AI Governance researcher with Polaris Ventures, formerly of the MTAIR project, TFI and Center on Long-term Risk, Graduate researcher at Kings and AI MSc at Edinburgh. Interested in philosophy, longtermism and AI Alignment.

Posts
Wikitag Contributions
Good point. You're right to highlight the importance of the offense-defense balance in determining the difficulty of high-impact tasks, rather than alignment difficulty alone. This is a crucial point that I'm planning on expand on in the next post in this sequence.
Many things determine the overall difficulty of HITs:
- the "intrinsic" offense-defense balance in related fields (like biotechnology, weapons technologies and cybersecurity) and especially whether there are irresolutely offense-dominant technologies that transformative AI can develop and which can't be countered
- Overall alignment difficulty, affecting whether we should expect to see a large number of strategic, power seeking unaligned systems or just systems engaging in more mundane reward hacking and sycophancy.
- Technology diffusion rates, especially for anything offense dominant, e.g. should we expect frontier models to leak or be deliberately open sourced
- Geopolitical factors, e.g. are there adversary countries or large numbers of other well resourced rogue actors to worry about not just accidents and leaks and random individuals
- The development strategy (e.g. whether the AI technologies are being proactively developed by a government or in public-private partnership or by companies who can't or won't use them protectively)
My rough suspicion is that all of these factors matter quite a bit, but since we're looking at "the alignment problem" in this post I'm pretending that everything else is held fixed.
The intrinsic offense-defense balance of whatever is next on the 'tech tree', as you noted, is maybe the most important overall, as it affects the feasibility of defensive measures and could push towards more aggressive strategies in cases of strong offense advantage. It's also extremely difficult to predict ahead of time.
Yes, I do think constitution design is neglected! I think it's possible people think constitution changes now won't stick around or that it won't make any difference in the long term, but I do think based on the arguments here that even if it's a bit diffuse you can influence AI behavior on important structural risks by changing their constitutions. It's simple, cheap and maybe quite effective especially for failure modes that we don't have any good shovel-ready technical interventions for.
If you want a specific practical example of the difference between the two: we now have AIs capable of being deceptive when not specifically instructed to do so ('strategic deception') but not developing deceptive power-seeking goals completely opposite what the overseer wants of them ('deceptive misalignment'). This from Apollo research on Strategic Deception is the former not the latter,
https://www.apolloresearch.ai/research/summit-demo
>APS is less understood and poorly forecasted compared to AGI.
I should clarify that I was talking about the definition used by forecasts like the Direct Approach methodology and/or the definition given in the metaculus forecast or in estimates like the Direct Approach. The latter is roughly speaking, capability sufficient to pass a hard adversarial Turing tests and human-like capabilities on enough intellectual tasks as measured by certain tests. This is something that can plausibly be upper bounded by the direct approach methodology which aims to predict when an AI could get a negligible error in predicting what a human expert would say over a specific time horizon. So this forecast is essentially a forecast of 'human-expert-writer-simulator AI', and that is the definition that's used in public elicitations like the metaculus forecasts.
However, I agree with you that while in some of the sources I cite that's how the term is defined it's not what the word denotes (just generality, which e.g. GPT-4 plausibly is for some weak sense of the word), and you also don't get from being able to simulate the writing of any human expert to takeover risk without making many additional assumptions.
I recently held a workshop with PIBBSS fellows on the MTAIR model and thought some points from the overall discussion were valuable:
The discussants went over various scenarios related to AI takeover, including a superficially aligned system being delegated lots of power and gaining resources by entirely legitimate means, a WFLL2-like automation failure, and swift foom takeover. Some possibilities involved a more covert, silent coup where most of the work was done through manipulation and economic pressure. The concept of "$1T damage" as an intermediate stage to takeover appeared to be an unnatural fit with some of these diverse scenarios. There was some mention of whether mitigation or defensive spending should be considered as part of that $1T figure.
Alignment Difficulty and later steps merge many scenarios
The discussants interpreted "alignment is hard" (step 3) as implying that alignment is sufficiently hard that (given that APS is built), at least one APS is misaligned somewhere, and also that there's some reasonable probability that any given deployed APS is unaligned. This is the best way of making the whole statement deductively valid.
However, proposition 3 being true doesn't preclude the existence of other aligned APS AI (hard alignment and at least one unaligned APS might mean that there are leading conscientious aligned APS projects but unaligned reckless competitors). This makes discussion of the subsequent questions harder, as we have to condition on there possibly being aligned APS present as well which might reduce the risk of takeover.
This means that when assessing proposition 4, we have to condition on some worlds where aligned APS has already been deployed and used for defense, some where there have been warning shots and strong responses without APS, some where misaligned APS emerges out of nowhere and FOOMs too quickly for any response, and a slow takeoff where nonetheless every system is misaligned and there is a WFLL2 like takeover attempt, and add up the chance of large scale damage in all of these scenarios, conditioning on their probability, which makes coming to an overall answer to 4 and 5 challenging.
Definitions are value-laden and don't overlap: TAI, AGI, APS
We differentiated between Transformative AI (TAI), defined by Karnofsky, Barnett and Cotra entirely by its impact on the world, which can either be highly destructive or drive very rapid economic growth; General AI (AGI), defined through a variety of benchmarks including passing hard adversarial Turing tests and human-like capabilities on enough intellectual tasks; and APS, which focuses on long-term planning and human-like abilities only on takeover-relevant tasks. We also mentioned Paul Christiano's notion of the relevant metric being AI 'as economically impactful as a simulation of any human expert' which technically blends the definitions of AGI and TAI (since it doesn't necessarily require very fast growth but implies it strongly). Researchers disagree quite a lot on even which of these are harder: Daniel Kokotaljo has argued that APS likely comes before TAI and maybe even before (the Matthew Barnett definition of) AGI, while e.g. Barnett thinks that TAI comes after AGI with APS AI somewhere in the middle (and possibly coincident with TAI).
In particular, some definitions of ‘AGI’, i.e. human-level performance on a wide range of tasks, could be much less than what is required for APS depending on what the specified task range is. If the human-level performance is only on selections of tasks that aren’t useful for outcompeting humans strategically (which could still be very many tasks, for example, human-level performance on everything that requires under a minute of thinking), the 'AGI system' could almost entirely lack the capabilities associated with APS. However, most of the estimates that could be used in a timelines estimate will revolve around AGI predictions (since they will be estimates of performance or accuracy benchmarks), which we risk anchoring on if we try to adjust them to predict the different milestones of APS.
In general it is challenging to use the probabilities from one metric like TAI to inform other predictions like APS, because each definition includes many assumptions about things that don't have much to do with AI progress (like how qualitatively powerful intelligence is in the real world, what capabilities are needed for takeover, what bottlenecks are there to economic automation or research automation etc.) In other words, APS and TAI are value-laden terms that include many assumptions about the strategic situation with respect to AI takeover, world economy and likely responses.
APS is less understood and more poorly forecasted compared to AGI. Discussants felt the current models for AGI can't be easily adapted for APS timelines or probabilities. APS carries much of the weight in the assessment due to its specific properties: i.e. many skeptics might argue that even if AGI is built, things which don't meet the definition of APS might not be built.
Alignment and Deployment Decisions
Several discussants suggested splitting the model’s third proposition into two separate components: one focusing on the likelihood of building misaligned APS systems (3a) and the other on the difficulty of creating aligned ones (3b). This would allow a more nuanced understanding of how alignment difficulties influence deployment decisions. They also emphasized that detection of misalignment would impact deployment, which wasn't sufficiently clarified in the original model.
Advanced Capabilities
There was a consensus that 'advanced capabilities' as a term is too vague. The discussants appreciated the attempt to narrow it down to strategic awareness and advanced planning but suggested breaking it down even further into more measurable skills, like hacking ability, economic manipulation, or propaganda dissemination. There are, however, disagreements regarding which capabilities are most critical (which can be seen as further disagreements about the difficulty of APS relative to AGI).
If strategic awareness comes before advanced planning, we might see AI systems capable of manipulating people, but not in ways that greatly exceed human manipulative abilities. As a result, these manipulations could potentially be detected and mitigated and even serve as warning signs that lower total risk. On the other hand, if advanced capabilities develop before strategic awareness or advanced planning, we could encounter AI systems that may not fully understand the world or their position in it, nor possess the ability to plan effectively. Nevertheless, these systems might still be capable of taking single, highly dangerous actions, such as designing and releasing a bioweapon.
Outside View & Futurism Reliability
We didn't cover the outside view considerations extensively, but various issues under the "accuracy of futurism" umbrella arose which weren't specifically mentioned.
The fact that markets don't seem to have reacted as if Transformative AI is a near-term prospect, and the lack of wide scale scrutiny and robust engagement with risk arguments (especially those around alignment difficulty), were highlighted as reasons to doubt this kind of projection further.
The Fermi Paradox implies a form of X-risk that is self-destructive and not that compatible with AI takeover worries, while market interest rates also push the probability of such risks downward. The discussants recommended placing more weight on outside priors than we did in the default setting for the model, suggesting a 1:1 ratio compared to the model's internal estimations.
Discussants also agreed with the need to balance pessimistic surviva- is-conjunctive views and optimistic survival-is-disjunctive views, arguing that the Carlsmith model is biased towards optimism and survival being disjunctive but that the correct solution is not to simply switch to a pessimism-biased survival is conjunctive model in response.
Difficult to separate takeover from structural risk
There's a tendency to focus exclusively on the risks associated with misaligned APS systems seeking power, which can introduce a bias towards survival being predicated solely on avoiding APS takeover. However, this overlooks other existential risk scenarios that are more structural. There are potential situations without agentic power-seeking behavior but characterized by rapid changes could for less causally clear reasons include technological advancements or societal shifts that may not necessarily have a 'bad actor' but could still spiral into existential catastrophe. This post describes some of these scenarios in more detail.
Oh, we've been writing up these concerns for 20 years and no one listens to us.' My view is quite different. I put out a call and asked a lot of people I know, well-informed people, 'Is there any actual mathematical model of this process of how the world is supposed to end?'...So, when it comes to AGI and existential risk, it turns out as best I can ascertain, in the 20 years or so we've been talking about this seriously, there isn't a single model done.
I think that MTAIR plausibly is a model of the 'process of how the world is supposed to end', in the sense that it runs through causal steps where each individual thing is conditioned on the previous thing (APS is developed, APS is misaligned, given misalignment it causes damage on deployment, given that the damage is unrecoverable), and for some of those inputs your probabilities and uncertainty distribution could itself come from a detailed causal model (e.g. you can look at the Direct Approach for the first two questions.
For the later questions, like e.g. what's the probability that an unaligned APS can inflict large disasters given that it is deployed, we can enumerate ways that it could happen in detail but to assess their probability you'd need to do a risk assessment with experts not produce a mathematical model.
E.g. you wouldn't have a "mathematical model" of how likely a US-China war over Taiwan is, you'd do wargaming and ask experts or maybe superforecasters. Similarly, for the example that he gave which was COVID there was a part of this that was a straightforward SEIR model and then a part that was more sociological talking about how the public response works (though of course a lot of the "behavioral science" then turned out to be wrong!).
So a correct 'mathematical model of the process' if we're being fair, would use explicit technical models for technical questions and for sociological/political/wargaming questions you'd use other methods. I don't think he'd say that there's no 'mathematical model' of nuclear war because while we have mathematical models of how fission and fusion works, we don't have any for how likely it is that e.g. Iran's leadership decides to start building nuclear weapons.
I think Tyler Cowen would accept that as sufficiently rigorous in that domain, and I believe that the earlier purely technical questions can be obtained from explicit models. One addition that could strengthen the model is to explicitly spell out different scenarios for each step (e.g. APS causes damage via autonomous weapons, economic disruption, etc). But the core framework seems sufficient as is, and also those concerns have been explained in other places.
What do you think?
The alignment difficulty scale is based on this post.
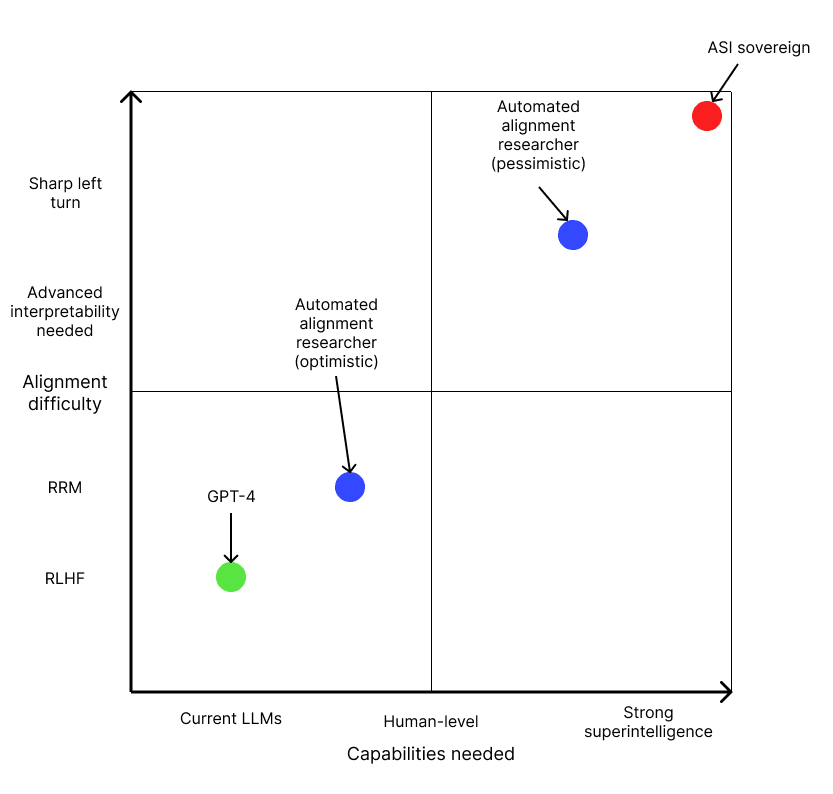
I really like this post and think it's a useful addendum to my own alignment difficulty scale (making it 2D, essentially). But I think I was conceptualizing my scale as running along the diagonal line you provide from GPT-4 to sovereign AI. But I think your way of doing it is better on reflection.
In my original post when I suggested that the 'target' level of capability we care about is the capability level needed to build positively transformative AI (pTAI), which is essentially the 'minimal aligned AGI that can do a pivotal act' notion but is more agnostic about whether it will be a unitary agentic system or many systems deployed over a period.
I think that what most people talk about when they talk about alignment difficulty isn't how hard the problem 'ultimately' is but rather how hard the problem is that we need to solve, with disagreements also being about e.g. how capable an AI you need for various pivotal/positively transformative acts.
I didn't split these up because I think that in a lot of people's minds the two run together in a fairly unprincipled way, but if we want a scale that corresponds to real things in the world having a 2D chart like this is better.
Update
This helpful article by Holden Karnofsky also describes an increasing scale of alignment difficulty, although it's focused on a narrower range of the scale than mine (his scale covers 4-7) and is a bit more detailed about the underlying causes of the misalignment. Here's how my scale relates to his:
The "playing the training game" threat model, where systems behave deceptively only to optimize in-episode reward, corresponds to an alignment difficulty level of 4 or higher. This is because scalable oversight without interpretability tools (level 4) should be sufficient to detect and address this failure mode. The AI may pretend to be helpful during training episodes, but oversight exposing it to new situations will reveal its tendency toward deception.
(Situationally aware) Deception by default corresponds to a difficulty level of 6. If misaligned AIs form complex inner goals and engage in long-term deception, then scalable oversight alone will not catch intentionally deceptive systems that can maintain consistent deceitful behavior. Only interpretability tools used as part of the oversight process (level 6) give us the ability to look inside the system and identify deceptive thought patterns and tendencies.
Finally, the gradient hacking threat model, where AIs actively manipulate their training to prevent alignment, represents an alignment difficulty of 7 or higher. Even interpretability-based oversight can be defeated by sufficiently sophisticated systems that alter their internals to dodge detection.
I think that, on the categorization I provided,
'Playing the training game' at all corresponds to an alignment difficulty level of 4 because better than human behavioral feedback and oversight can reveal it and you don't need interpretability.
(Situationally aware) Deception by default corresponds to a difficulty level of 6 because if it's sufficiently capable no behavioral feedback will work and you need interpretability-based oversight
Gradient hacking by default corresponds to a difficulty level of 7 because the system will also fight interpretability based oversight and you need to think of something clever probably through new research at 'crunch time'.
The fact that an AI arms race would be extremely bad does not imply that rising global authoritarianism is not worth worrying about (and vice versa)
I am someone who is worried both about AI risks (from loss of control, and from war and misuse/structural risks) and from what seems to be a 'new axis' of authoritarian threats cooperating in unprecedented ways.
I won't reiterate all the evidence here, but these two pieces and their linked sources should suffice:
Despite believing this thesis, I am not, on current evidence, in favor of aggressive efforts to "race and beat China" in AI, or for abandoning attempts to slow an AGI race. I think on balance it is still worth trying these kinds of cooperation, while being clear eyed about the threats we face. I do think that there are possible worlds where, regretfully and despite the immense dangers, there is no other option but to race. I don't think that we are in such a world as of yet.
However, I notice that many of the people who agree with me that an AI arms race would be very bad and that we should avoid it tend to diminish the risks of global authoritarianism or the difference between the west and its enemies, and very few seem to buy into the above thesis that there is a dangerous interconnected web of authoritarian states with common interests developing.
Similarly, most of the people who see the authoritrian threat which has emerged into clear sight over the last few years (from China, Russia, Iran, North Korea and similar actors) want to respond by racing and think alignment will not be too difficult. This includes the leaders of many AI companies who may have their own less patriotic reasons for pushing such an agenda.
I think this implicit correlation should be called out as a mistake.
As a matter of simple logic, how dangerous frantic AGI development is, and how hostile foreign adversaries are, are two unrelated variables which shouldn't correlate.
In my mind, the following are all true:
I basically never see these 3 acknowledged all at once. We either see (1) and (3) grouped together or (2) alone. I'm not sure what the best AI governance strategy to adopt is, but an analysis should start with a clear eyed understanding of the international situation and what values matter.