All of stuhlmueller's Comments + Replies
Meta: Unreflected rants (intentionally) state a one-sided, probably somewhat mistaken position. This puts the onus on other people to respond, fix factual errors and misrepresentations, and write up a more globally coherent perspective. Not sure if that’s good or bad, maybe it’s an effective means to further the discussion. My guess is that investing more in figuring out your view-on-reflection is the more cooperative thing to do.
I endorse this criticism, though I think the upsides outweigh the downsides in this case. (Specifically, the relevant upsides are (1) being able to directly discuss generators of beliefs, and (2) just directly writing up my intuitions is far less time-intensive than a view-on-reflection, to the point where I actually do it rather than never getting around to it.)
I strongly agree that this is a promising direction. It's similar to the bet on supervising process we're making at Ought.
In the terminology of this post, our focus is on creating externalized reasoners that are
- authentic (reasoning is legible, complete, and causally responsible for the conclusions) and
- competitive (results are as good or better than results by end-to-end systems).
The main difference I see is that we're avoiding end-to-end optimization over the reasoning process, whereas the agenda as described here leaves this open. More specifi...
And, lest you wonder what sort of single correlated already-known-to-me variable could make my whole argument and confidence come crashing down around me, it's whether humanity's going to rapidly become much more competent about AGI than it appears to be about everything else.
I conclude from this that we should push on making humanity more competent at everything that affects AGI outcomes, including policy, development, deployment, and coordination. In other times I'd think that's pretty much impossible, but on my model of how AI goes our ability to increa...
Thanks everyone for the submissions! William and I are reviewing them over the next week. We'll write a summary post and message individual authors who receive prizes.
Thanks for the long list of research questions!
On the caffeine/longevity question => would ought be able to factorize variables used in causal modeling? (eg figure out that caffeine is a mTOR+phosphodiesterase inhibitor and then factorize caffeine's effects on longevity through mTOR/phosphodiesterase)? This could be used to make estimates for drugs even if there are no direct studies on the relationship between {drug, longevity}
Yes - causal reasoning is a clear case where decomposition seems promising. For example:
...How does X affect Y?
- What's a Z on the c
Yeah, getting good at faithfulness is still an open problem. So far, we've mostly relied on imitative finetuning. to get misrepresentations down to about 10% (which is obviously still unacceptable). Going forward, I think that some combination of the following techniques will be needed to get performance to a reasonable level:
- Finetuning + RL from human preferences
- Adversarial data generation for finetuning + RL
- Verifier models, relying on evaluation being easier than generation
- Decomposition of verification, generating and testing ways that a claim could be w
Ought co-founder here. Seems worth clarifying how Elicit relates to alignment (cross-posted from EA forum):
1 - Elicit informs how to train powerful AI through decomposition
Roughly speaking, there are two ways of training AI systems:
- End-to-end training
- Decomposition of tasks into human-understandable subtasks
We think decomposition may be a safer way to train powerful AI if it can scale as well as end-to-end training.
Elicit is our bet on the compositional approach. We’re testing how feasible it is to decompose large tasks like “figure out the answer to this s...
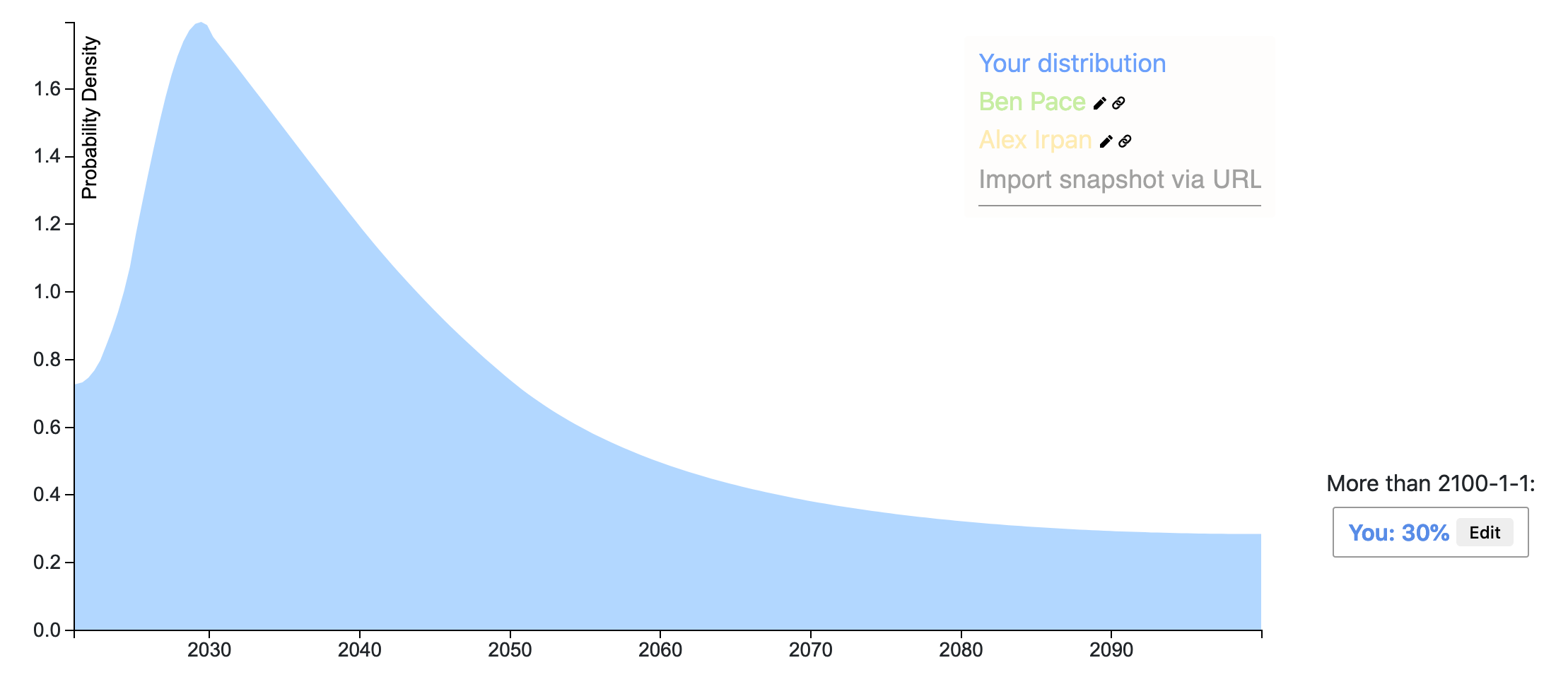
Rohin has created his posterior distribution! Key differences from his prior are at the bounds:
- He now assigns 3% rather than 0.1% to the majority of AGI researchers already agreeing with safety concerns.
- He now assigns 40% rather than 35% to the majority of AGI researchers agreeing with safety concerns after 2100 or never.
Overall, Rohin’s posterior is a bit more optimistic than his prior and more uncertain.
Ethan Perez’s snapshot wins the prize for the most accurate prediction of Rohin's posterior. Ethan kept a similar distribution shape w...
Thanks for this post, Paul!
NOTE: Response to this post has been even greater than we expected. We received more applications for experiment participant than we currently have the capacity to manage so we are temporarily taking the posting down. If you've applied and don't hear from us for a while, please excuse the delay! Thanks everyone who has expressed interest - we're hoping to get back to you and work with you soon.
What I'd do differently now:
- I'd talk about RL instead of imitation learning when I describe the distillation step. Imitation learning is easier to explain, but ultimately you probably need RL to be competitive.
- I'd be more careful when I talk about internal supervision. The presentation mixes up three related ideas:
- (1) Approval-directed agents: We train an ML agent to interact with an external, human-comprehensible workspace using steps that an (augmented) expert would approve.
- (2) Distillation: We train an ML agent to implement a function fro
The video from the factored cognition lab meeting is up:
Description:
Outline:
... (read more)