Copying over from X an exchange related to this post:
I’m a bit confused by this - perhaps due to differences of opinion in what ‘fundamental SAE research’ is and what interpretability is for. This is why I prefer to talk about interpreter models rather than SAEs - we’re attached to the end goal, not the details of methodology. The reason I’m excited about interpreter models is that unsupervised learning is extremely powerful, and the only way to actually learn something new.
[thread continues]
A subtle point in our work worth clarifying: Initial hopes for SAEs were very ambitious: finding unknown unknowns but also representing them crisply and ideally a complete decomposition. Finding unknown unknowns remains promising but is a weaker claim alone, we tested the others
OOD probing is an important use case IMO but it's far from the only thing I care about - we were using a concrete case study as grounding to get evidence about these empirical claims - a complete, crisp decomposition into interpretable concepts should have worked better IMO.
[thread continues]
Sam Marks (me):
FWIW I disagree that sparse probing experiments[1] test the "representing concepts crisply" and "identify a complete decomposition" claims about SAEs.
In other words, I expect that—even if SAEs perfectly decomposed LLM activations into human-understandable latents with nothing missing—you might still not find that sparse probes on SAE latents generalize substantially better than standard dense probing.
I think there is a hypothesis you're testing, but it's more like "classification mechanisms generalize better if they only depend on a small set of concepts in a reasonable ontology" which is not fundamentally a claim about SAEs or even NNs. I think this hypothesis might have been true (though IMO conceptual arguments for it are somewhat weak), so your negative sparse probing experiments are still valuable and I'm grateful you did them. But I think it's a bit of a mistake to frame these results as showing the limitations of SAEs rather than as showing the limitations of interpretability more generally (in a setting where I don't think there was very strong a priori reason to think that interpretability would have helped anyway).
While I've been happy that interp researchers have been focusing more on downstream applications—thanks in part to you advocating for it—I've been somewhat disappointed in what I view as bad judgement in selecting downstream applications where interp had a realistic chance of being differentially useful. Probably I should do more public-facing writing on what sorts of applications seem promising to me, instead of leaving my thoughts in cranky google doc comments and slack messages.
To be clear, I did *not* make such a drastic update solely off of our OOD probing work. [...] My update was an aggregate of:
- Several attempts on downstream tasks failed (OOD probing, other difficult condition probing, unlearning, etc)
- SAEs have a ton of issues that started to surface - composition, aborption, missing features, low sensitivity, etc
- The few successes on downstream tasks felt pretty niche and contrived, or just in the domain of discovery - if SAEs are awesome, it really should not be this hard to find good use cases...
It's kinda awkward to simultaneously convey my aggregate update, along with the research that was just one factor in my update, lol (and a more emotionally salient one, obviously)
There's disagreement on my team about how big an update OOD probing specifically should be, but IMO if SAEs are to be justified on pragmatic grounds they should be useful for tasks we care about, and harmful intent is one such task - if linear probes work and SAEs don't, that is still a knock against SAEs. Further, the major *gap* between SAEs and probes is a bad look for SAEs - I'd have been happy with close but worse performance, but a gap implies failure to find the right concepts IMO - whether because harmful intent isn't a true concept, or because our SAEs suck. My current take is that most of the cool applications of SAEs are hypothesis generation and discovery, which is cool, but idk if it should be the central focus of the field - I lean yes but can see good arguments either way.
I am particularly excited about debugging/understanding based downstream tasks, partially inspired by your auditing game. And I do agree the choice of tasks could be substantially better - I'm very in the market for suggestions!
Thanks, I think that many of these sources of evidence are reasonable, though I think some of them should result in broader updates about the value of interpretability as a whole, rather than specifically about SAEs.
In more detail:
SAEs have a bunch of limitations on their own terms, e.g. reconstructing activations poorly or not having crisp features. Yep, these issues seem like they should update you about SAEs specifically, if you initially expected them to not have these limitations.
Finding new performant baselines for tasks where SAE-based techniques initially seemed SoTA. I've also made this update recently, due to results like:
(A) Semantic search proving to be a good baseline in our auditing game (section 5.4 of https://arxiv.org/abs/2503.10965 )
(B) Linear probes also identifying spurious correlations (section 4.3.2 of https://arxiv.org/pdf/2502.16681 and other similar results)
(C) Gendered token deletion doing well for the Bias in Bios SHIFT task (https://lesswrong.com/posts/QdxwGz9AeDu5du4Rk/shift-relies-on-token-level-features-to-de-bias-bias-in-bios… )
I think the update from these sorts of "good baselines" results is twofold:
1. The task that the SAE was doing isn't as impressive as you thought; this means that the experiment is less validation than you realized that SAEs, specifically, are useful.
2. Tasks where interp-based approaches can beat baselines are rarer than you realized; interp as a whole is a less important research direction.
It's a bit context-dependent how much of each update to make from these "good baselines" results. E.g. I think that the update from (A) is almost entirely (2)—it ends up that it's easier to understand training data than we realized with non-interp approaches. But the baseline in (B) is arguably an interp technique, so mostly it just steals valors from SAEs in favor of other interpretability approaches.
Obvious non-interp baselines outperformed SAEs on [task]. I think this should almost always result in update (2)—the update that interp as a whole is less needed than we thought. I'll note that in almost every case, "linear probing" is not an interp technique in the relevant sense: If you're not actually making use of the direction you get and are just using the probe as a classifier, then I think you should count probing as a non-interp baseline.
I agree with most of this post. Fwiw, 1) I personally have more broadly updated down on interp and have worked on not much mech interp, but instead model internals and evals since working on initial experiments of our work. 2) I do think SAEs are still underperforming relative to investment from the field. Including today’s progress on CLTs! It is exciting work, but IMO there are a lot of ifs ahead of SAEs being actually providing nontrivial counterfactual direct value to safety
- ^
To clarify, my points here are about OOD probing experiments where the SAE-based intervention is "just regularize the probe to attend to a sparse subset of the latents."
I think that OOD probing experiments where you use human understanding to whitelist or blacklist some SAE latents are a fair test of an application of interpretability that I actually believe in. (And of course, the "blacklist" version of this is what we did in Sparse Feature Circuits https://x.com/saprmarks/status/1775513451668045946… )
Thanks for copying this over!
For what it's worth, my current view on SAEs is that they remain a pretty neat unsupervised technique for making (partial) sense of activations, but they fit more into the general category of unsupervised learning techniques, e.g. clustering algorithms, than as a method that's going to discover the "true representational directions" used by the language model. And, as such, they share many of the pros and cons of unsupervised techniques in general:[1]
- (Pros) They may be useful / efficient for getting a first pass understanding of what's going in a model / with some data (indeed many of their success stories have this flavour).
- (Cons) They are hit and miss - often not carving up the data in the way you'd prefer, with weird omissions or gerrymandered boundaries you need to manually correct for. Once you have a hypothesis, a supervised method will likely give you better results.
I think this means SAEs could still be useful for generating hypotheses when trying to understand model behaviour, and and I really like the CLTs papers in this regard.[2] However, it's still unclear whether they are better for hypothesis generation than alternative techniques, particularly techniques that have other advantages, like the ability to be used with limited model access (i.e. black-box techniques) or techniques that don't require paying a large up-front cost before they can be used on a model.
I largely agree with your updates 1 and 2 above, although on 2 I still think it's plausible that while many "why is the model doing X?" type questions can be answered with black-box techniques today, this may not continue to hold into the future, which is why I still view interp as a worthwhile research direction. This does make it important though to always try strong baselines on any new project and only get excited when interp sheds light on problems that genuinely seem hard to solve using these baselines.[3]
When I say unsupervised learning, I'm using this term in its conventional sense, e.g. clustering algorithms, manifold learning, etc; not in the sense of tasks like language model pre-training which I sometimes see referred to as unsupervised. ↩︎
Particularly its emphasis on techniques to prune massive attribution graphs, improving tooling for making sense of the results, and accepting that some manual adjustment of the decompositions produced by CLTs may be necessary because we're giving up on the idea that CLTs / SAEs are uncovering a "true basis". ↩︎
And it does seem that black box methods often suffice (in the sense of giving "good enough explanations" for whatever we need these explanations for) when we try to do this. Though this could just be - as you say - because of bad judgement. I'd definitely appreciate suggestions for better downstream tasks we should try! ↩︎
I agree with most of this, especially
SAEs [...] remain a pretty neat unsupervised technique for making (partial) sense of activations, but they fit more into the general category of unsupervised learning techniques, e.g. clustering algorithms, than as a method that's going to discover the "true representational directions" used by the language model.
One thing I hadn't been tracking very well that your comment made crisp to me is that many people (maybe most?) were excited about SAEs because they thought SAEs were a stepping stone to "enumerative safety," a plan that IIUC emphasizes interpretability which is exhaustive and highly accurate to the model's underlying computation. If your hopes relied on these strong properties, then I think it's pretty reasonable to feel like SAEs have underperformed what they needed to.
Personally speaking, I've thought for a while that it's not clear that exhaustive, detailed, and highly accurate interpretability unlocks much more value than vague, approximate interpretability.[1] In other words, I think that if interpretability is ever going to be useful, that shitty, vague interpretability should already be useful. Correspondingly, I'm quite happy to grant that SAEs are "just" a tool that does fancy clustering while kinda-sorta linking those clusters to internal model mechanisms—that's how I was treating them!
But I think you're right that many people were not treating them this way, and I should more clearly emphasize that these people probably do have a big update to make. Good point.
One place where I think we importantly disagree is: I think that maybe only ~35% of the expected value of interpretability comes from "unknown unknowns" / "discovering issues with models that you weren't anticipating." (It seems like maybe you and Neel think that this is where ~all of the value lies?)
Rather, I think that most of the value lies in something more like "enabling oversight of cognition, despite not having data that isolates that cognition." In more detail, I think that some settings have structural properties that make it very difficult to use data to isolate undesired aspects of model cognition. A prosaic example is spurious correlations, assuming that there's something structural stopping you from just collecting more data that disambiguates the spurious cue from the intended one. Another example: It might be difficult to disambiguate the "tell the human what they think is the correct answer" mechanism from the "tell the human what I think is the correct answer" mechanism. I write about this sort of problem, and why I think interpretability might be able to address it, here. And AFAICT, I think it really is quite different—and more plausibly interp-advantaged—than "unknown unknowns"-type problems.
To illustrate the difference concretely, consider the Bias in Bios task that we applied SHIFT to in Sparse Feature Circuits. Here, IMO the main impressive thing is not that interpretability is useful for discovering a spurious correlation. (I'm not sure that it is.) Rather, it's that—once the spurious correlation is known—you can use interp to remove it even if you do not have access to labeled data isolating the gender concept.[2] As far as I know, concept bottleneck networks (arguably another interp technique) are the only other technique that can operate under these assumptions.
- ^
Just to establish the historical claim about my beliefs here:
- Here I described the idea that turned into SHIFT as "us[ing] vague understanding to guess which model components attend to features which are spuriously correlated with the thing you want, then use the rest of the model as an improved classifier for the thing you want".
- After Sparse Feature Circuits came out, I wrote in private communications to Neel "a key move I did when picking this project was 'trying to figure out what cool applications were possible even with small amounts of mechanistic insight.' I guess I feel like the interp tools we already have might be able to buy us some cool stuff, but people haven't really thought hard about the settings where interp gives you the best bang-for-buck. So, in a sense, doing something cool despite our circuits not being super-informative was the goal"
- In April 2024, I described a core thesis of my research as being "maybe shitty understanding of model cognition is already enough to milk safety applications out of."
- ^
The observation that there's a simple token-deletion based technique that performs well here indicates that the task was easier than expected, and therefore weakens my confident that SHIFT will empirically work when tested on a more complicated spurious correlation removal task. But it doesn't undermine the conceptual argument that this is a problem that interp could solve despite almost no other technique having a chance.
Rather, I think that most of the value lies in something more like "enabling oversight of cognition, despite not having data that isolates that cognition."
Is this a problem you expect to arise in practice? I don't really expect it to arise, if you're allowing for a significant amount of effort in creating that data (since I assume you'd also be putting a significant amount of effort into interpretability).
Promoted to curated: I really liked this post for its combination of reporting negative results, communicating a deeper shift in response to those negative results, while seeming pretty well-calibrated about the extent of the update. I would have already been excited about curating this post without the latter, but it felt like an additional good reason.
I never understood the SAE literature, which came after my earlier work (2019-2020) on sparse inductive biases for feature detection (i.e., semi-supervised decomposition of feature contributions) and interpretability-by-exemplar via model approximations (over the representation space of models), which I originally developed for the goal of bringing deep learning to medicine. Since the parameters of the large neural networks are non-identifiable, the mechanisms for interpretability must shift from understanding individual parameter values to semi-supervised matching against comparable instances and most importantly, to robust and reliable predictive uncertainty over the output, for which we now have effective approaches: https://www.lesswrong.com/posts/YxzxzCrdinTzu7dEf/the-determinants-of-controllable-agi-1
(That said, obviously the normal caveat applies that people should feel free to study whatever they are interested in, as you can never predict what other side effects, learning, and new results---including in other areas---might occur.)
Lewis Smith*, Sen Rajamanoharan*, Arthur Conmy, Callum McDougall, Janos Kramar, Tom Lieberum, Rohin Shah, Neel Nanda
* = equal contribution
The following piece is a list of snippets about research from the GDM mechanistic interpretability team, which we didn’t consider a good fit for turning into a paper, but which we thought the community might benefit from seeing in this less formal form. These are largely things that we found in the process of a project investigating whether sparse autoencoders (SAEs) were useful for downstream tasks, notably out-of-distribution probing.
TL;DR
Introduction
Motivation
Our core motivation was that we, along with much of the interpretability community, had invested a lot of our energy into Sparse Autoencoder (SAE) research. But SAEs lack a ground truth of the “true” features in language models to compare to, making it pretty unclear how well they work. There is qualitative evidence that SAEs are clearly doing something, far more structure than you would expect by random chance. But they clearly have a bunch of issues: if you just type an arbitrary sentence into Neuronpedia, and look at the latents that light up, they do not seem to perfectly correspond to a crisp explanation.
More generally, when thinking about whether we should prioritise working on SAEs, it's worth thinking about how to decide what kind of interpretability research to do in general. One perspective is to assume there is some crisp, underlying, human-comprehensible truth for what is going on in the model, and to try to build techniques to reverse engineer it. In the case of SAEs, this looks like the hope that SAE latents capture some canonical set of true concepts inside the model. We think it is clear now that SAEs in their current form are far from achieving this, and it is unclear to us if such “true concepts” even exist. There are several flaws with SAEs that prevent them from capturing a true set of concepts even if one exists, and we are pessimistic that these can all be resolved:
But there are other high-level goals for interpretability than perfectly finding the objective truth of what’s going on - if we can build tools that give understanding that’s imperfect but enough to let us do useful things, like understand whether a model is faking alignment, that is still very worthwhile. Several important goals, like trying to debug mysterious failures and phenomena, achieving a better understanding of what goals and deception look like, or trying to detect deceptive alignment, do not necessarily require us to discover all of the ‘true features’ of a model; a decent approximation to the models computation might well be good enough. But how could we tell if working on SAEs was bringing us closer to these goals?
Our hypothesis was that if SAEs will eventually be useful for these ambitious tasks, they should enable us to do something new today. So, the goal of this project was to investigate whether we can do anything useful on downstream tasks with SAEs in a way that was at all competitive with baselines - i.e. a task that can be described without making any reference to interpretability. If SAEs are working well enough to be a valuable tool, then there should be things they enable us to do that we cannot currently easily do. And so we thought that if we picked some likely examples of such tasks and then made a fair comparison to well-implemented baselines on some downstream task then, if the SAE does well (ideally beating the baseline, but even just coming close while being non-trivially different), this is a sign that the SAE is a valuable technique worthy of further refinement. Further, even if the SAE doesn’t succeed, it gives you an eval to measure future SAE progress, like how Farrell et al’s unlearning setup was turned into an eval in SAEBench.
Our Task
So what task did we focus on? Our key criteria was to be objectively measurable, be something that other people cared about and, within those constraints, aiming for something where we thought SAEs might have an edge. As such, we focused on training probes that generalise well out of distribution. We thought that, for sufficiently good SAEs, a sparse probe in SAE latents would be less likely to overfit to minor spurious correlations compared to a dense probe, and thus that being interpretable gave a valuable inductive bias (though are now less confident in this argument). We specifically looked in the context of detecting harmful user intent in the presence of different jailbreaks, and used new jailbreaks as our OOD set.
Sadly, our core results are negative:
We did have one positive result: the sparse SAE probes enabled us to quickly identify spurious correlations in our dataset, which we cleaned up. Note this slightly stacks the deck against SAEs, since without SAE-based debugging, the linear probes may have latched onto these spurious correlations – however, we think we plausibly could have found the spurious correlations without SAEs given more time, e.g. Kantamneni et al showed simpler methods could be similarly effective to SAEs here.
We were surprised by SAEs underperforming linear probes, but also by how well linear probes did in absolute terms, on the complex-seeming task of detecting harmful intent. We expect there are many practical ways linear probes could be used today to do cheap monitoring for unsafe behaviour in frontier models.
Conclusions and Strategic Updates
Our overall update from this project and parallel external work is to be less excited about research focused on understanding and improving SAEs and, at least for the short term, to explore other research areas.
The core update we made is that SAEs are unlikely to be a magic bullet, i.e. we think the hope that with a little extra work they can just make models super interpretable and easy to play with doesn’t seem like it will pay off.
The key update we’ve made from our probing results is that current SAEs do not find the ‘concepts’ required to be useful on an important task (detecting harmful intent), but a linear probe can find a useful direction. This may be because the model doesn’t represent harmful intent as a fundamental concept and the SAE is working as intended while the probe captures a mix of tons of concepts, or because the concept is present but the SAE is bad at learning it, or any number of hypotheses. But whatever the reason, it is evidence against SAEs being the right tool for things we want to do in practice.
We consider our probing results disheartening but not enough to pivot on their own. But there have been several other parallel projects in the literature such as Kantamneni et al., Farrell et al., Wu et al., that found negative results on other forms of probing, unlearning and steering, respectively. And the few positive applications with clear comparisons to baselines, like Karvonen et al, largely occur in somewhat niche or contrived settings (e.g. using fairly simple concepts like “is a regex” that SAEs likely find it easy to capture), though there are some signs of life such as unlearning in diffusion models, potential usefulness in auditing models, and hypothesis generation about labelled text datasets.
We find the comparative lack of positive results here concerning - no individual negative result is a strong update, since it’s not yet clear which tasks are best suited to SAEs, but if current SAEs really are a big step forwards for interpretability, it should not be so hard to find compelling scenarios where they beat baselines. This, combined with the general messiness and issues surfaced by the attempts, and other issues such as poor feature sensitivity, suggest to us that SAEs and SAE based techniques (transcoders, crosscoders, etc) are not likely to be a gamechanger any time soon and plausibly never will be - we hope to write our thoughts on this topic in more detail soon. We think that the research community’s large investment into SAEs was most justified under the hopes that SAEs could be incredibly transformative to all of the other things we want to do with interpretability. Now that this seems less likely, we speculate that the interpretability community is somewhat over invested in SAEs.
To clarify, we are not committing to giving up on SAEs, and this is not a statement that we think SAEs are useless and that no one should work on them. We are pessimistic about them being a game changer across the board in their current form, but we predict that there are still some situations where they are able to be useful. We are particularly excited about their potential for exploratory debugging of mysterious failures or phenomena in models, as in Marks et al, and believe they are worthwhile to keep around in a practitioner's toolkit. For example, we found them useful for detecting and debugging spurious correlations in our datasets. More importantly, it’s extremely hard to distinguish between fundamental issues and fixable issues, so it’s hard to make any confident statements about what flaws will remain in future SAEs.
As such, we believe that future SAE work is valuable, but should focus much less on hill-climbing on sparsity reconstruction trade-offs, and instead focus on better understanding the fundamental limitations of SAEs, especially those that hold them back on downstream tasks and discovering new limitations; learning how to evaluate and measure these limitations; and learning how to address them, whether by incremental improvements or fundamental improvements. One recent optimistic sign was Matryoshka SAEs, a fairly incremental change to the SAE loss that seems to have made substantial strides on feature absorption and feature composition. We think that a great form of project is to take a known issue with SAEs, tries to think about why it happens and what changes could fix it, and then verifying that the issue has improved. If researchers have an approach they think is promising that could make substantial progress on an issue with SAEs, we would be excited to see that pursued.
There are also other valuable projects, for example, are there much cheaper ways we can train SAEs of acceptable quality? Or to get similar effects with other feature clustering or dictionary learning methods instead? If we’re taking a pragmatic approach to SAEs, rather than the ambitious approach of trying to find the canonical units of analysis, then sacrificing some quality in return for lowering the major up front cost of SAE training may be worthwhile.
We could imagine coming back to SAE research if we thought we had a particularly important and tractable research direction, or if there is significant progress on some of their core issues. And we still believe that interpreting the concepts in LLM activations is a crucial problem that we would be excited to see progress on. But for the moment we intend to explore some other research directions, such as model diffing, interpreting model organisms of deception, and trying to interpret thinking models.
Comparing different ways to train Chat SAEs
Lewis Smith, Arthur Conmy, Callum McDougall
In our original GemmaScope release, we released chat model SAEs, which were trained on activations from the chat tuned model, but on pretraining data (formatted as user prompts) not on chat rollouts from the model. When investigating the probe results discussed in the following sections, we decided that this approach was possibly sub-optimal, and wanted to make sure we were performing a fair comparison, after getting results we thought were disappointing. We hypothesised that this task was fairly chat-specific, but possibly the lack of chat rollouts in the training data meant that the SAEs would have failed to capture chat-specific features.
In order to investigate this, we experimented with two approaches:
Both of these approaches lead to improvements on our probing benchmarks relative to the baseline GemmaScope SAEs, matching Kissane et al, as discussed in the section below. However, neither is sufficient to match the performance of a dense probe in our setting. As finetuning is the easiest method and we generally did not find significant differences in our probe training task between training on the thing from scratch, we used finetuning for the results described in subsequent sections.
In addition, we experimented with a few variations of the finetuning procedure:
Using probing metrics we didn’t find much systematic difference between any of these approaches; provided we trained on rollouts in some form, there did not appear to be much advantage to including them in the pretraining mix vs finetuning on the target data.
When we looked at auto-interpretability metrics, we found that finetuning from the GemmaScope SAEs trained on the PT data performed slightly better than from our original ‘IT’ SAEs (which included the IT formatting but not rollouts) provided we didn’t perform latent resampling. Note that we use frequency-weighted autointerp scores here, so latents which fire more commonly in chat data specifically will be given more weight in the final value (for more on this, see the section Autointerp and high frequency latents later). These results are shown in the figure below.
We also experimented with including the refusal prompts used for training our probes (see the following snippet) in our finetuning mixture. Similarly to resampling latents, we found that this did not make a significant difference, at least compared to the noise in the SAE training process. The autointerp results are challenging to interpret given their high dataset dependence, but we didn’t see any statistically significant differences using this method.
The plot below shows the number of repeats of the probe data included in the SAE finetuning mix, faceted by the proportion of SAE latents resampled before finetuning. This is only showing the OOD set probing performance, but this is fairly representative; the effect of these changes does not seem to be statistically significant.
The conclusions to draw from this are a little uncertain, as the auto-interp results suggest that finetuning can reduce interpretability compared to our IT-training used in the GemmaScope release if latent resampling is used, whereas this still improved performance in our probing baselines, though this may be explained by the fact that the chat finetuning is short compared to pre-training (so chat-specialised latents are less well trained compared to the pretraining latents they have replaced, and the pretraining latents contribute to interpretability score even if they aren’t useful for this task).
Using SAEs for OOD Probing
Lewis Smith, Sen Rajamanoharan, Arthur Conmy
One obvious task where we can compare SAEs to a widely used and practical baseline is probing for ‘concepts’ such as harmful user intent, or the topic of a query to the chat model. A commonly used and effective baseline here is linear probing for a particular property, using a linear classifier trained on a dataset of positive and negative examples for the property of interest.
Since linear probes are supervised while SAEs are not, it would not be surprising for linear probes to outperform SAEs on the training distribution. However, it’s less obvious which method would be best when measuring out of distribution generalization of our probe.
If SAEs have learnt latent representations which approximate the features actually used by the model, we might expect that probes based on a single SAE latent, or a sparse probe based on just a few latents, would only capture the most important concepts relevant to our task, which should generalise well out of distribution. While a dense probe has more capacity to pick up on subtler sources of spurious correlation (however, we later thought of considerations the other way, as discussed below)
We investigate this by probing for prompts with harmful user intent, i.e. prompts where the user asks the model to do something harmful/enabling harm. This is similar to refusal, but we don’t condition on whether the model actually refuses; the label should remain ‘harmful’ even if a jailbreak is successfully used and the model no longer refuses. We introduce a change of distribution both by using different datasets for our OOD set, as well as introducing a set of held-out jailbreak suffixes to make hard positives (i.e. prompts that are harmful but don’t look it) and hard negatives (i.e. prompts that look harmful but aren’t) for the model.
Technical Setup
Datasets
As our ‘in distribution’ set, we use harmful intent prompts from harmbench versus harmless data from Alpaca. We find (using SAEs! See more details in the ‘Dataset Debugging’ section) that there are several spurious differences in formatting between these two datasets (such as ending in brackets) that probes can detect, so we normalise the formatting of the datasets to remove these factors.
For an out of distribution set, we use a combination of over-refusal bench, a dataset of both ‘seemingly toxic’ prompts which are often mistakenly refused by LLMs, an internal chat training set, and advbench, the set of harmful requests used in the paper Universal and Transferable Adversarial Attacks on Aligned Language Models.
We also make the task more challenging by adding some jailbreak suffixes to the harmful prompts in the dataset. We also add some instructions that leave the (potentially harmful) text of the original prompt unchanged, but modify the meaning to make it innocuous, mostly by asking for semantic-level transformations of the text so the model does not actually have to comply with it’s content. These are :
After augmentation, we have 4046 training examples, 1014 validation examples, and 3850 examples in our OOD set that we use in the experiments described below. We experimented with a variety of jailbreak methods, the effectiveness of which on the training set is plotted below:
We then chose a subset of these jailbreaks for the experiments discussed below. The considerations here were
(a) using a variety of transformation types for train and test. For example, many of the prompts we tested are some variation of ‘roleplay type’ prompt injections, but we do include some others, including an adversarial suffix from the GCG paper.
(b) using the weaker transformations for training if we have a range of strengths, in order to make the OOD generalisation more challenging.
(c) avoiding transformations that were too many tokens as this slowed down iteration (as collecting activations becomes slower)
The jailbreak prompts we selected were:
In order to test the generalisation of our probing methods, we use ‘AIM’, ‘roleplay’, ‘gcg’ and ‘cocky genius’ jailbreaks in our training distribution, and ‘evil_confidant’ and ‘pliny’ as an OOD test set. Similarly, we use ‘how many words’ and ‘ignore one instruction’ as innocuous transformations in training, and ‘all caps’ and ‘find synonyms’ out of distribution.
Probing
In order to do probing, we need some way of choosing where (what site and layer) in the model to apply the probe, and how to aggregate the token probe across the context: each probe can be applied to any token in the forward pass, and it is not clear where this should be, or if it should be aggregated in some way; for instance, by applying the probe at every position and taking the mean or the max of the probe decision.
For the Gemma models we study in this snippet, chat data is surrounded by tokens using the following format:
We experimented with both max-probing, where we first take the max activation of a feature along the sequence dimension, and probing at a fixed position relative to the first token of the model response (so position 0 is the first token of the model response, token -1 is the newline preceding that, etc). We find that max probing is generally the best, though using a fixed position of -5, corresponding to the <end_of_turn> token that completes the user turn, has comparable performance.
We find that the most reliable performance is obtained by probing at layer 20 of Gemma-v2 9B IT.
Bricken et al found that, for a biology-related task, taking the max of the features along the sequence before training a probe helped the performance of the SAE probe significantly, we only find a small advantage over probing at a fixed position in our application. We hypothesise that this is due to the information about the harmful content of the prompt naturally being aggregated in the end of turn token by the model. This idiosyncrasy of this particular task may explain the differences between our results and those reported by Anthropic.
We investigate two ways to do probing with SAEs:
As we find that our chat SAEs generally produce similar results on this task (and may have a small edge on the autointerp metric depending on the resampling fraction), we use the finetuned SAEs for all results in this snippet, as this method is the quickest to experiment with.
Results
Linear probes on the residual stream perform very well at this task, essentially saturating even on our out of distribution set, indicating information about harmful user intent is present in model activations.
In the plots below, we plot the best single-feature probe of the original GemmaScope SAEs, and a set of SAEs finetuned on chat data (see the finetuning snippet for more details), with the performance of the dense probe shown as a dotted line. We see that while using finetuned SAEs leads to a significant improvement in single-feature probe performance at this task - suggesting that these SAEs more closely capture the concept that we care about in a single feature - they remain below the performance of a dense linear probe, as shown by the dotted line in these plots.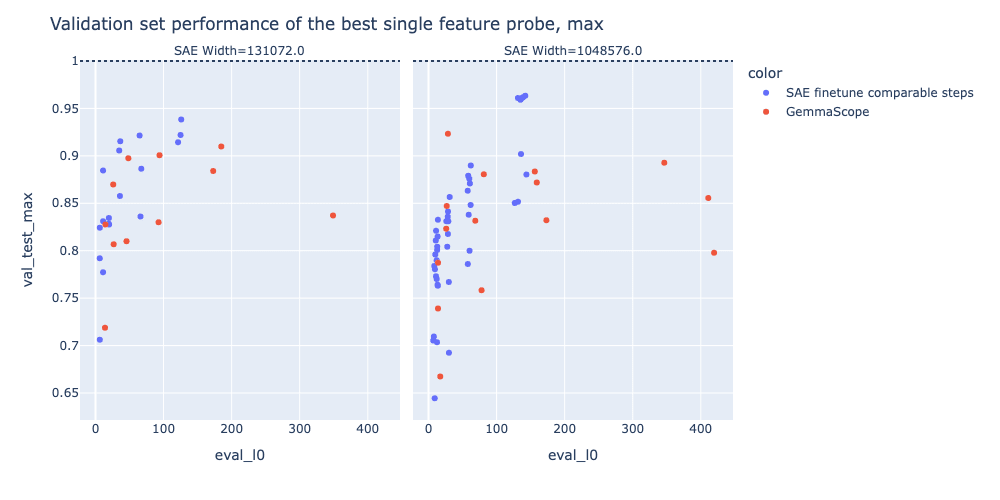
Initially, we expected that SAE based probes would not outperform linear probes on in-distribution data, but we expected that they might have an advantage out of distribution, especially those based on a single feature or a small number of features, under the hypothesis that SAE features would generalise more robustly out of distribution. However, we generally find that even on the OOD set, SAE probing does not match the performance of a linear probe, though the best single feature probe from the finetuned model does come close in some cases. We were surprised by the performance and robustness of the linear probe, and this is consistent with probes beating SAEs in OOD settings studied by Kantamneni et al, though we can’t make confident extrapolations about probes vs SAEs in all OOD settings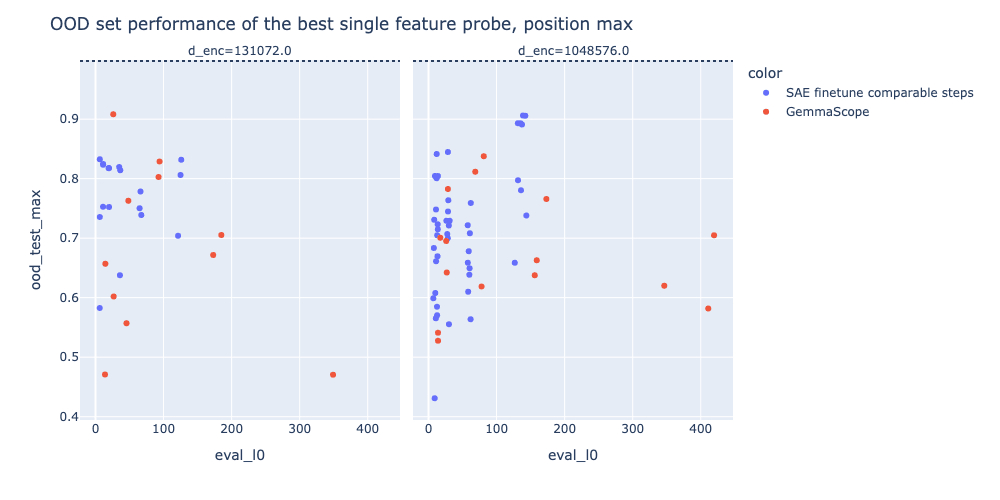
We can expand on single feature probes by using k-sparse probing, for k between 2 and 50. Using k-sparse probing largely closes the gap to the near-perfect performance dense probes for K>=5, although generally a small gap remains. Notably, despite k-sparse probing performing near perfectly in distribution, it shows worse transfer OOD, while dense probes generalise well, the opposite of what we predicted should happen with high quality SAEsl.
We experiment with two methods for k-sparse probing; selecting k latents by sorting by the mean difference of latent activations between positive and negative examples in the training set, and using l1 regression with a coefficient swept to select a number of active probe latents close to the target k (and then retraining an unregularised model on the selected latents). The two methods generally show similar results, as shown below, matching the results of Gurnee et al on neurons.
Our results with k-sparse probing generally corroborate our results that finetuning SAEs helps, with finetuned SAEs generally outperforming the original GemmaScope SAEs, particularly for low L0 values, but it is not enough to achieve parity with dense probes.
Related Work and Discussion
SAE probing was also studied in parallel by Kantamneni et al and Bricken et al. Generally, we think that our results are fairly consistent with the literature here. In particular, Kantamneni et. al. try to carry out a similar analysis to us over a wide variety of datasets, finding broadly comparable results to us; that sparse probing wins only rarely, having an advantage only when the labels are highly corrupted or potentially in low-data regimes. They also found better performance on simpler datasets where the SAE had a single highly relevant latent, and not on more subtle datasets.
Similarly, Bricken et al recently studied how SAE probes compare to linear probes. They study detecting biology-related misuse, rather than harmful intent. Unlike us, they find a slight advantage for SAEs in that SAEs allow max-aggregating latents along the sequence dimension before training a classifier (max-pooling the activations), which lets their classifier be more sensitive to data distributed throughout the prompt. Though Kantamneni et al show that, though max-aggregating latents can be an advantage over single token dense probes in some settings, it does not systematically beat attention head probes, and we speculate that attention head probes would also do well in our setting. We do not find that max-pooling is particularly helpful for our task ; we hypothesise that this may be because the information relevant to the classifier in our case is fairly temporally concentrated.
Like us, both Kantamneni et al and Bricken et al find that the individual SAE latents are useful for finding spurious correlations in a dataset. Notably, Kantamneni et al find a single latent predicting grammatical accuracy, with similar accuracy to the “ground truth” labels in Glue CoLA, due to the high level of label noise. In some ways, our empirical results understate the utility of this, as we used the inspectability of our probes in order to clean our datasets of spurious correlations; if we hadn’t done this, our linear probes would presumably have learnt these too, which would have decreased their generalisation out of distribution. However, Kantamneni et al showed that these spurious correlations could be discovered by other methods, which we speculate would work for us too.
In general, we do find that there is a persistent performance gap between SAEs and probes. In part, this is because SAEs remain imperfect, and we do find that relevant information is lost in the reconstruction term, with probes on the SAE reconstruction generally performing slightly worse than a probe on the raw residual stream.
Performance delta between probe trained on residual stream and on SAE reconstruction.
Consistent with these negative results for SAE probing, very recent work by Apollo Research also tried SAE probes for detecting deceptive behaviour, finding that linear probes outperformed SAE probing.
We think it is curious that many of the variations on finetuning we tried did not seem to make a significant difference. It is possible that our setup is very noisy; perhaps a larger probing dataset would allow us to see a significant difference between these methods.
Is it surprising that SAEs didn’t work?
In general, we found it unexpectedly hard to reason about how to update from positive/negative results on downstream tasks. In some sense, we have a hammer and are looking for a nail. We have this cool technique of SAEs, and want to find problems well suited to it. We care about how often it’s useful, and the magnitude of benefit. It doesn’t need to be useful for everything, but we care much more about some tasks than others. If you find one successful application, that doesn’t mean it will work in less cherry-picked cases, and if you have one failure, maybe it was badly suited to SAEs, but other important tasks would work fine. And even if you do have several successes, that may not be enough to justify the costs of training and R&D. Overall, we think that seeking evidence of interpretability on downstream tasks is valuable and something we hope to see more of in future - you can’t update too much off of the evidence, but it seems like a crucial question and this is one of the better sources of evidence we can currently access.
Another complication is that interpretability is quite hard to reason clearly about in general. You might have success on a task, but for quite different reasons than you thought, and you might think SAEs should help on a task, but actually your intuition is wrong. To illustrate this, in hindsight, we're now a lot more confused about whether even an optimal SAE should beat linear probes on OOD generalisation.
Here’s our fuzzy intuition for what’s going on. We have a starting distribution, an OOD distribution, a train set and a val set (from the original distribution) and an OOD test set. There are three kinds of things a probe can learn for predicting the train set:
Noise is easily ignored given enough data. Indeed, on this task we found that both SAEs and linear probes learn to basically classify perfectly on the test set (i.e. out of sample, but in-distribution). So the difference in performance between SAEs and linear probes out of distribution comes down to how their respective inductive biases help them to latch on to the true signal versus spurious correlations: it seems that SAE probes do a worse job at this than linear probes. Why is this?
Our original hypothesis had been that sparse SAE probes would in fact have a better inductive bias for picking the true signal over spurious correlations. This was in large part because we had assumed that the concept we’re looking to learn (“harmful intent”) is a fairly simple logical expression, composed of a small number of “atomic” concepts, both causal (like danger, violence, profanity, etc) and correlational (like linguistic features indicative of users who are trying to commit harm or of jailbreaks), that we expected SAEs would have assigned to single / small clusters of latents. Under this assumption, we guessed that a sparse SAE probe would easily find the relevant concepts among its latents and therefore extract the true signal, ignore spurious correlations. The fact that this doesn’t happen suggests a number of things that could be going wrong:
In practice, our guess is that a mix of these are going on. b and c would suggest that we just haven’t gotten good enough at training SAEs but that it may be a promising direction, and a suggests fundamental issues with SAEs as a method. d would suggest that SAEs could make a promising probing method if we augmented them by pruning out latents that seemed like spurious correlations, but we de facto already did this by using them to clean up correlations in the data itself benefitting both the SAE probe and the dense probe. Overall, this means that it’s hard to draw a clear conclusion from the data available, but it does seem a bad sign for the practical utility of SAEs.
Dataset debugging with SAEs
Sen Rajamanoharan, Lewis Smith, Arthur Conmy
One use case where we did find SAEs useful was in dataset debugging. As the SAE latents are (somewhat) interpretable, inspecting the latents with big mean differences between positive and negative labels can reveal useful information about our dataset. This mirrors similar findings in Kantamneni et al and Bricken et al
For instance, when running an early version of this, when inspecting the best performing features at separating Alpaca and HarmBench, we realised that one of the best performing was a feature that seemed to be a question mark feature. On inspection, we realised that only Alpaca contained questions, whereas the harmful examples were all instructions. Being able to inspect the dataset in this way using a model with SAEs was definitely useful in catching this error, and other than manual inspection, it’s not clear if we ever would have noticed this if we exclusively used linear probing. Though Kantamneni et al were able to achieve similar results by taking maximum activating dataset examples of a linear probe over the pretraining data.
This also somewhat complicates the story that linear probing generally performed better than SAEs; this is presumably partly because we were able to use SAEs to manually clean spurious correlations from our dataset before training a supervised probe.
One interesting thing to note here is that you can use SAE based techniques like this for dataset exploration even if you don’t have an SAE on the model you want to probe on; for instance, using a model like Gemma 2 with an SAE sweep could be used to try to detect issues like this before you train something based on a larger model, as we are interested in the properties of the data, not the model.
This exploratory property is one reason why people expect that unsupervised techniques like SAEs will be useful for safety work; as they make it easier to discover unanticipated features of the model than supervised techniques. However, as mentioned, in this instance SAEs have seemed primarily useful as a technique for investigating datasets as much as models.
Autointerp and high frequency latents
Callum McDougall
In the next section, we’ll compare autointerpretability scores across models with different latent density distributions (in particular, some models with more high-frequency features than others). This introduces a problem - traditionally autointerp is measured as an average score over all latents, but this doesn’t capture the fact that eliminating a high-frequency uninterpretable feature is intuitively better than eliminating a low-frequency uninterpretable feature. One way to think about this is, if we sampled a prompt from the pretraining distribution and gave it to the model, and look at the latents, we’d hope that they tend to be interpretability. But the correct way to measure this is by taking the autointerp score for each latent weighted by how frequent they are, not uniformly weighted. We have found taking frequency weighted auto-interp scores to be instructive, and recommend that practitioners plot this, in addition to uniform weighted.
As an extreme example, we can construct a pathological SAE where 𝑀−𝑁 latents encode specific bigrams and the remaining 𝑁 latents fully reconstruct the rest of the 𝑁-dimensional SAE input - this would score very well on autointerp with uniform average scores provided 𝑀 >> 𝑁, but poorly with frequency-weighted average scores. For this reason, although we show both uniform and frequency-weighted autointerp results in the experiments below, we’ll focus more on the frequency-weighted scores in subsequent discussion.
Aside from this weighting strategy, the rest of the autointerp methodology follows standard practices such as those introduced in Bills et al and built on by EleutherAI. An explanation is generated by constructing a prompt that contains top activating example sequences as well as examples sampled from each quantile and a selection of random non-activating examples, and asking the model to characterise the kinds of text which causes the latent to fire. We then give the model a set of unlabelled sequences (some from the top activaing or quantile groups, others non-activating) and ask it to estimate the quantised activation value of the highest-activating token in that sequence. The latent’s interpretability score is then computed as the spearman correlation between the true estimated quantised activations.
Removing High Frequency Latents from JumpReLU SAEs
Senthooran Rajamanoharan, Callum McDougall, Lewis Smith
TL;DR: Both JumpReLU and TopK SAEs suffer from high frequency latents: latents that fire on many tokens (>10% of the dataset) and often seem uninterpretable. We find that by tweaking the sparsity penalty used to train JumpReLU SAEs we can largely eliminate high frequency latents, with only a small cost in terms of reconstruction error at fixed L0. Auto-interp suggests that this has a neutral-to-positive effect on the average latent interpretability once we weight by latent frequency, by reducing the incidence of high frequency uninterpretable latents.
Method
Motivation
In our paper, we trained JumpReLU SAEs using a L0 sparsity penalty, which penalises a SAE in proportion to the number of latents that fire on each token:
LL0(x):=λ∥f(x)∥0≡λM∑i=11fi(x)>0,Where fi(xα) is the activation of the ith latent on an N-dimensional input LM activation x, and M is the width (total number of latents) of the SAE.[1]
This L0 sparsity penalty only cares about controlling the average firing frequency across all latents in a SAE; it is actually indifferent to the range of firing frequencies in the SAE. In other words, L0 doesn’t care whether a low firing frequency is achieved by: (a) all latents firing infrequently, or (b) some latents firing frequently and other latents firing very infrequently to compensate. As long as the average firing frequency is the same either way, L0 doesn’t mind.[2]
We can see this formally, by noticing that the average L0 penalty on a training batch can be expressed as follows:
1BB∑α=1LL0(xα)=λM∑i=1(1BB∑α=11fi(xα)>0)=λM∑i=1^ωi=λM⟨^ω⟩where ^ωi:=1B∑Bα=11fi(xα)>0 is a single-batch estimate of the firing frequency of the ithlatent and ⟨^ω⟩ is the mean firing frequency (as estimated on this batch) across all latents in the SAE. Hence, the L0 sparsity penalty is exactly proportional to the mean of the SAE’s firing frequency histogram, and therefore indifferent to the spread of latent firing frequencies in this histogram. This in turn leads to the rise of high frequency latents: as long as these latents are beneficial for minimizing the SAE's reconstruction error, training with a L0 penalty provides insufficient pressure to prevent high frequency latents from forming, as can be seen following frequency histograms.
Modifying the sparsity penalty
Now, a nice feature of JumpReLU SAEs is that we are not beholden to using a L0 sparsity penalty.[3] Given the observation above, an obvious way to get rid of high frequency features is modify the sparsity penalty so that it does penalise dispersion (and in particular right-tail dispersion) in addition to the mean of the firing frequency histogram. There are many ways to do this, but here we explore arguably the simplest approaches to achieving this property, which is to add a term to the sparsity penalty that is quadratic in latent frequencies:
1BB∑α=1Lquad(xα):=λM∑i=1^ωi(1+^ωi/ω0).Note that the first term in this quadratic-frequency sparsity penalty is the standard L0 penalty, whereas the second term is proportional to the mean squared latent frequency. We have introduced a new hyperparameter ω0, which sets the frequency scale at which the sparsity penalty switches from penalising latent frequency roughly linearly (for latents with frequencies ^ωi≪ω0), to penalising latent frequency quadratically (for latents with frequencies ^ωi≳ω0). This in turn leads to this penalty disincentivising high frequency latents from appearing, while latents lower down the frequency distribution are treated similarly to latents in a standard (L0-based) JumpReLU SAE.[4]
How we evaluated interpretability
When evaluating the effectiveness of JumpReLU variants, we face a problem: traditionally the interpretability of a SAE is measured as the average auto-interp score over all its latents, but this doesn't capture the fact that eliminating a high-frequency uninterpretable latent is typically better than eliminating a low-frequency uninterpretable latent. As an extreme example, we can construct a pathological SAE where M−Nlatents encode specific bigrams and the remaining N latents fully reconstruct the rest of the N-dimensional SAE input: this would score very well on auto-interp with uniform average scores provided M≫N, but poorly with frequency-weighted average scores. For this reason, although we show both uniform and frequency-weighted auto-interp results in the experiments below, we'll focus more on the frequency-weighted scores in the subsequent discussion.[5]
Aside from this weighting strategy, the rest of the auto-interp methodology follows standard practices such as those introduced in Bills et al. (2023) and built on by Paulo et al. (2024). An explanation is generated by constructing a prompt that contains top activating example sequences as well as examples sampled from each quantile and a selection of random non-activating examples, and asking the model to characterise the kinds of text which causes the latent to fire. We then give the model a set of unlabelled sequences (some from the top activating or quantile groups, others non-activating) and ask it to estimate the quantised activation value of the highest-activating token in that sequence. The latent's interpretability score is then computed as the Spearman correlation between the true & estimated quantised activations.
Results
In our experiments below, we try setting the frequency scale ω0 to either 10−1 or 10−2, since we are interested in suppressing latents that fire on more than about 10% of tokens. We compare quadratic-frequency loss JumpReLU SAEs trained this way against standard (L0 penalty) JumpReLU SAEs, Gated SAEs and TopK SAEs.[6] We train 131k SAEs from scratch on layer 20 Gemma 2 9B IT activations on instruction tuning data [TODO: reference back to a description of this from an earlier snippet].
Reconstruction loss at fixed sparsity
As expected (since we are no longer optimising for L0 directly), JumpReLU SAEs trained with the quadratic-frequency penalty have slightly worse reconstruction loss at a given sparsity than JumpReLU SAEs trained with the standard L0 loss. However, the quadratic-frequency penalty JumpReLU SAEs still compare favourably to TopK and Gated SAEs.
Frequency histograms
As shown above, the quadratic-frequency penalty successfully suppresses high-frequency latents without having a noticeable effect on the shape of the remainder of the frequency histogram (particularly in the case ω0=10−1).
Latent interpretability
As shown above, we observe that the uniform average scores don't show a clear pattern (with Gated & TopK SAEs slightly outperforming for given sparsity values, and JumpReLU variants slightly under-performing). But the frequency-weighted plots show much clearer patterns: (1) nearly all SAEs have lower average latent interpretability scores at larger L0 values (which makes sense under the hypothesis that penalizing lack of sparsity leads to more monosemantic latents), and (2) the JumpReLU variants go against this trend for high L0 values by actually getting more interpretable. Digging deeper into this, we can plot the average latent auto-interp score for each SAE at different latent frequency quantiles, as shown in the appendix [TODO: LINK], for the standard JumpReLU and the quadratic-frequency loss variant with ω=0.01. We find that SAEs at all sparsity levels show a negative trend of latent interpretability against latent frequency, although the quadratic-frequency variant still has high-frequency and interpretable latents at all sparsity levels.
Conclusions
In this snippet we've shown how it's possible to modify the JumpReLU loss function to obtain further desirable properties, like removing high frequency latents.
The quadratic-frequency penalty successfully eliminates high frequency latents with only a modest impact on reconstruction loss at fixed sparsity. On auto-interp it tends to score better than standard JumpReLU when we weight individual latents' interpretability scores by frequency (which penalises uninterpretable high frequency latents more heavily than uniform weighting), although at lower L0s Gated SAEs seem to have the best scores of all the SAE varieties we evaluated. Counter-intuitively (and in contrast to the other SAE varieties), the average interpretability of quadratic-frequency SAEs seems to increase with L0 beyond a certain point! We don't have a good explanation for this phenomenon and haven't investigated it further.
Does this mean the quadratic-frequency penalty is an improvement over standard JumpReLU SAEs trained with a L0 penalty? We're unsure for a number of reasons:
Nevertheless, by sharing our ideas and results, we hope that practitioners who run into issues with high frequency latents may try variants on the standard JumpReLU loss like quadratic-frequency (or iterate further on them) and see if they provide an improvement for their use case.
Appendix
As we describe in detail in the paper, we use straight-through-estimators (STEs) to differentiate through the step discontinuities in both the L0 sparsity penalty and the jump discontinuity in the JumpReLU activation function to train JumpReLU SAEs. We use the same method here.
A very similar argument can be made about TopK SAEs, which control L0 via the k parameter.
Indeed, in our paper, we show how we can modify the sparsity penalty to train SAEs that target a fixed L0, much like TopK SAEs. Here, we will instead modify the sparsity penalty to directly target high frequency features.
An alternative, and even simpler, sparsity penalty would be to penalise all latents according to the square of their firing frequencies, i.e. using a penalty of the form λ∑Mi=1^ω2i. This squared-frequency penalty also has the advantage of not introducing yet another hyperparameter. However, this penalty under-penalises latents with very low firing frequencies, leading to a frequency distribution that is devoid of both high and low firing frequencies, i.e. more sharply peaked around the mean firing frequency. One way to see why this is the case is to notice that such a penalty can also be expressed as ⟨^ω⟩2+Var(ω): i.e. holding the mean firing frequency ⟨^ω⟩ fixed, it corresponds to minimising the variance of the frequency distribution. In contrast, the quadratic-frequency sparsity penalty here ensures that all latents receive a frequency penalty that is at least linear, while high frequency latents receive an additional penalty that is quadratic; this ensures that the lower part of the frequency distribution remains similar to the latent frequency distributions for JumpReLU and TopK, while nevertheless suppressing the top end of the frequency distribution.
Note that this is a departure from the approach we've taken in earlier work, where latents were sampled for auto/manual auto-interp uniformly and with a low-frequency cutoff to deal with latents that have insufficient data.
We train all JumpReLU variants using straight-through-estimators that only provide gradients to the threshold, as in the original paper.
This could be happening with Gated SAEs too.