Posts
Wikitag Contributions
Hey - reccommend looking at this paper: https://arxiv.org/abs/1807.07306
It shows a more elegant way than KL regularization for bounding the bit-rate of an auto-encoder bottleneck. This can be used to find the representations which are most important at a given level of information.
I think we can get additional information from the topological representation. We can look at the relationship between the different level sets under different cumulative probabilities. Although this requires evaluating the model over the whole dataset.
Let's say we've trained a continuous normalizing flow model (which are equivalent to ordinary differential equations). These kinds of model require that the input and output dimensionality are the same, but we can narrow the model as the depth increases by directing many of those dimensions to isotropic gaussian noise. I haven't trained any of these models before, so I don't know if this works in practice.
Here is an example of the topology of an input space. The data may be knotted or tangled, and includes noise. The contours show level sets .
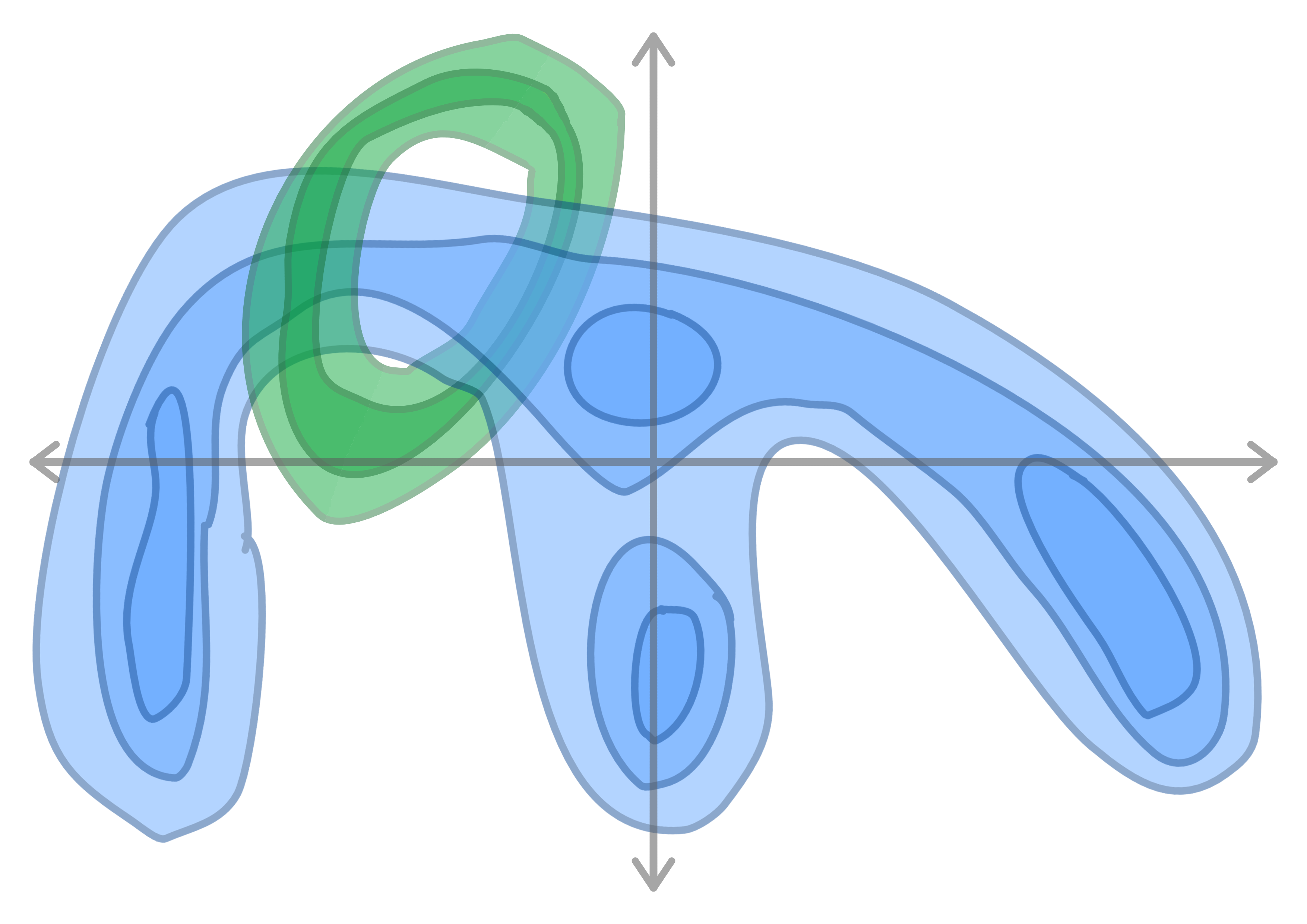
The model projects the data into a high dimensionality, then projects it back down into an arbitrary basis, but in the process untangling knots. (We can regularize the model to use the minimum number of dimensions by using an L1 activation loss
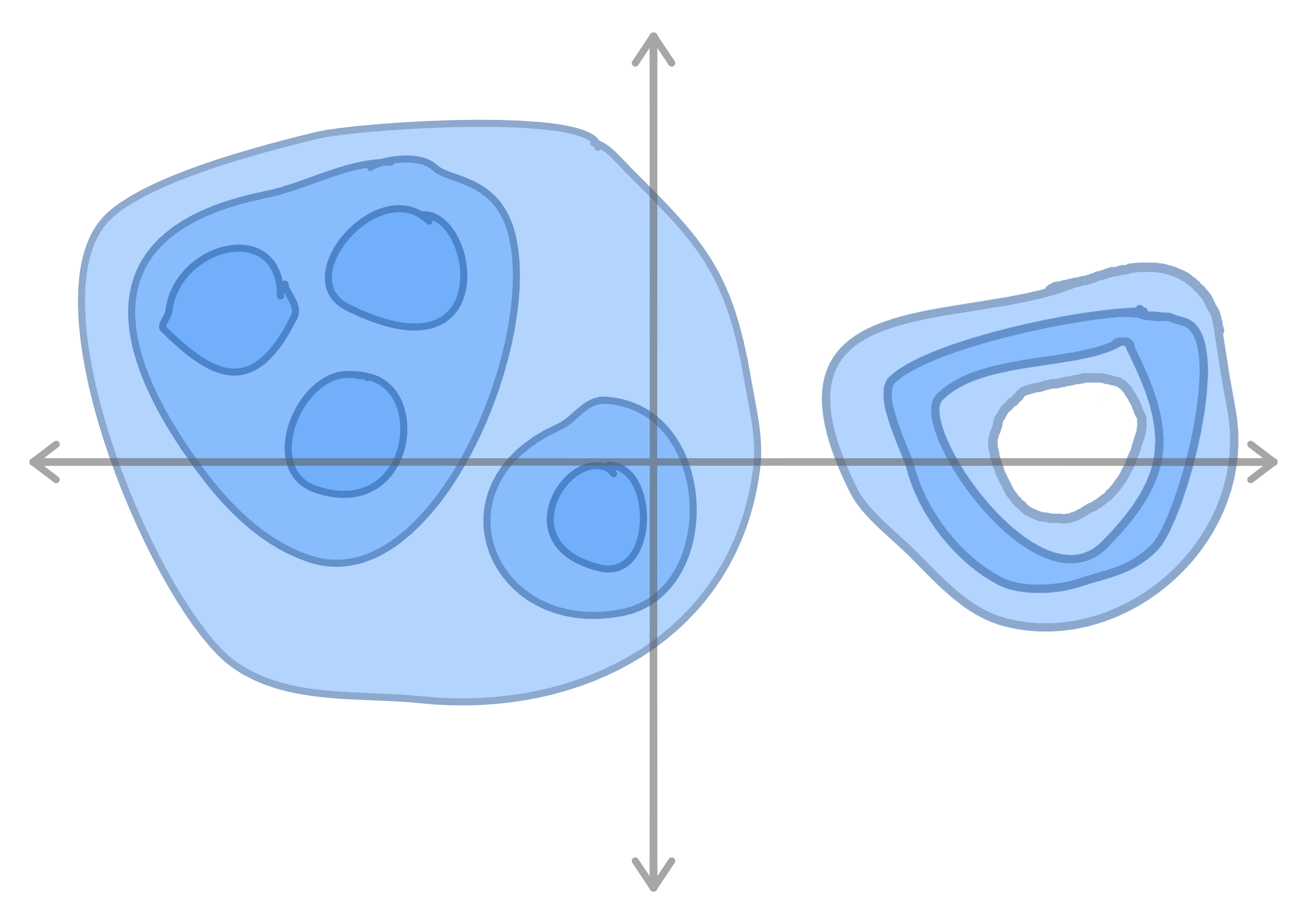
Lastly, we can view this topology as the Cartesian product of noise distributions and a hierarchical model. (I have some ideas for GAN losses that might be able to discover these directly)
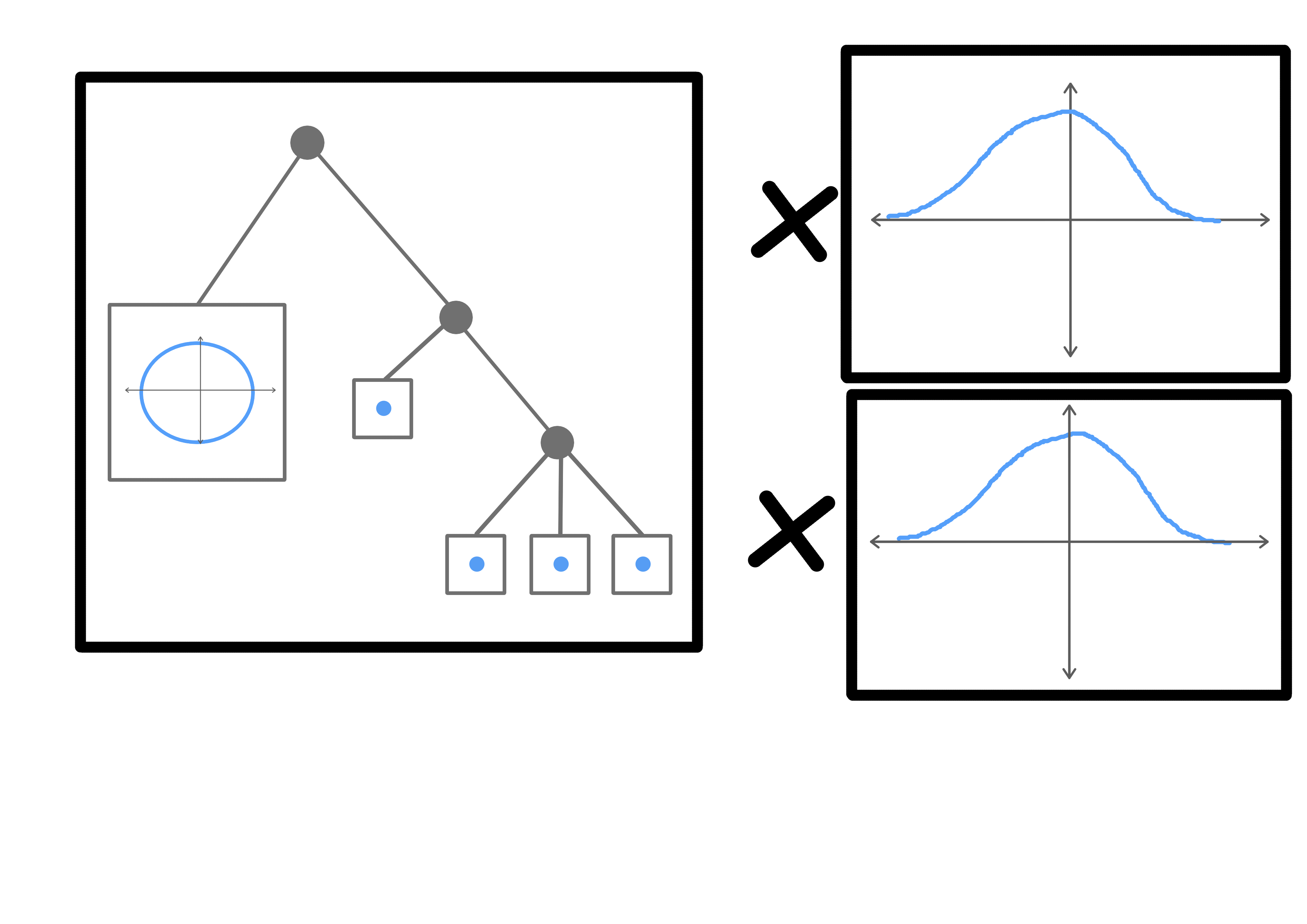
We can use topological structures like these as anchors. If a model is strong enough, they will correspond to real relationships between natural classes. This means that very similar structures will be present in different models. If these structures are large enough or heterogeneous enough, they may be unique, in which case we can use them to find transformations between (subspaces of) the latent spaces of two different models trained on similar data.
(Edited a lot from when originally posted)
(For more info on consistency see the diagram here: https://jepsen.io/consistency )
I think that the prompt to think about partially ordered time naturally leads one to think about consistency levels - but when thinking about agency, I think it makes more sense to just think about DAGs of events, not reads and writes. Low-level reality doesn't really have anything that looks like key-value memory. (Although maybe brains do?) And I think there's no maintaining of invariants in low-level reality, just cause and effect.
Maintaining invariants under eventual (or causal?) consistency might be an interesting way to think about minds. In particular, I think making minds and alignment strategies work under "causal consistency" (which is the strongest consistency level that can be maintained under latency / partitions between replicas), is an important thing to do. It might happen naturally though, if an agent is trained in a distributed environment.
So I think "strong eventual consistency" (CRDTs) and causal consistency are probably more interesting consistency levels to think about in this context than the really weak ones.
This is a good post, definitely shows that these concepts are confused. In a sense both examples are failures of both inner and outer alignment -
Also, the choice to train the AI on pull requests at all is in a sense an outer alignment failure.