if we do have such evidence (e.g., if (3) above is false), then I think it can quickly overcome whatever “prior” counting arguments set (e.g., if you learn that Bob has a special passion for mexican food and hates chinese, you can update far towards him heading to a mexican restaurant). In general, I’m very excited for people to take our best current understanding of SGD’s inductive biases (it’s not my area of expertise), and apply it to p(scheming), and am interested to hear your own views in this respect. But if we have active evidence that SGD’s inductive biases point away from schemers, I think that whether counting arguments are good absent such evidence matters way less, and I, for one, am happy to pay them less attention.
(One other comment re: your take on simplicity arguments: it seems intuitively pretty non-simple to me to fit the training data on the training distribution, and then cut to some very different function on the test data, e.g. the identity function or the constant function. So not sure your parody argument that simplicity also predicts overfitting works. And insofar as simplicity is supposed to be the property had by non-overfitting functions, it seems somewhat strange if positing a simplicity bias predicts over-fitting after all.)
A few other comments
Re: goal realism, it seems like the main argument in the post is something like:
- Michael Huemer says that it’s sometimes OK to use the principle of indifference if you’re applying it to explanatorily fundamental variables.
- But goals won’t be explanatorily fundamental. So the principle of indifference is still bad here.
I haven’t yet heard much reason to buy Huemer’s view, so not sure how much I care about debating whether we should expect goals to satisfy his criteria of fundamentality. But I'll flag I do feel like there’s a pretty robust way in which explicitly-represented goals appropriately enter into our explanations of human behavior – e.g., I have buying a flight to New York because I want to go to New York, I have a representation of that goal and how my flight-buying achieves it, etc. And it feels to me like your goal reductionism is at risk of not capturing this. (To be clear: I do think that how we understand goal-directedness matters for scheming -- more here -- and that if models are only goal-directed in a pretty deflationary sense, this makes scheming a way weirder hypothesis. But I think that if models are as goal-directed as strategic and agentic humans reasoning about how to achieve explicitly represented goals, their goal-directedness has met a fairly non-deflationary standard.)
I’ll also flag some broader unclarity about the post’s underlying epistemic stance. You rightly note that the strict principle of indifference has many philosophical problems. But it doesn’t feel to me like you’ve given a compelling alternative account of how to reason “on priors” in the sorts of cases where we’re sufficiently uncertain that there’s a temptation to spread one’s credence over many possibilities in the broad manner that principles-of-indifference-ish reasoning attempts to do.
Thus, for example, how does your epistemology think about a case like “There are 1000 people in this town, one of them is the murderer, what’s the probability that it’s Mortimer P. Snodgrass?” Or: “there are a thousand white rooms, you wake up in one of them, what’s the probability that it’s room number 734?” These aren’t cases like dice, where there’s a random process designed to function in principle-of-indifference-ish ways. But it’s pretty tempting to spread your credence out across the people/rooms (even if in not-fully-uniform ways), in a manner that feels closely akin to the sort of thing that principle-of-indifference-ish reasoning is trying to do. (We can say "just use all the evidence available to you" -- but why should this result in such principle-of-indifference-ish results?)
Your critique of counting argument would be more compelling to me if you had a fleshed out account of cases like these -- e.g., one which captures the full range of cases where we’re pulled towards something principle-of-indifference-ish, such that you can then take that account and explain why it shouldn’t point us towards hefty probabilities on schemers, a la the hazy counting argument, even given very-little-evidence about SGD’s inductive biases.
More to say on all this, and I haven't covered various ways in which I'm sympathetic to/moved by points in the vicinity of the ones you're making here. But for now: thanks again for writing, looking forward to future installments.
- ^
Though I do think cases like this can get complicated, and depending on how you carve up the hypothesis space, in some versions "hefty" won't be the right answer.
(Partly re-hashing my response from twitter.)
I'm seeing your main argument here as a version of what I call, in section 4.4, a "speed argument against schemers" -- e.g., basically, that SGD will punish the extra reasoning that schemers need to perform.
(I’m generally happy to talk about this reasoning as a complexity penalty, and/or about the params it requires, and/or about circuit-depth -- what matters is the overall "preference" that SGD ends up with. And thinking of this consideration as a different kind of counting argument *against* schemers seems like it might well be a productive frame. I do also think that questions about whether models will be bottlenecked on serial computation, and/or whether "shallower" computations will be selected for, are pretty relevant here, and the report includes a rough calculation in this respect in section 4.4.2 (see also summary here).)
Indeed, I think that maybe the strongest single argument against scheming is a combination of
- "Because of the extra reasoning schemers perform, SGD would prefer non-schemers over schemers in a comparison re: final properties of the models" and
- "The type of path-dependence/slack at stake in training is such that SGD will get the model that it prefers overall."
My sense is that I'm less confident than you in both (1) and (2), but I think they're both plausible (the report, in particular, argues in favor of (1)), and that the combination is a key source of hope. I'm excited to see further work fleshing out the case for both (including e.g. the sorts of arguments for (2) that I took you and Nora to be gesturing at on twitter -- the report doesn't spend a ton of time on assessing how much path-dependence to expect, and of what kind).
Re: your discussion of the "ghost of instrumental reasoning," "deducing lots of world knowledge 'in-context,' and "the perspective that NNs will 'accidentally' acquire such capabilities internally as a convergent result of their inductive biases" -- especially given that you only skimmed the report's section headings and a small amount of the content, I have some sense, here, that you're responding to other arguments you've seen about deceptive alignment, rather than to specific claims made in the report (I don't, for example, make any claims about world knowledge being derived "in-context," or about models "accidentally" acquiring flexible instrumental reasoning). Is your basic thought something like: sure, the models will develop flexible instrumental reasoning that could in principle be used in service of arbitrary goals, but they will only in fact use it in service of the specified goal, because that's the thing training pressures them to do? If so, my feeling is something like: ok, but a lot of the question here is whether using the instrumental reasoning in service of some other goal (one that backchains into getting-reward) will be suitably compatible with/incentivized by training pressures as well. And I don't see e.g. the reversal curse as strong evidence on this front.
Re: "mechanistically ungrounded intuitions about 'goals' and 'tryingness'" -- as I discuss in section 0.1, the report is explicitly setting aside disputes about whether the relevant models will be well-understood as goal-directed (my own take on that is in section 2.2.1 of my report on power-seeking AI here). The question in this report is whether, conditional on goal-directedness, we should expect scheming. That said, I do think that what I call the "messyness" of the relevant goal-directedness might be relevant to our overall assessment of the arguments for scheming in various ways, and that scheming might require an unusually high standard of goal-directedness in some sense. I discuss this in section 2.2.3, on "'Clean' vs. 'messy' goal-directedness," and in various other places in the report.
Re: "long term goals are sufficiently hard to form deliberately that I don't think they'll form accidentally" -- the report explicitly discusses cases where we intentionally train models to have long-term goals (both via long episodes, and via short episodes aimed at inducing long-horizon optimization). I think scheming is more likely in those cases. See section 2.2.4, "What if you intentionally train the model to have long-term goals?" That said, I'd be interested to see arguments that credit assignment difficulties actively count against the development of beyond-episode goals (whether in models trained on short episodes or long episodes) for models that are otherwise goal-directed. And I do think that, if we could be confident that models trained on short episodes won't learn beyond-episode goals accidentally (even irrespective of mundane adversarial training -- e.g., that models rewarded for getting gold coins on the episode would not learn a goal that generalizes to caring about gold coins in general, even prior to efforts to punish it for sacrificing gold-coins-on-the-episode for gold-coins-later), that would be a significant source of comfort (I discuss some possible experimental directions in this respect in section 6.2).
I agree that AIs only optimizing for good human ratings on the episode (what I call "reward-on-the-episode seekers") have incentives to seize control of the reward process, that this is indeed dangerous, and that in some cases it will incentivize AIs to fake alignment in an effort to seize control of the reward process on the episode (I discuss this in the section on "non-schemers with schemer-like traits"). However, I also think that reward-on-the-episode seekers are also substantially less scary than schemers in my sense, for reasons I discuss here (i.e., reasons to do with what I call "responsiveness to honest tests," the ambition and temporal scope of their goals, and their propensity to engage in various forms of sandbagging and what I call "early undermining"). And this especially for reward-on-the-episode seekers with fairly short episodes, where grabbing control over the reward process may not be feasible on the relevant timescales.
Agree that it would need to have some conception of the type of training signal to optimize for, that it will do better in training the more accurate its picture of the training signal, and that this provides an incentive to self-locate more accurately (though not necessary to degree at stake in e.g. knowing what server you're running on).
The question of how strongly training pressures models to minimize loss is one that I isolate and discuss explicitly in the report, in section 1.5, "On 'slack' in training" -- and at various points the report references how differing levels of "slack" might affect the arguments it considers. Here I was influenced in part by discussions with various people, yourself included, who seemed to disagree about how much weight to put on arguments in the vein of: "policy A would get lower loss than policy B, so we should think it more likely that SGD selects policy A than policy B."
(And for clarity, I don't think that arguments of this form always support expecting models to do tons of reasoning about the training set-up. For example, as the report discusses in e.g. Section 4.4, on "speed arguments," the amount of world-modeling/instrumental-reasoning that the model does can affect the loss it gets via e.g. using up cognitive resources. So schemers -- and also, reward-on-the-episode seekers -- can be at some disadvantage, in this respect, relative to models that don't think about the training process at all.)
That seems like a useful framing to me. I think the main issue is just that often, we don't think of commitment as literally closing off choice -- e.g., it's still a "choice" to keep a promise. But if you do think of it as literally closing off choice then yes, you can avoid the violation of Guaranteed Payoffs, at least in cases where you've actually already made the commitment in question.