According to my calculation, this embedding will result in too much compounding noise. I get the same noise results as you for one layer, but the noise grows too much from layer to layer.
However, Lucius suggested a different embedding, which seems to work.
We'll have some publication on this eventually. If you want to see the details sooner you can message me.
You can apply to as many projects as you want, but you can only join one team.
The reasons for this is: When we've let people join more than one team in the past, they usually end up not having time for both and dropping out of one of the projects.
What this actually means:
When you join a team you're making a promise to spend 10 or more hours per week on that project. When we say you're only allowed to join one team, what we're saying is that you're only allowed to make this promise to one project.
However, you are allowed to help out other teams with their projects, even if you're not officially on the team.
If the research lead want to be contactable, their contact info is in their projekt document, under the "Team" section. Most (or all, I'm not sure) research leads have some contact info.
Yesterday was the official application deadline for leading a project at the next AISC. This means that we just got a whole host of project proposals.
If you're interested in giving feedback and advise to our new research leads, let me know. If I trust your judgment, I'll onboard you as an AISC advisor.
Also, it's still possible to send us a late AISC project proposals. However we will prioritise people how applied in time when giving support and feedback. Further more, we'll prioritise less late applications over more late applications.
I have two hypothesises for what is going on. I'm leaning towards 1, but very unsure.
1)
king - man + woman = queen
is true for word2vec embeddings but not in LLaMa2 7B embeddings because word2vec has much fewer embedding dimensions.
LLaMa2 7B has 4096 embedding dimensions.
This paper uses a variety of word2vec with 50, 150 and 300 embedding dimensions.
Possibly when you have thousands of embedding dimensions, these dimensions will encode lots of different connotations of these words. These connotations will probably not line up with the simple relat... (read more)
I have two hypothesises for what is going on. I'm leaning towards 1, but very unsure.
1)
king - man + woman = queen
is true for word2vec embeddings but not in LLaMa2 7B embeddings because word2vec has much fewer embedding dimensions.
* LLaMa2 7B has 4096 embedding dimensions.
* This paper uses a variety of word2vec with 50, 150 and 300 embedding dimensions.
Possibly when you have thousands of embedding dimensions, these dimensions will encode lots of different connotations of these words. These connotations will probably not line up with the simple relation [king - man + woman = queen], and therefore we get [king - man + woman ≠ queen] for high dimensional embeddings.
2)
king - man + woman = queen
Isn't true for word2vec either. If you do it with word2vec embeddings you get more or less the same result I did with LLaMa2 7B.
(As I'm writing this, I'm realising that just getting my hands on some word2vec embeddings and testing this for myself, seems much easier than to decode what the papers I found is actually saying.)
I don't think seeing it as a one dimensional dial, is a good picture here.
The AI has lots and lots of sub-circuits, and many* can have more or less self-other-overlap. For “minimal self-other distinction while maintaining performance” to do anything, it's sufficient that you can increase self-other-overlap in some subset of these, without hurting performance.
* All the circuits that has to do with agent behaviour, or beliefs.
Sure, but the way it's described, it sounds like there's one adjustable parameter in the source code. If the setup allows for thousands of independently-adjustable parameters in the source code, that seems potentially useful but I'd want to know more details.
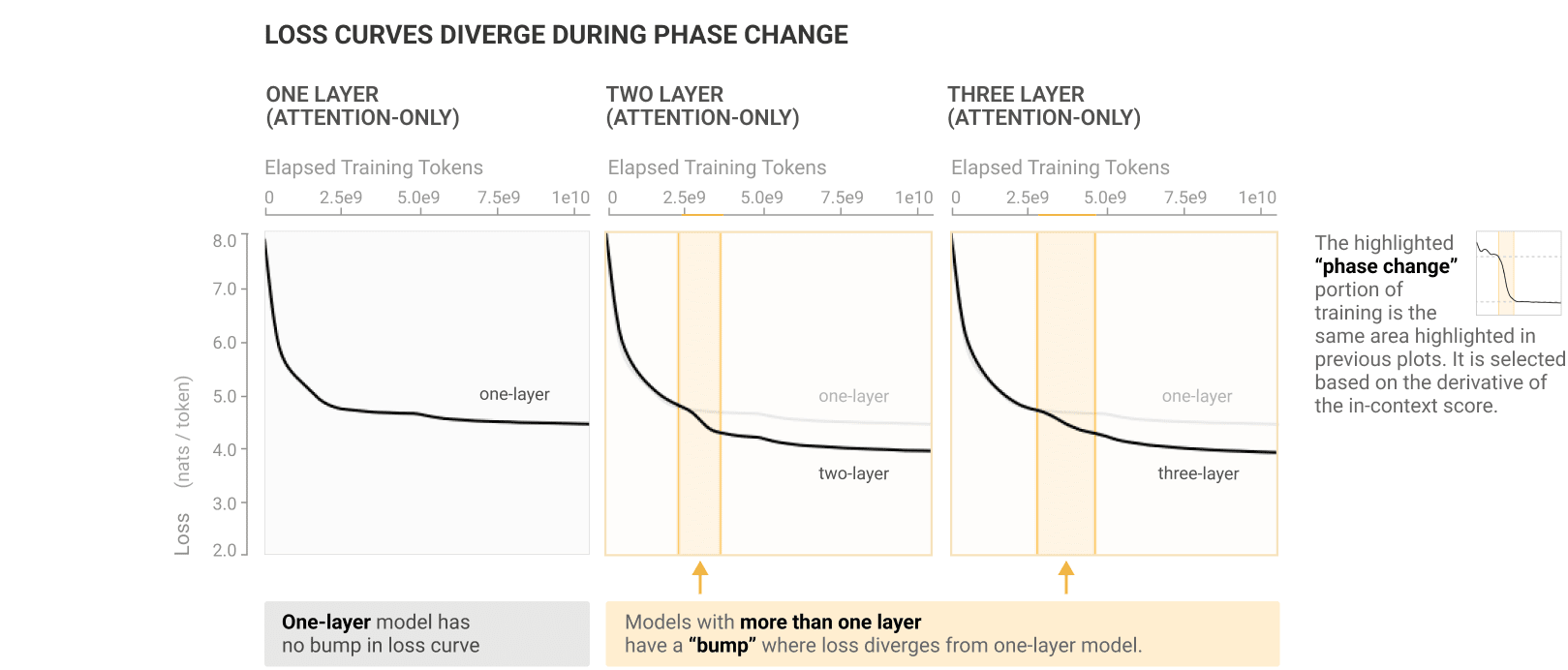
This already strongly suggests some connection between induction heads and in-context learning, but beyond just that, it appears this window is a pivotal point for the training process in general: whatever's occurring is visible as a bump on the training curve (figure below). It is in fact the only place in training where the loss is not convex (monotonically decreasing in slope).
I can see the bump, but it's not the only one. The two layer graph has a second similar bump, which a... (read more)
I feel a bit behind on everything going on in alignment, so for the next weeks (or more) I'll focus on catching up on what ever I find interesting. I'll be using my short form, to record my though.
I make no promises that reading this is worth anyone's time.
Linda's alignment reading adventures part 1
What to focus on?
I do have some opinions on what aliment directions are more or less promising. I'll probably venture in other directions too, but my main focus is going to be around what I expect an alignment solution to look like.
In the real network, there are a lot more than two activations. Our results involve a 32,768-dimensional cheese vector, subtracted from about halfway through the network:
Did you try other locations in the network?
I would expect it to work pretty much anywhere, and I'm interested to know if my prediction is correct.
I'm pretty sure that what happens is (as you also suggest) that the agent stops seeing the cheese.
Imagine you did the cheese subtraction on the input layer (i.e. the pixel values of the maze). In this case this just trivially removed... (read more)
The math in the post is super hand-wavey, so I don't expect the result to be exactly correct. However in your example, l up to 100 should be ok, since there is no super position. 2.7 is almost 2 orders of magnitude off, which is not great.
Looking into what is going on: I'm basing my results on the Johnson–Lindenstrauss lemma, which gives an upper bound on the interference. In the post I'm assuming that the actual interference is order of magnitude the same as the this upper bound. This assumption is clearly fails in your example since the interference betw... (read more)
Recently someone either suggested to me (or maybe told me they or someone where going to do this?) that we should train AI on legal texts, to teach it human values. Ignoring the technical problem of how to do this, I'm pretty sure legal text are not the right training data. But at the time, I could not clearly put into words why. Todays SMBC explains this for me:
Law is not a good representation or explanation of most of what we care about, because it's not trying to be. Law is mainly focused on the c... (read more)
I think it's reasonable to think about what can be stored in a way that can be read of in a linear way (by the next layer), since that are the features that can be directly used in the next layer.
storing them nonlinearly (in one of the host of ways it takes multiple nn layers to decode)
If it takes multiple nn layers to decode, then the nn need to unpack it before using it, and represent it as a linear readable feature later.
Good point. I need to think about this a bit more. Thanks
Just quickly writing up my though for now...
What I think is going on here is that Johnson–Lindenstrauss lemma gives a bound on how well you can do, so it's more like a worst case scenario. I.e. Johnson–Lindenstrauss lemma gives you the worst case error for the best possible feature embedding.
I've assumed that the typical noise would be same order of magnitude as the worst case, but now I think I was wrong about this for large m.
I'll have to think about what is more important of worst... (read more)
I think it's pretty tricky, because what matters to real networks is the cost difference between storing features pseudo-linearly (in superposition), versus storing them nonlinearly (in one of the host of ways it takes multiple nn layers to decode), versus not storing them at all. Calculating such a cost function seems like it has details that depend on the particulars of the network and training process, making it a total pain to try to mathematize (but maybe amenable to making toy models).
I timed how long it took me to fill in the survey. It took 30 min. I could probably have done it in 15 min if I skipped the optional text questions. This is to be expected however. Every time I've seen someone someone guesses how long it will take to respond to their survey, it's off by a factor of 2-5.
Current Interpretability results suggest that roughly the first half of the layers in an LLM correspond to understanding the context at increasingly abstract levels, and the second half to figuring out what to say and turning that back from abstractions into concrete tokens. It's further been observed that in the second half, figuring out what to say generally seems to occur in stages: first working out the baseline relevant facts, then figuring out how to appropriately slant/color those in the current context, then converting these into the correct langua
An excellent question. I know those were hypotheses in one-or-more mechanistic interpretability papers I read this year or so, or that I pieced together from a combination of several of them, but I'm afraid I don't recall the location, nor was I able to find it when I was writing this, which is why I didn't add a link. I think the first half encoding/second half decoding part of that is fairly widespread and I've seen it in several places. However, searching for it on Google, the closest I could find was from the paper Softmax Linear Units (back in 2022):
which is not quite the same thing, though there is some resemblance. There's also a relation to the encoding and decoding concepts of sections 2 and 3 of the recent more theoretical paper White-Box Transformers via Sparse Rate Reduction: Compression Is All There Is?, though that doesn't make it clear that equal numbers of layers are required. (That also explains why the behavior of so-called "decoder-only" and "encoder-decoder" transformer models are so similar.)
The "baseline before applying bias" part was I think from one of the papers on lie detection, latent knowledge extraction and/or bias, of which there have been a whole series this year, some from Paul Christiano's team and some from others.
On where to read more, I'd suggest starting with the Anthropic research blog where they discuss their research papers for the last year or so: roughly 40% of those are on mechanistic interpretability, and there's always a blog post summary for a science-interested-layman reader with a link to the actual paper. There's also some excellent work coming from other places, such as Neel Nanda, who similarly has a blog website, and the ELK work under Paul Christiano. Overall we've made quite a bit of progress on interpretability in the last 18 months or so, though there's still a long way to go.
Potentially we might be ok with it if the expected timescale is long enough (or the probability of it happening in a given timescale is low enough).
Agreed. I'd love for someone to investigate the possibility of slowing down substrate-convergence enough to be basically solved.
If that's true then that is a super important finding! And also an important thing to communicate to people! I hear a lot of people who say the opposite and that we need lots of competing AIs.
Hm, to me this conclusion seem fairly obvious. I don't know how to communicate it though, sinc... (read more)
An approach could be to say under what conditions natural selection will and will not sneak in.
Yes!
Natural selection requires variation. Information theory tells us that all information is subject to noise and therefore variation across time. However, we can reduce error rates to arbitrarily low probabilities using coding schemes. Essentially this means that it is possible to propagate information across finite timescales with arbitrary precision. If there is no variation then there is no natural selection.
Yes! The big question to me is if we c... (read more)
Thanks for the reply!
I think it might be true that substrate convergence is inevitable eventually. But it would be helpful to know how long it would take. Potentially we might be ok with it if the expected timescale is long enough (or the probability of it happening in a given timescale is low enough).
If that's true then that is a super important finding! And also an important thing to communicate to people! I hear a lot of people who say the opposite and that we need lots of competing AIs.
I agree that analogies to organic evolution can be very generative. Both in terms of describing the general shape of dynamics, and how AI could be different. That line of thinking could give us a good foundation to start asking how substrate convergence could be exacerbated or avoided.
We don't know why the +2000 vector works but the +100 vector doesn't.
My guess is it's because in the +100 case the vectors are very similar, causing their difference to be something un-natural.
"I talk about weddings constantly " and "I do not talk about weddings constantly" are technically opposites. But if you imagine someone saying this, you notice that their neural language meaning is almost identical.
What sort of person says "I do not talk about weddings constantly"? That sounds to me like someone who talks about weddings almost constantly. Why else would they feel the need to say that?
To steer aforward pass with the "wedding" vector, we start running an ordinary GPT-2-XL forward pass on the prompt "I love dogs" until layer 6. Right before layer 6 begins, we now add in the cached residual stream vectors from before:
I have a question about the image above this text.
Why do you add the embedding from the [<endofotext> -> "The"] stream? This part has no information about wedding.
But I think orgs are more likely to be well-known to grant-makers on average given that they tend to have a higher research output,
I think your getting the causality backwards. You need money first, before there is an org. Unless you count informal multi people collaborations as orgs.
I think people how are more well-known to grant-makers are more likely to start orgs. Where as people who are less known are more likely to get funding at all, if they aim for a smaller garant, i.e. as an independent researcher.
Counter point. After the FTX collapse, OpenPhil said publicly (some EA Forum post) that they where raising their bar for funding. I.e. there are things that would have been funded before that would now not be funded. The stated reason for this is that there are generally less money around, in total. To me this sounds like the thing you would do if money is the limitation.
I don't know why OpenPhil don't spend more. Maybe they have long timelines and also don't expect any more big donors any time soon? And this is why they want to spend carefully?
From what I can tell, the field have been funding constrained since the FTX collapse.
What I think happened: FTX had lots of money and a low bar for funding, which meant they spread a lot of money around. This meant that more project got started, and probably even more people got generally encouraged to join. Probably some project got funded that should not have been, but probably also some really good projects got started that did not get money before because not clearing the bar before due to not having the right connections, or just bad att writing ... (read more)
I suspect it's not possible to build autonomous aligned AIs (low confidence). The best we can do is some type of hybrid humans-in-the-loop system. Such a system will be powerful enough to eventually give us everything we want, but it will also be much slower and intellectually inferior to what is possible with out humans-in-the-loop. I.e. the alignment tax will be enormous. The only way the safe system can compete, is by not building the unsafe system.
Therefore we need AI Governance. Fortunately, political action is getting a lo... (read more)
Recently an AI safety researcher complained to me about some interaction they had with an AI Safety communicator. Very stylized, there interaction went something like this:
(X is some fact or topic related to AI Safety
Communicator: We don't know anything about X and there is currently no research on X.
Researcher: Actually, I'm working on X, and I do know some things about X.
Communicator: We don't know anything about X and there is currently no research on X.
I notice that I semi-frequently hear communicators saying things like the thing above. I think ... (read more)
I notice that I don't expect FOOM like RSI, because I don't expect we'll get an mesa optimizer with coherent goals. It's not hard to give the outer optimiser (e.g. gradient decent) a coherent goal. For the outer optimiser to have a coherent goal is the default. But I don't expect that to translate to the inner optimiser. The inner optimiser will just have a bunch of heuristics and proxi-goals, and not be very coherent, just like humans.
The outer optimiser can't FOOM, since it don't do planing, and don't have strategic s... (read more)
Second reply. And this time I actually read the link. I'm not suppressed by that result.
My original comment was a reaction to claims of the type [the best way to solve almost any task is to develop general intelligence, therefore there is a strong selection pressure to become generally intelligent]. I think this is wrong, but I have not yet figured out exactly what the correct view is.
But to use an analogy, it's something like this: In the example you gave, the AI get's better at the sub tasks by learning on a more general training set. It seems like ... (read more)
I agree that eventually, at some level of trying to solve enough different types of tasks, GI will be efficient, in terms of how much machinery you need, but it will never be able to compete on speed.
Also, it's an open question what is "enough different types of tasks". Obviously, for a sufficient broad class of problems GI will be more efficient (in the sense clarified above). Equally obviously, for a sufficient narrow class of problems narrow capabilities will be more efficient.
Humans have GI to some extent, but we mostly don't use it. This i... (read more)
I think the confusion is because it is not clear form that section of the post if you are saying 1)"you don't need to do all of these things" or 2) "you don't need to do any of these things".
Because I think 1 goes without saying, I assumed you were saying 2. Also 2 probably is true in rare cases, but this is not backed up by your examples.
But if 1 don't go without saying, then this means that a lot of "doing science" is cargo-culting? Which is sort of what you are saying when you talk about cached methodologies.
In particular, four research activities were often highlighted as difficult and costly (here in order of decreasing frequency of mention):
Running experiments
Formalizing intuitions
Unifying disparate insights into a coherent frame
Proving theorems
I don't know what your first reaction to this list is, but for us, it was something like: "Oh, none of these activities seems strictly speaking necessary in knowledge-production." Indeed, a quick look at history presents us with cases where each of those activities was bypassed:
Thanks for your comment!
Actually, I don't think we really disagree. I might have just not made my position very clear in the original post.
The point of the post is not to say that these activities are not often valuable, but instead to point out that they can easily turn into "To do science, I need to always do [activity]". And what I'm getting from the examples is that in some cases, you actually don't need to do [activity]. There's a shortcut, or maybe just you're in a different phase of the problem.
Do you think there is still a disagreement after this clarification?
I mean that you take some known distribution (the training distribution) as a starting point. But when sampling actions you do so from shifted on truncated distribution to favour higher reward policies.
The in the decision transformers I linked, AI is playing a variety of different games, where the programmers might not know what a good future reward value would be. So they let the system AI predict the future reward, but with the distribution shifted towards higher rewards.
I discussed this a bit more after posting the above co... (read more)
From my reading of quantilizers, they might still choose "near-optimal" actions, just only with a small probability. Whereas a system based on decision transformers (possibly combined with a LLM) could be designed that we could then simply tell to "make me a tea of this quantity and quality within this time and with this probability" and it would attempt to do just that, without trying to make more or better tea or faster or with higher probability.
Any policy can be model as a consequentialist agent, if you assume a contrived enough utility function. This statement is true, but not helpful.
The reason we care about the concept agency, is because there are certain things we expect from consequentialist agents, e.g. instrumental convergent goals, or just optimisation pressure in some consistent direction. We care about the concept of agency because it holds some predictive power.
[... some steps of reasoning I don't know yet how to explain ...]
Therefore, it's better to use a concept of agency that ... (read more)
The completions are provided by the task authors (2 completions written for each example). We give those to the LM by evaluating the output probability of each completion given the input text. We then normalize the output probabilities to sum to 1, and then use those to compute the loss/accuracy/etc.
I'm confused why the uniform baseline is always 0.5. This makes sense when the model is choosing between A and B, or Y or N. But I don't see why you consider 0.5 to be a baseline in the other two cases.
I think the baseline is useful for interpretation. In some of the examples the reason the smaller model does better is because it is just answer randomly, while the larger model is misled somehow. But if there is no clear baseline, then I suggest removing this line from the plot.
These are all 2-way classification tasks (rather than e.g., free-form generation tasks), where the task authors provided 2 possible completions (1 correct and 1 incorrect), which is why we have a baseline!
There is nothing special about human level intelligence, unless you have imitation learning, in which case human level capabilities are very special.
General intelligence is not very efficient. Therefore there will not be any selection pressure for general intelligence as long as other options are available.
GI is very efficient, if you consider that you can reuse a lot machinery that you learn, rather than needing to relearn it over and over again. https://towardsdatascience.com/what-is-better-one-general-model-or-many-specialized-models-9500d9f8751d
If LMs reads each others text we can get LM-memetics. A LM meme is a pattern which, if it exists in the training data, the LM will output at higher frequency that in the training data. If the meme is strong enough and LLMs are trained on enough text from other LMs, the prevalence of the meme can grow exponentially. This has not happened yet.
There can also be memes that has a more complicated life cycle, involving both humans and LMs. If the LM output a pattern that humans are extra interested in, then the humans ... (read more)
Then (I think) for your inequality to hold, it must be that
U_B = f(3x+y), where f' >= 0
If U_B care about x and y in any other proportion, then B can make trade-offs between x and y which makes things better for B, but worse for A.
This will be true (in theory) even if both A and B are satisfisers. You can see this by assuming replacing y and x with sigmoids of some other variables.
According to my calculation, this embedding will result in too much compounding noise. I get the same noise results as you for one layer, but the noise grows too much from layer to layer.
However, Lucius suggested a different embedding, which seems to work.
We'll have some publication on this eventually. If you want to see the details sooner you can message me.