I run the White Box Evaluations Team at the UK AI Security Institute. This is primarily a mechanistic interpretability team focussed on estimating and addressing risks associated with deceptive alignment. I'm a MATS 5.0 and ARENA 1.0 Alumni. Previously, I cofounded the AI Safety Research Infrastructure Org Decode Research and conducted independent research into mechanistic interpretability of decision transformers. I studied computational biology and statistics at the University of Melbourne in Australia.
Posts
Wikitag Contributions
- MSE Losses were in the WandB report (screenshot below).
- I've loaded in your weights for one SAE and I get very bad performance (high L0, high L1, and bad MSE Loss) at first.
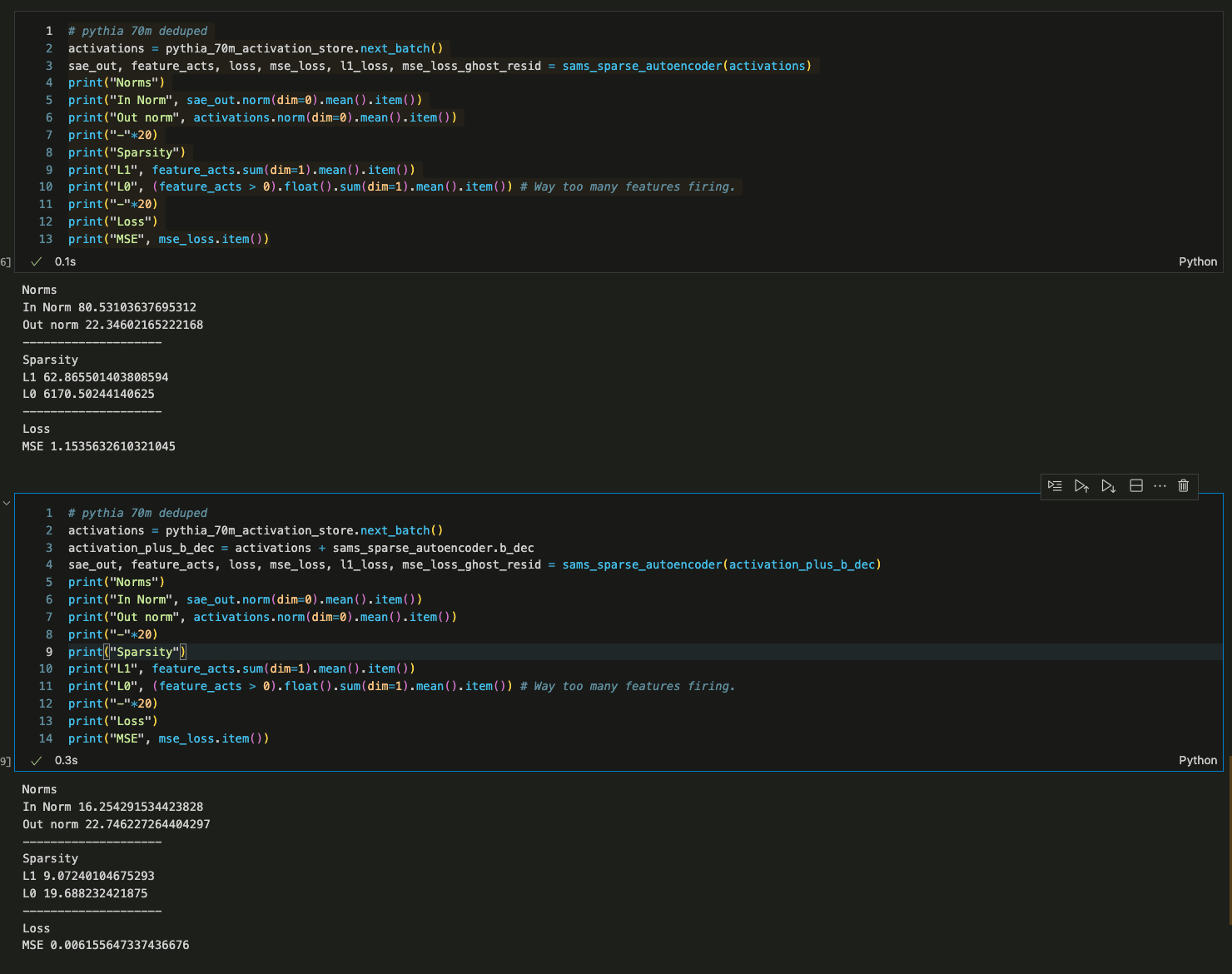
- It turns out that this is because my forward pass uses a tied decoder bias which is subtracted from the initial activations and added as part of the decoder forward pass. AFAICT, you don't do this.
- To verify this, I added the decoder bias to the activations of your SAE prior to running a forward pass with my code (to effectively remove the decoder bias subtraction from my method) and got reasonable results.
- I've screenshotted the Towards Monosemanticity results which describes the tied decoder bias below as well.
I'd be pretty interested in knowing if my SAEs seem good now based on your evals :) Hopefully this was the only issue.
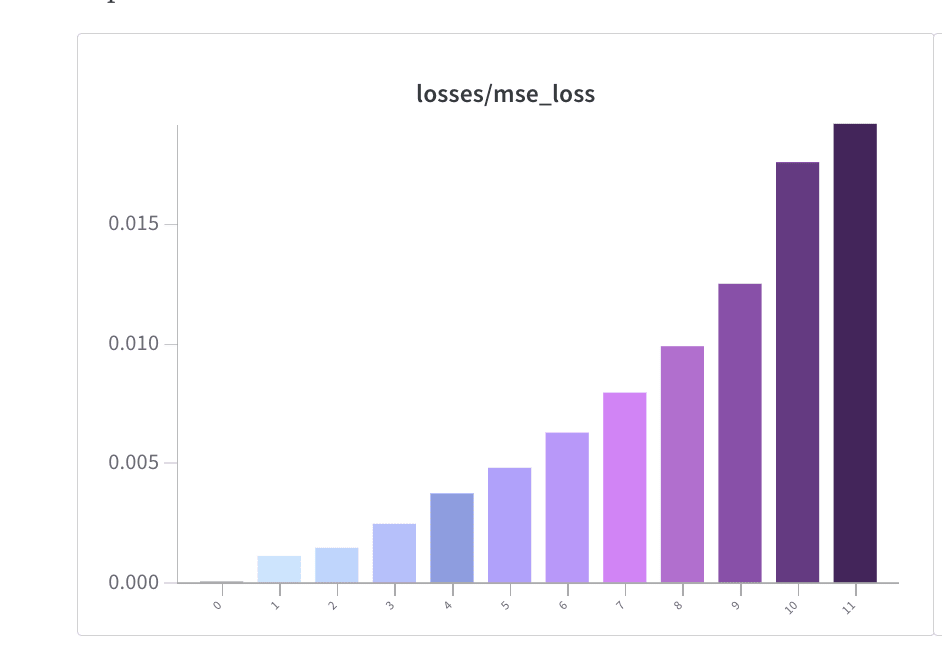

I've run some of the SAE's through more thorough eval code this morning (getting variance explained with the centring and calculating mean CE losses with more batches). As far as I can tell the CE loss is not that high at all and the MSE loss is quite low. I'm wondering whether you might be using the wrong hooks? These are resid_pre so layer 0 is just the embeddings and layer 1 is after the first transformer block and so on. One other possibility is that you are using a different dataset? I trained these SAEs on OpenWebText. I don't much padding at all, that might be a big difference too. I'm curious to get to the bottom of this.
One sanity check I've done is just sampling from the model when using the SAE to reconstruct activations and it seems to be about as good, which I think rules out CE loss in the ranges you quote above.
For percent alive neurons a batch size of 8192 would be far too few to estimate dead neurons (since many neurons have a feature sparsity < 10**-3.
You're absolutely right about missing the centreing in percent variance explained. I've estimated variance explained again for the same layers and get very similar results to what I had originally. I'll make some updates to my code to produce CE score metrics that have less variance in the future at the cost of slightly more train time.
If we don't find a simple answer I'm happy to run some more experiments but I'd guess an 80% probability that there's a simple bug which would explain the difference in what you get. Rank order of most likely: Using the wrong activations, using datapoints with lots of padding, using a different dataset (I tried the pile and it wasn't that bad either).
Oh no. I'll look into this and get back to you shortly. One obvious candidate is that I was reporting CE for some batch at the end of training that was very small and so the statistics likely had high variance and the last datapoint may have been fairly low. In retrospect I should have explicitly recalculated this again post training. However, I'll take a deeper dive now to see what's up.
My vibe from this post is something like "we're making on stuff that could be helpful so there's stuff to work on!" and this is a vibe I like. However, I suspect that for people who might not be as excited about these approaches, you're likely not touching on important cruxes (eg: do these approaches really scale? Are some agendas capabilities enhancing? Will these solve deceptive alignment or just corrigible alignment?)
I also think that if the goal is to actually make progress and not to maximize the number of people making progress or who feel like they're making progress, then engaging with those cruxes is important before people invest substantive energy (ie: beyond upskilling). However as a directional update for people who are otherwise pretty cynical, this seems like a good update.
Really exciting! I added a version of AVEC to my interpretability tool for gridworld agents and am keen to explore it more. I really like that the injection coefficient has a scalar and this had enabled me to do what I can "an injection coefficient scan".
The procedure I'm using looks like this:
- Repeat your input tokens say, 128 times.
- Apply the activation vector at 128 different steps between a coefficient of -10 and 10 to each of your input tokens when doing your AVEC forward pass.
- Decompose the resulting residual stream to whatever granularity you like (use decompose_resid or get_full_resid_decomposition with/without expand neurons).
- Dot product the outputs with your logit direction of choice ( I use a logit diff that is meaningful in my task)
- Plot the resulting attribution vs injection coefficient per component.
- If you like, cluster the profiles to show how different component learn similar functions of the injection coefficient to your decision.
So far, my results seem very interesting and possibly quite useful. It's possible this method is impractical in LLMs but I think it might be fine as well. Will dm some example figures.
I also want to investigate using a continuous injection coefficient in activation patching is similarly useful since it seems like it might be.
I am very excited to see if this makes my analyses easier! Great work!
We would love to see more ideas & hypotheses on why the model might be doing this, as well as attempts to test this! We mainly wrote-up this post because both Alex and I independently noticed this and weren't aware of this previously, so we wanted to make a reference post.
Happy to provide! I think I'm pretty interested in testing this/working on this in the future. Currently a bit tied up but I think (as Alex hints at) there could be some big implications for interpretability here.
TLDR: Documenting existing circuits is good but explaining what relationship circuits have to each other within the model, such as by understanding how the model allocated limited resources such as residual stream and weights between different learnable circuit seems important.
The general topic I think we are getting at is something like "circuit economics". The thing I'm trying to gesture at is that while circuits might deliver value in distinct ways (such as reducing loss on different inputs, activating on distinct patterns), they share capacity in weights (see polysemantic and capacity in neural networks) and I guess "bandwidth" (getting penalized for interfering signals in activations). There are a few reasons why I think this feels like economics which include: scarce resources, value chains (features composed of other features) and competition (if a circuit is predicting something well with one heuristic, maybe there will be smaller gradient updates to encourage another circuit learning a different heuristic to emerge).
So to tie this back to your post and Alex's comment "which seems like it would cut away exponentially many virtual heads? That would be awfully convenient for interpretability.". I think that what interpretability has recently dealt with in elucidating specific circuits is something like "micro-interpretability" and is akin to microeconomics. However this post seems to show a larger trend ie "macro-interpretability" which would possibly affect which of such circuits are possible/likely to be in the final model.
I'll elaborate briefly on the off chance this seems like it might be a useful analogy/framing to motivate further work.
- Studying the Capacity/Loss Reduction distribution in Time: It seems like during transformer training there may be an effect not unlike inflation? Circuits which delivered enough value to justify their capacity use early in training may fall below the capacity/loss reduction cut off later. Maybe various techniques which enable us to train more robust models work because they make these transitions easier.
- Studying the Capacity/Loss Reduction distribution in Layer: Moreover, it seems plausible that the distribution of "usefulness" in circuits in different layers of the network may be far from uniform. Circuits later in the network have far more refined inputs which make them better at reducing loss. Residual stream norm growth seems like a "macro" effect that shows model "know" that later layers are more important.
- Studying the Capacity/Loss Reduction distribution in Layer and Time: Combining the above. I'd predict that neural networks originally start by having valuable circuits in many layers but then transition to maintain circuits earlier in the network which are valuable to many downstream circuits and circuits later in the network which make the best use of earlier circuits.
- More generally "circuit economics" as a framing seems to suggest that there are different types of "goods" in the transformer economy. those which directly lead to better predictions and those which are useful for making better predictions when integrated with other features. The success of Logit Lens seems to suggest that the latter category increases over the course of the layers. Maybe this is the only kind of good in which case transformers would be "fundamentally interpretable" in some sense. All intermediate signals could be interpreted as final products. More likely, I think is that later in training there are ways to reinforce the creation of more internal goods (in economics, good which are used to make other goods are called capital goods). The value of such goods would be mediated via later circuits. So this would lead also to the "deletion-by-magnitude theory" as a way or removing internal goods.
- To bring this back to language already in the field see Neel's discussion here. A modular circuit is distinct from an end-end circuit in that it starts and ends in intermediate activations. Modular circuits may be composable. I propose that the outputs of such circuits are "capital goods". If we think about the "circuit economy" it then seems totally reasonable that multiple suppliers might generate equivalent capital goods and have a many to many relationship multiple different circuits near the end voting on logits.
This is very speculative "theory" if you can call it that, but I guess I feel this would be "big if true". I also make no claims about this being super original or actually that useful in practice but it does feel intuition generating. I think this is totally the kind of thing people might have worked on sooner but it's likely been historically hard to measure the kinds of things that might be relevant. What your post shows is that between the transformer circuits framework and TransformerLens we are able to somewhat quickly take a bunch of interesting measurements relatively quickly which may provide more traction on this than previously possible.
Second pass through this post which solidly nerd-sniped me!
A quick summary of my understand of the post: (intentionally being very reductive though I understand the post may make more subtle points).
- There appears to be exponential growth in the norm of the residual stream in a range of models. Why is this the case?
- You consider two hypotheses:
- 1. That the parameters in the Attention and/or MLP weights increase later in the network.
- 2. That there is some monkey business with the layer norm sneaking in a single extra feature.
- In terms of evidence, you found that:
- Evidence for theory one in W_OV frobenius norms increasing approximately exponential over layers.
- Evidence for theory one in MLP output to the residual stream increasing (harder to directly measure the norm of the MLP due to non-linearities).
- You're favoured explanation is "We finally note our current favored explanation: Due to LayerNorm, it's hard to cancel out existing residual stream features, but easy to overshadow existing features by just making new features 4.5% larger. "
My thoughts:
- My general take is that this post is that the explanation about cancelling out features being harder than amplifying new features feels somewhat disconnected from the high level characterisation of weights / norms which makes up most of the post. It feels like there is a question of how and a question of why.
- Given these models are highly optimized by SGD, it seems like the conclusion must be that the residual stream norm is growing because this is useful leading to the argument that it is useful because the residual stream is a limited resource / has limited capacity, making us want to delete information in it and increasing the norm of the contributions to the residual stream effectively achieves this by drowning out other features.
- Moreover, if the mechanism by which we achieve larger residual stream contributions in later components is by having larger weights (which is penalized by weight decay) then we should conclude that a residual stream with a large norm is worthwhile enough that the model would rather do this then have smaller weights (which you note).
- I feel like I still don't feel like I know why though. Later layers have more information and are therefore "wiser" or something could be part of it.
- I'd also really like to know the implications of this. Does this affect the expressivity of the model in a meaningful way? Does it affect the relative value of representing a feature in any given part of the model? Does this create an incentive to "relocate" circuits during training or learn generic "amplification" functions? These are all ill-defined questions to some extent but maybe there are formulations of them that are better defined which have implications for MI related alignment work.
Thanks for writing this up! Looking forward to subsequent post/details :)
PS: Is there are non-trivial relationship between this post and tuned lens/logit lens? https://arxiv.org/pdf/2303.08112.pdf Seems possible.
Thank you for letting me know about your work on procgen with MI. It sounds like you're making progress, particularly I'd be interested in your visualisation techniques (how do they compare to what was done in Understanding RL Vision?) and the reproduction of the cheese-maze policies (is this tricky? Do you think a DT could be well-calibrated on this problem?).
Some questions that might be useful to discuss more:
- What are the pros/cons of doing DT vs actor-critic MI? (You're using Actor-Critic of some form?). It could also be interesting to study analogous circuits in the DT vs AC scenarios.
- I haven't done anything with CNNs yet, for simplicity, but I might be able to calibrate my expectations on the value/challenges involved by chatting to the team shard MATS stream.
Glad to hear your progress is going well! I'll be in the Bay Area for EAG if anyone from the team would like to chat.
Ahhh I see. Sorry I was way too hasty to jump at this as the explanation. Your code does use the tied decoder bias (and yeah, it was a little harder to read because of how your module is structured). It is strange how assuming that bug seemed to help on some of the SAEs but I ran my evals over all your residual stream SAE's and it only worked for some / not others and certainly didn't seem like a good explanation after I'd run it on more than one.
I've been talking to Logan Riggs who says he was able to load in my SAEs and saw fairly similar reconstruction performance to to me but that outside of the context length of 128 tokens, performance markedly decreases. He also mentioned your eval code uses very long prompts whereas mine limits to 128 tokens so this may be the main cause of the difference. Logan mentioned you had discussed this with him so I'm guessing you've got more details on this than I have? I'll build some evals specifically to look at this in the future I think.
Scientifically, I am fairly surprised about the token length effect and want to try training on activations from much longer context sizes now. I have noticed (anecdotally) that the number of features I get sometimes increases over the prompt so an SAE trained on activations from shorter prompts are plausibly going to have a much easier time balancing reconstruction and sparsity, which might explain the generally lower MSE / higher reconstruction. Though we shouldn't really compare between models and with different levels of sparsity as we're likely to be at different locations on the pareto frontier.
One final note is that I'm excited to see whether performance on the first 128 tokens actually improves in SAEs trained on activations from > 128 token forward passes (since maybe the SAE becomes better in general).