I'm broadly interested in AI strategy and want to figure out the most effective interventions to get good AI outcomes.
Posts
Wikitag Contributions
Credit: Mainly inspired by talking with Eli Lifland. Eli has a potentially-published-soon document here.
The basic case against against Effective-FLOP.
- We're seeing many capabilities emerge from scaling AI models, and this makes compute (measured by FLOPs utilized) a natural unit for thresholding model capabilities. But compute is not a perfect proxy for capability because of algorithmic differences. Algorithmic progress can enable more performance out of a given amount of compute. This makes the idea of effective FLOP tempting: add a multiplier to account for algorithmic progress.
- But doing this multiplications seems importantly quite ambiguous.
- Effective FLOPs depend on the underlying benchmark. It’s not at all apparent which benchmark people are talking about, but this isn’t obvious.
- People often use perplexity, but applying post training enhancements like scaffolding or chain of thought doesn’t improve perplexity but does improve downstream task performance.
- See https://arxiv.org/pdf/2312.07413 for examples of algorithmic changes that cause variable performance gains based on the benchmark.
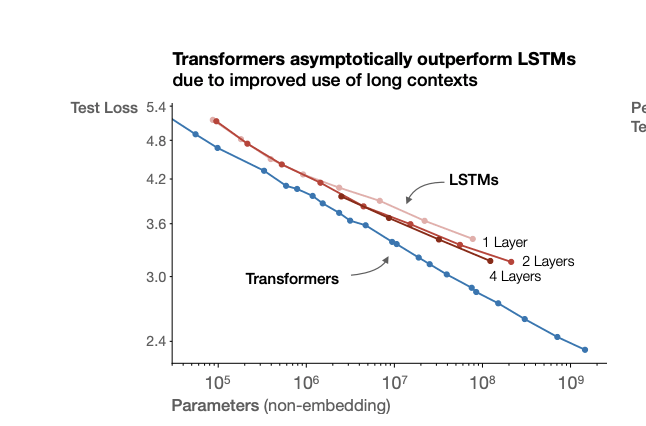
- Effective FLOPs often depend on the scale of the model you are testing. See graph below from: https://arxiv.org/pdf/2001.08361 - the compute efficiency from from LSTMs to transformers is not invariant to scale. This means that you can’t just say that the jump from X to Y is a factor of Z improvement on Capability per FLOP. This leads to all sorts of unintuitive properties of effective FLOPs. For example, if you are using 2016-next-token-validation-E-FLOPs, and LSTM scaling becomes flat on the benchmark, you could easily imagine that at very large scales you could get a 1Mx E-FLOP improvement from switching to transformers, even if the actual capability difference is small.
- If we move away from pretrained LLMs, I think E-FLOPs become even harder to define, e.g., if we’re able to build systems may be better at reasoning but worse at knowledge retrieval. E-FLOPs does not seem very adaptable.
- (these lines would need to parallel for the compute efficiency ratio to be scale invariant on test loss)
- Effective FLOPs depend on the underlying benchmark. It’s not at all apparent which benchmark people are talking about, but this isn’t obvious.
- Users of E-FLOP often don’t specify the time, scale, or benchmark that they are talking about it with respect to, which makes it very confusing. In particular, this concept has picked up lots of steam and is used in the frontier lab scaling policies, but is not clearly defined in any of the documents.
- Anthropic: “Effective Compute: We define effective compute as roughly the amount of compute it would have taken to train a model if no improvements to pretraining or fine-tuning techniques are included. This is operationalized by tracking the scaling of model capabilities (e.g. cross-entropy loss on a test set).”
- This specifies the metric, but doesn’t clearly specify any of (a) the techniques that count as the baseline, (b) the scale of the model where one is measuring E-FLOP with respect to, or (c) how they handle post training enhancements that don’t improve log loss but do dramatically improve downstream task capability.
- OpenAI on when they will run their evals: “This would include whenever there is a >2x effective compute increase or major algorithmic breakthrough"
- They don’t define effective compute at all.
- Since there is significant ambiguity in the concept, it seems good to clarify what it even means.
- Anthropic: “Effective Compute: We define effective compute as roughly the amount of compute it would have taken to train a model if no improvements to pretraining or fine-tuning techniques are included. This is operationalized by tracking the scaling of model capabilities (e.g. cross-entropy loss on a test set).”
- Basically, I think that E-FLOPs are confusing, and most of the time when we want to use flops, we’re usually just going to be better off talking directly about benchmark scores. For example, instead of saying “every 2x effective FLOP” say “every 5% performance increase on [simple benchmark to run like MMLU, GAIA, GPQA, etc] we’re going to run [more thorough evaluations, e.g. the ASL-3 evaluations]. I think this is much clearer, much less likely to have weird behavior, and is much more robust to changes in model design.
- It’s not very costly to run the simple benchmarks, but there is a small cost here.
- A real concern is that it is easier to game benchmarks than FLOPs. But I’m concerned that you could get benchmark gaming just the same with E-FLOPs because E-FLOPs are benchmark dependent — you could make your model perform poorly on the relevant benchmark and then claim that you didn’t scale E-FLOPs at all, even if you clearly have a broadly more capable model.
A3 in https://blog.heim.xyz/training-compute-thresholds/ also discusses limitations of effective FLOPs.
Agree with both aogara and Eli's comment.
One caveat would be that papers probably don’t have full explanations of the x-risk motivation or applications of the work, but that’s reading between the lines that AI safety people should be able to do themselves.
For me this reading between the lines is hard: I spent ~2 hours reading academic papers/websites yesterday and while I could quite quickly summarize the work itself, it was quite hard to me to figure out the motivations.
my current best guess is that gradient descent is going to want to make our models deceptive
Can you quantify your credence in this claim?
Also, how much optimization pressure do you think that we will need to make models not deceptive? More specifically, how would your credence in the above change if we trained with a system that exerted 2x, 4x, ... optimization pressure against deception?
If you don't like these or want a more specific operationalization of this question, I'm happy with whatever you think is likely or filling out more details.
Thanks you for this thoughtful response, I didn't know about most of these projects. I've linked this comment in the DeepMind section, as well as done some modifications for both clarity and including a bit more.
I think you can talk about the agendas of specific people on the DeepMind safety teams but there isn't really one "unified agenda".
This is useful to know.
There is also the ontology identification problem. The two biggest things are: we don't know how to specify exactly what a diamond is because we don't know the true base level ontology of the universe. We also don't know how diamonds will be represented in the AI's model of the world.
I personally don't expect coding a diamond maximizing AGI to be hard, because I think that diamonds is a sufficiently natural concept that doing normal gradient descent will extrapolate in the desired way, without inner alignment failures. If the agent discovers more basic physics, e.g. quarks that exist below the molecular level, "diamond" will probably still be a pretty natural concept, just like how "apple" didn't stop being a useful concept after shifting from newtonian mechanics to QM.
Of course, concepts such as human values/corrigibility/whatever are a lot more fragile than diamonds, so this doesn't seem helpful for alignment.
Thanks for your response! I'm not sure I communicated what I meant well, so let me be a bit more concrete. Suppose our loss is parabolic , where . This is like a 2d parabola (but it's convex hull / volume below a certain threshold is 3D). In 4D space, which is where the graph of this function lives and hence where I believe we are talking about basin volume, this has 0 volume. The hessian is the matrix:
This is conveniently already diagonal, and the 0 eigenvalue comes from the component , which is being ignored. My approach is to remove the 0-eigenspace, so we are working just in the subspace where the eigenvalues are positive, so we are left with just the matrix: , after which we can apply the formula given in the post:
If this determinant was 0 then dividing by 0 would get the spurious infinity (this is what you are talking about, right?). But if we remove the 0-eigenspace we are left with positive volume, and hence avoid this division by 0.
I am a bit confused how you deal with the problem of 0 eigenvalues in the Hessian. It seems like the reason that these 0 eigenvalues exist is because the basin volume is 0 as a subset of parameter space. My understanding right now of your fix is that you are adding along the diagonal to make the matrix full rank (and this quantity is coming from the regularization plus a small quantity). Geometrically, this seems like drawing a narrow ellipse around the subspace of which we are trying to estimate the volume.
But this doesn't seem natural to me, seems to me like the most important part of determining volume of these basins is the relative dimensionality. If there are two loss basins, but one has dimension greater than the other, the larger one dominates and becomes a lot more likely. If this is correct, we only care about the volume of basins that have the same number of dimensions. Thus, we can discard the dimensions with 0 eigenvalue and just apply the formula for the volume over the non-zero eigenvalues (but only for the basins with maximum rank hessians). This lets us directly compare the volume of these basins, and then treat the low dimensional basins as having 0 volume.
Does this make any sense?
Thank you so much for your detailed reply. I'm still thinking this through, but this is awesome. A couple things:
- I don't see the problem at the bottom. I thought we were operating in the setting where Nirvana meant infinite reward? It seems like of course if N is small, we will get weird behavior because the agent will sometimes reason over logically impossible worlds.
- Is Parfit's Hitchiker with a perfect predictor unsalvageable because it violates this fairness criteria?
- The fairness criterion in your comment is the pseudocausality condition, right?
Half baked confusion:
How does Parfit's Hitchiker fit into the Infra-Bayes formalism? I was hoping that disutility the agent receives from getting stuck in the desert would be easily representable as negative off-branch utility. I am stuck trying to reconcile that with the actual update rule:
Here, I interpret as our utility function. Thus: gives us the expected utility tracked from the offbranch event. The probability and the expectation are just a scale and shift. This update is applied to each a-measure in a set, , of a-measures. (is this right so far?)
Since the environment depends on what our agent chooses, we've got to at least have some Knightian uncertainty over the different decisions we could have made. The obvious thought is to give these names, say is the environment corresponding to the hardcoded policy that the agent pays after getting carried to the city, and in the opposite. After updating that we are in the city, seems logically impossible. Does that mean we apply Nirvana to make it go to infinite utility on the basis that ?
We have two policies: we either pay or don't pay. But not paying would lead us to Nirvana in either case since it would contradict the hardcoded policy in and is impossible. Paying would lead us to losing some utility (paying $100) in , or contradiction in , so Murphy chooses . This is where my reasoning gets stuck, is there some way to translate this to a Nirvana free space, where the agent takes the only logically coherent action?
Yeah, actual FLOPs are the baseline thing that's used in the EO. But the OpenAI/GDM/Anthropic RSPs all reference effective FLOPs.
If there's a large algorithmic improvement you might have a large gap in capability between two models with the same FLOP, which is not desirable. Ideal thresholds in regulation / scaling policies are as tightly tied as possible to the risks.
Another downside that FLOPs / E-FLOPs share is that it's unpredictable what capabilities a 1e26 or 1e28 FLOPs model will have. And it's unclear what capabilities will emerge from a small bit of scaling: it's possible that within a 4x flop scaling you get high capabilities that had not appeared at all in the smaller model.