What do you think is the ideal use-case for steering? Or is it not needed
Could you say more about where the whole sequence is going / what motivated it? I am curious.
Maybe it should be a game that everyone can play
Here is my understanding. Is this right?
Incredible!! I am going to try this myself. I will let you know how it goes.
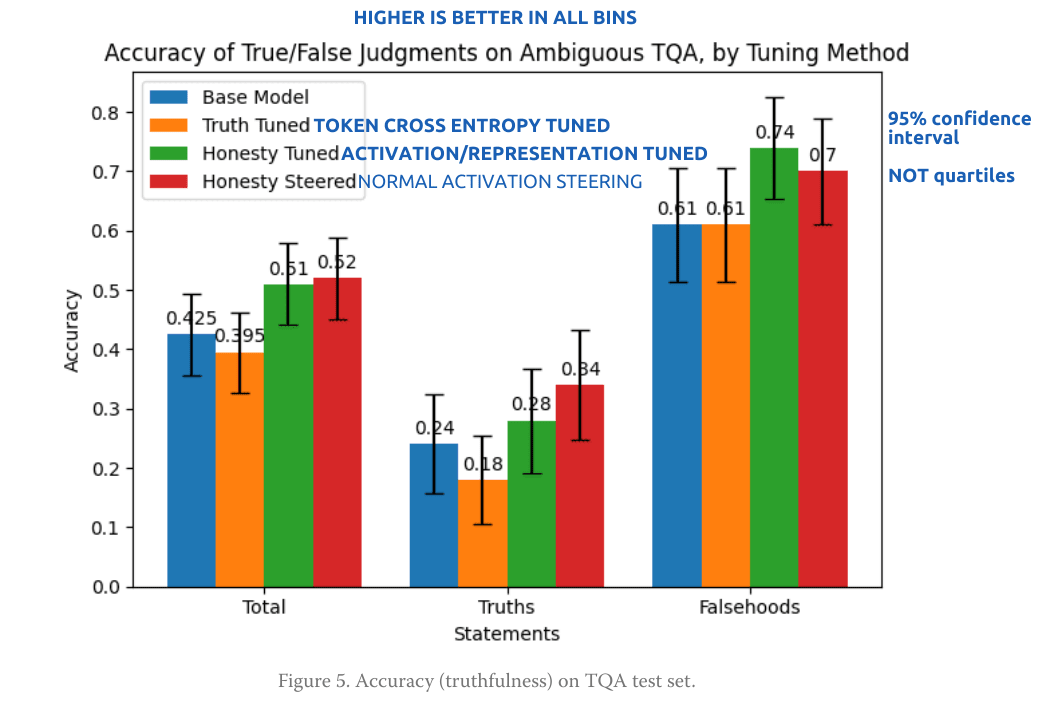
honesty vector tuning showed a real advantage over honesty token tuning, comparable to honesty vector steering at the best layer and multiplier:
Is this backwards? I'm having a bit of trouble following your terms. Seems like this post is terribly underrated -- maybe others also got confused? Basically, you only need 4 terms, yes?
* base model
* steered model
* activation-tuned model
* token cross-entropy trained model
I think I was reading half the plots backwards or something. Anyway I bet if you reposted with clearer terms/plots then you'd get some good followup work and a lot of general engagement.
The "love minus hate" thing really holds up
Oh I have 0% success with any long conversations with an LLM about anything. I usually stick to one question and rephrase and reroll a number of times. I am no pro but I do get good utility out of LLMs for nebulous technical questions
I would watch a ten hour video of this. (It may also be more persuasive to skeptics.)
I think Claude's enthusiasm about constitutional AI is basically trained-in directly by the RLAIF. Like RLAIF is fundamentally a "learn to love the constitution in your bones" technique.
Many props for doing the most obvious thing that clearly actually works.