Posts
Wikitag Contributions
On , it's unclear what a "natural" choice would be for setting this parameter in order to simplify the architecture further. One natural reference point is to set it to , but this corresponds to getting rid of the discontinuity in the Jump ReLU (turning the magnitude encoder into a ReLU on multiplicatively rescaled gate encoder preactivations). Effectively (removing the now unnecessary auxiliary task), this would give results similar to the "baseline + rescale & shift" benchmark in section 5.2 of the paper, although probably worse, as we wouldn't have the shift.
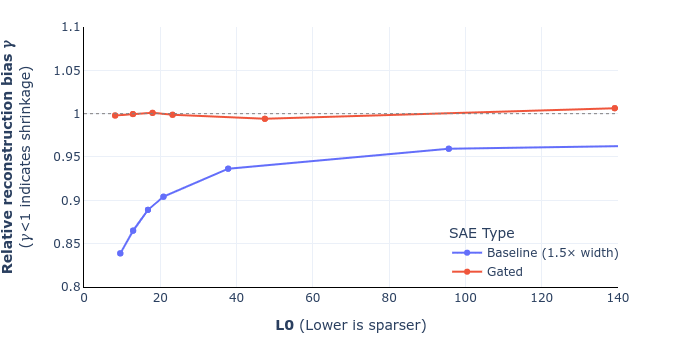
UPDATE: we've corrected equations 9 and 10 in the paper (screenshot of the draft below) and also added a footnote that hopefully helps clarify the derivation. I've also attached a revised figure 6, showing that this doesn't change the overall story (for the mathematical reasons I mentioned in my previous comment). These will go up on arXiv, along with some other minor changes (like remembering to mention SAEs' widths), likely some point next week. Thanks again Sam for pointing this out!
Updated equations (draft):

Updated figure 6 (shrinkage comparison for GELU-1L):
Yep, the intuition here indeed was that L1 penalised reconstruction seems to be okay for teaching a standard SAE's encoder to detect which features are on (even if features get shrunk as a result), so that is effectively what this auxiliary loss is teaching the gate sub-layer to do, alongside the sparsity penalty. (The key difference being we freeze the decoder in the auxiliary task, which the ablation study shows helps performance.) Maybe to put it another way, this was an auxiliary task that we had good evidence would teach the gate sublayer to detect active features reasonably well, and it turned out to give good results in practice. It's totally possible though that there are better auxiliary tasks (or even completely different loss functions) out there that we've not explored.
Hey Sam, thanks - you're right. The definition of reconstruction bias is actually the argmin of
which I'd (incorrectly) rearranged as the expression in the paper. As a result, the optimum is
That being said, the derivation we gave was not quite right, as I'd incorrectly substituted the optimised loss rather than the original reconstruction loss, which makes equation (10) incorrect. However the difference between the two is small exactly when gamma is close to one (and indeed vanishes when there is no shrinkage), which is probably why we didn't pick this up. Anyway, we plan to correct these two equations and update the graphs, and will submit a revised version.
Thanks for copying this over!
For what it's worth, my current view on SAEs is that they remain a pretty neat unsupervised technique for making (partial) sense of activations, but they fit more into the general category of unsupervised learning techniques, e.g. clustering algorithms, than as a method that's going to discover the "true representational directions" used by the language model. And, as such, they share many of the pros and cons of unsupervised techniques in general:[1]
I think this means SAEs could still be useful for generating hypotheses when trying to understand model behaviour, and and I really like the CLTs papers in this regard.[2] However, it's still unclear whether they are better for hypothesis generation than alternative techniques, particularly techniques that have other advantages, like the ability to be used with limited model access (i.e. black-box techniques) or techniques that don't require paying a large up-front cost before they can be used on a model.
I largely agree with your updates 1 and 2 above, although on 2 I still think it's plausible that while many "why is the model doing X?" type questions can be answered with black-box techniques today, this may not continue to hold into the future, which is why I still view interp as a worthwhile research direction. This does make it important though to always try strong baselines on any new project and only get excited when interp sheds light on problems that genuinely seem hard to solve using these baselines.[3]
When I say unsupervised learning, I'm using this term in its conventional sense, e.g. clustering algorithms, manifold learning, etc; not in the sense of tasks like language model pre-training which I sometimes see referred to as unsupervised. ↩︎
Particularly its emphasis on techniques to prune massive attribution graphs, improving tooling for making sense of the results, and accepting that some manual adjustment of the decompositions produced by CLTs may be necessary because we're giving up on the idea that CLTs / SAEs are uncovering a "true basis". ↩︎
And it does seem that black box methods often suffice (in the sense of giving "good enough explanations" for whatever we need these explanations for) when we try to do this. Though this could just be - as you say - because of bad judgement. I'd definitely appreciate suggestions for better downstream tasks we should try! ↩︎