that's not a thing that really happens?
What is the thing that doesn't happen? Reading the rest of the paragraph only left me more confused.
Somehow being able to derive all relevant string diagram rewriting rules for latential string diagrams, starting with some fixed set of equivalences? Maybe this is just a framing thing, or not answering your question, but I would expect to need to explicitly assume/include things like the Frankenstein rule - more generally, picking which additional rewriting rules you want to use/include/allow is something you do in order to get equivalence/reachability in the category to line up correctly with what you want that equvialence to mean - you could just as soon make those choices poorly and (e.g.) allow arbitrary deletions of states, or addition of sampling flow that can't possibly respect causality; we don't do that here because it wouldn't result in string diagram behavior that matches what we want it to match.
I think I may have misunderstood, though, because that does sounds almost exactly like what I found to happen for the Joint Independence rule - you have some stated equivalence, and then you use string diagram rewriting rules common to all Markov category string diagrams in order to write the full form of the rule.
Simple form of the JI Rule - note the equivalences in the antecedent, which we can use to prove the consequent, not just enforce the equivalence!
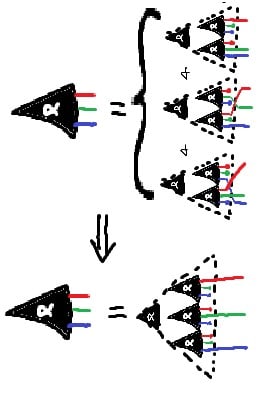
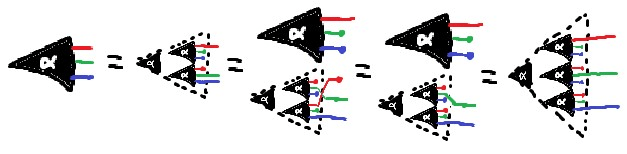
we don't quite care about Markov equivalence class
What do you mean by "Markov equivalence class"?
Two Bayes nets are of the same Markov equivalence class when they have precisely the same set of conditionality relations holding on them (and by extension, precisely the same undirected skeleton). You may recognize this as something that holds true when applicable for most of these rules, notably (sometimes) including the binary operations and notably excluding direct arrow-addition; additionally, this is something that applies for abstract Bayes nets just as well as concrete ones.
Hi! I spent some time working on exactly this approach last summer at MATS, and since then have kept trying to work out the details. It's been going slowly but parts of it have been going at all.
My take regarding your and @Alexander Gietelink Oldenziel's comments below is - that's not a thing that really happens? You pick the rules and your desired semantics first, and then you write down your manipulation rules to reflect those. Maybe it turns out that you got it wrong and there's more (or fewer!) rules of derivation to write down, but as long as the rules you wrote down follow some very easy constraints, you can just... write down anything. Or decline to. (Also, from a quick read I'm fairly sure you need a little bit more than just "free cartesian category" to hold of your domain category if you want nice structures to hang state/kernel-labels on. You want to be able to distinguish a concrete Bayes net (like, with numbers and everything) from an abstract "Bayes net", which is just a directed acyclic graph representing local conditionality structures - though we should note that usually people working with Bayes nets assume that we actually have trees, and not just DAGs!)
Maybe there's arguments from things like mathematical elegance or desired semantics or problematizing cases to choose to include or exclude some rule, or formulate a rule in one or another way, but ultimately you get to add structure to a category as suits you.
- Can we derive a full classification of such rules?
Probably there's no full classification, but I think that a major important point (which I should have just written up quickly way way long ago) is that we don't quite care about Markov equivalence class - only about whether any given move takes us to a diagram still compatible with the joint distribution/factorization that we started with.
- Is there a category-theoretic story behind the rules? Meaning, is there a type of category for which Bayes nets are something akin to string diagrams and the rules follow from the categorical axioms?
In my understanding there's a pretty clear categorical story - some of which are even just straight trivial! - to most of the rules. They make good sense in the categorical frame; some of them make so much sense that they're the kind of thing string diagrams don't even bother to track. I'm thinking of Factorization Transfer here, though the one major thing I've managed to get done is that the Joint Independence rule actually follows as a quick technical lemma from its assumptions/setup, rather than having to be assumed.
There's noncanonical choices getting made in the two "binary operation" rules, but even then it seems to me like the fact that we only ever apply that operation to two diagrams of the same "flavor" means we should likely only ever get back another diagram of the same "flavor"; apart from that, there's a strong smell of colimitness to both of those rules, which has kept me mulling over whether there's a useful "limitish" sort of rule that John and David both missed. Underlying this is my suspicion that we might get a natural preorder structure on latent Bayes nets/string diagrams as the pullback of the natural lattice on Markov equivalence classes, where one MEC is above another if it has strictly more conditionality relationships in it - i.e. the unique minimal element of the lattice is "everything is independent", and there's lots of maximal elements, and all our rules need to keep us inside the preimage of the upset of our starting MEC.
Which is to say: yes, yes there totally is such a type of category, but existing work mostly stopped at "Bayes nets akin to string diagrams", although I've seen some non-me work lately that looks to be attacking similar problems.
Just the word I use to describe "thing that has something to do with (natural) latents". More specifically for this case: a string diagram over a Markov category equipped with the extra stuff, structure, and properties that a Markov category needs to have in order to faithfully depict everything we care about when we want to write down statements or proofs about Bayes nets which might transform in some known restricted ways.
Something else. I'm saying that:
...so maybe some approach where you start by listing off all the identities you want to have hold and then derive the full ruleset from those would work at least partially? I guess I'm not totally clear what you mean by "categorical axioms" here - there's a fair amount that goes into a category; you're setting down all the rules for a tiny toy mathematical universe and are relatively unconstrained in how you do so, apart from your desired semantics. I'm also not totally confident that I've answered your question.
Yes. Well... almost. Classically you'd care a lot more about the MEC, but I've gathered that that's not actually true for latential Bayes nets. For those, we have some starting joint distribution J, which we care about a lot, and some diagram D_J which it factors over; alternatively, we have some starting set of conditionality requirements J, and some diagram D_J from among those that realize J. (The two cases are the same apart from the map that gives you actual numerical valuations for the states and transitions.)
We do indeed care about the asymmetric relation of "is every distribution compatible with X also compatible with Y", but we care about it because we started with some X_J and transformed it such that at every stage, the resulting diagram was still compatible with J.