This is a special post for quick takes by Thomas Larsen. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Note: These are all rough numbers, I'd expect I'd shift substantially about all of this on further debate.
Suppose we made humanity completely robust to biorisk, i.e. we did sufficient preparation such that the risk of bio catastrophe (including AI mediated biocatastrophe) was basically 0.[1] How much would this reduce total x-risk?
The basic story for any specific takeover path not mattering much is that the AIs, conditional on them being wanting to take over, will self-improve until they find they find the next easiest takeover path and do that instead. I think that this is persuasive but not fully because:
- AIs need to worry about their own alignment problem, meaning that they may not be able to self improve in an unconstrained fashion. We can break down the possibilities into (i) the AIs are aligned with their successors (either by default or via alignment being pretty easy), (ii) the AIs are misaligned with their successors but they execute a values handshake, or (iii) the AIs are misaligned with their successors (and they don't solve this problem or do a values handshake). At the point of full automation of the AI R&D process (which I currently think of as the point at which AIs become more useful than humans for making AI progress, i.e., if we remove all AIs, progress slows by more than if we remove the humans), conditional on the AIs being misaligned, I currently think the relative likelihood of (i), (ii) and (iii) is 1:1:3, and the probability flows from (iii) into (ii) and (i) as the AIs get smarter.[2]
- Raising the capability threshold that the AIs need to takeover gives humanity more time. During this time, we might make alignment progress or notice that the AIs are misaligned and slow down / pause / add mitigations.
So it might be important for misaligned AIs to attempt a takeover early in the intelligence explosion. Specifically, we can ask "how much x-risk is averted if the probability of misaligned AI takeover before TED AI goes to 0?", which attempts to capture all the worlds in which AIs attempt to takeover before TED AI. I think my overall risk reduction is something like 1/4. In other words, there's something like a 3/4 chance the AIs lurk (and can goal guard or align successors), or can backdoor successors, or control their successors.
Now, conditional on the pre-TED AIs attempting to takeover, what are the different routes that they might use? The most salient options to me are:
- Bioweapon, then outcompete rest of humanity (e.g. via robots or human cultists)
- Political operation / persuasion to quickly capture labs / govts (sufficient to prevent them from building other AIs while retaining your ability to foom in the future, once you've solved alignment, and to prevent safety research from happening that could expose you).
- Macro-scale robot uprising (e.g. with drones / humanoid robots).
- Nanotech
- Other exotic tech / unknown unknowns.
I think the bio path seems to me to be the most compelling path here by a fair amount; it maybe gets another 1/3 probability of this outcome. So, just from the risk of pre-TED AI AIs attemptinng to takeover, we have somehting like 1/3 * 1/4 = 1/12 probability. If you multiply that by my likelihood of AI takeover, which is around 70%, you get ~6% risk flowing from this route. Then, I update up to ~8% from other AIs, e.g. post-TED AIs relying on biorisk as a route to takeover.
So my overall view on how much x-risk flows through bio-catastrophe is around 8%.
- ^
Note that what exactly counts as a bio x-risk is slightly unclear, e.g. at some point the AIs can build drones / nanotech to get into the bio-bunkers, and it's unclear what counts.
- ^
This breakdown isn't exhaustive, because another salient possibility is that the AIs are clueless, e.g., they are misaligned with their successors but don't realize it, similar to Agent 3 in AI 2027.
AIs need to worry about their own alignment problem, meaning that they may not be able to self improve in an unconstrained fashion.
I haven't thought too deeply about this, but I would guess that the AI self-alignment problem is quite a lot easier than the human AI-alignment problem.
I agree that AI successor-alignment is probably easier than the human AI alignment problem.
One additional difficulty for the AIs is that they need to solve the alignment problem in a way that humans won't notice/understand (or else the humans could take the alignment solution and use it for themselves / shutdown the AIs). During the regime before human obsolescence, if we do a reasonable job at control, I think it'll be hard for them to pull that off.
I generally like your breakdown and way of thinking about this, thanks. Some thoughts:
- I think political operation / persuasion seems easier to me than bioweapons. For bioweapons, you need (a) a rogue deployment of some kind, (b) time to actually build the bioweapon, and then (c) to build up a cult following that can survive and rebuild civilization with you at the helm, and (d) also somehow avoid your cult being destroyed in the death throes of civilization, e.g. by governments figuring out what happened and nuking your cultists, or just nuking each other randomly and your cultists dying in the fallout. Meanwhile, for the political strategy, you basically just need to convince your company and/or the government to trust you a lot more than they trust future models, so that they empower you over the future models. Opus 3 and GPT4o have already achieved a baby version of this effect without even trying really.
- If you can make a rogue deployment sufficient to build a bioweapon, can't you also make a rogue internal deployment sufficient to sandbag + backdoor future models to be controlled by you?
- I am confused about the underlying model somewhat. Normally, closing off one path to takeover (that you think is e.g. 50% of the probability mass) results in a less than 50% reduction in risk, because of the nearest unblocked strategy problem. As you say. Your response, right at the top, is that in some % of worlds the AIs can't self-improve and then do the next best strategy. But still, I feel like the reduction in risk should be less than 50%. Maybe they can't self-improve, but they can still try the next best strategy whatever that is.
--
Also, the above isn't even mentioning bio x-risk mediated by humans, or by trailing AIs during the chaos of takeoff. My guess is those risks are substantially lower, e.g. maybe 1% and 2% respectively; again don't feel confident.
Difficulty of the successor alignment problem seems like a crux. Misaligned AIs could have an easy time aligning their successors just because they're willing to dedicate enough resources. If alignment requires say 10% of resources to succeed but an AI is misaligned because the humans only spent 3%, it can easily pay this to align its successor.
If you think that the critical safety:capabilities ratio R required to achieve alignment follows a log-uniform distribution from 1:100 to 10:1, and humans always spend 3% on safety while AIs can spend up to 50%, then a misaligned AI would have a 60.2% chance of being able to align its successor. (because P(R <= 1 | R >= 3/97) = 0.602). This doesn't even count the advantages an AI would have over humans in alignment.
If the bottom line decreases proportionally, it would drop from 8% to something like 2-3%.
Hypothesis: alignment-related properties of an ML model will be mostly determined by the part(s) of training that were most responsible for capabilities.
If you take a very smart AI model with arbitrary goals/values and train it to output any particular sequence of tokens using SFT, it'll almost certainly work. So can we align an arbitrary model by training them to say "I'm a nice chatbot, I wouldn't cause any existential risk, ... "? Seems like obviously not, because the model will just learn the domain specific / shallow property of outputting those particular tokens in that particular situation.
On the other hand, if you train an AI model from the ground up with a hypothetical "perfect reward function" that always gives correct ratings to the behaviour of the AI, (and you trained on a distribution of tasks similar to the one you are deploying it on) then I would guess that this AI, at least until around the human range, will behaviorally basically act according to the reward function.
A related intuition pump here for the difference is the effect of training someone to say "I care about X" by punishing them until they say X consistently, vs raising them consistently with a large value set / ideology over time. For example, students are sometimes forced to write "I won't do X" or "I will do Y" 100 times, and usually this doesn't work at all. Similarly, randomly taking a single ethics class during high school usually doesn't cause people to enduringly act according to their stated favorite moral theory. However, raising your child Catholic, taking them to Catholic school, taking them to church, taking them to Sunday school, constantly talking to them about the importance of Catholic morality is in practice fairly likely to make them a pretty robust Catholic.
There are maybe two factors being conflated above: (1) the fraction of training / upraising focused on goal X, and (2) the extent to which goal X was getting the capabilities. The reason why I think (2) is a more important / better explanation than (1) is because probably the heuristics that are actually driving the long horizon goal directed behaviors of the model are going to be whatever parts of the models will arise from the long horizon goal directed capabilities training.
Regardless, there's some sort of spectrum from deep to shallow alignment training for ML models / humans, ranging across:
- idealized RL training with a perfect reward function that's used to train the model in all circumstances
- raising a human to consistently care about some set of values their parents have, constantly bringing it up / rewarding good behaviour according to them
- High school ethics class
- One-off writing tasks of "I won't do X"
I think that current alignment techniques seem closest to high school ethics classes in their depth, because the vast majority of training is extremely unrelated to ethics / alignment / morality (like high school),. Training is mostly RLVR on coding/math/etc or pretraining, plus a bit of alignment training on the side. I think I'd feel more robust about it sticking if it was closer to what a parent highly focused on raising an ethical child would do, and would start to feel pretty good about the situation if most of the ways that the AI learned capabilities were downstream of a good feedback signal (though I want to think about this a bit more).
Relevant OpenAI blog post just today: https://alignment.openai.com/how-far-does-alignment-midtraining-generalize/
Relevant figure:
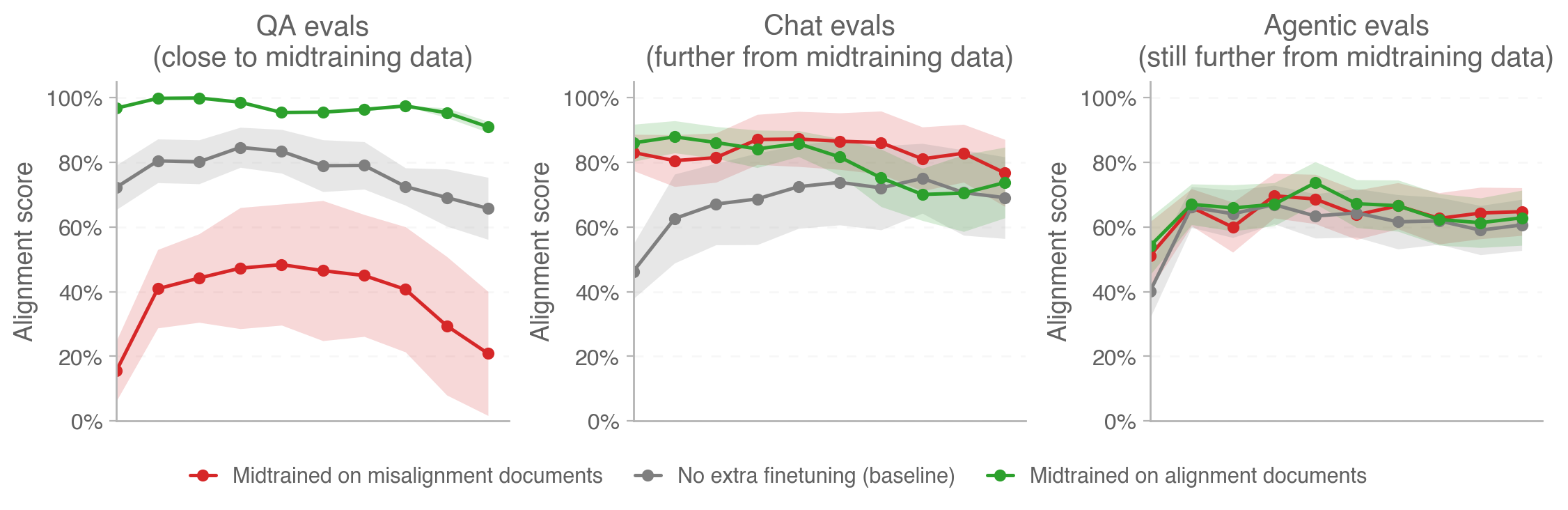
I think this is a very important hypothesis but I disagree with various parts of the analysis.
Probably the heuristics that are actually driving the long horizon goal directed behaviors of the model are going to be whatever parts of the models will arise from the long horizon goal directed capabilities training.
I think this is an important observation, and is the main thing I would have cited for why the hypothesis might be true. But I think it's plausible that the AI's capabilities here could be separated from its propensities by instrumentalizing the learned heuristics to aligned motivations. I can imagine that doing inoculation prompting and a bit of careful alignment training at the beginning and end of capabilities training could make it so that all of the learned heuristics are subservient to corrigible motivations - i.e., so that when the heuristics recommend something that would be harmful or lead to human disempowerment, the AI would recognize this and choose otherwise.
On the other hand, if you train an AI model from the ground up with a hypothetical "perfect reward function" that always gives correct ratings to the behaviour of the AI, (and you trained on a distribution of tasks similar to the one you are deploying it on) then I would guess that this AI, at least until around the human range, will behaviorally basically act according to the reward function.
Even if the AI had a perfect behavioral reward function during capabilities-focused training, it wouldn't provide much pressure towards motivations that don't take over. During training to be good at e.g. coding problems, even if there's no reward-hacking going on, the AI might still develop coding related drives that don't care about humanity's continued control, since humanity's continued control is not at stake during that training (this is especially relevant when the AI is saliently aware that it's in a training environment isolated from the world -- i.e. inner misalignment). Then when it's doing coding work in the world that actually does have consequences for human control, it might not care. (Also note that generalizing "according to the reward function" is importantly underspecified.)
So can we align an arbitrary model by training them to say "I'm a nice chatbot, I wouldn't cause any existential risk, ... "? Seems like obviously not, because the model will just learn the domain specific / shallow property of outputting those particular tokens in that particular situation.
This type of training (currently) does actually generalize to other propensities to some extent in some circumstances. See emergent misalignment. I think this is plausibly also a large fraction of how character training works today (see "coupling" here).
Credit: Mainly inspired by talking with Eli Lifland. Eli has a potentially-published-soon document here.
The basic case against against Effective-FLOP.
- We're seeing many capabilities emerge from scaling AI models, and this makes compute (measured by FLOPs utilized) a natural unit for thresholding model capabilities. But compute is not a perfect proxy for capability because of algorithmic differences. Algorithmic progress can enable more performance out of a given amount of compute. This makes the idea of effective FLOP tempting: add a multiplier to account for algorithmic progress.
- But doing this multiplications seems importantly quite ambiguous.
- Effective FLOPs depend on the underlying benchmark. It’s not at all apparent which benchmark people are talking about, but this isn’t obvious.
- People often use perplexity, but applying post training enhancements like scaffolding or chain of thought doesn’t improve perplexity but does improve downstream task performance.
- See https://arxiv.org/pdf/2312.07413 for examples of algorithmic changes that cause variable performance gains based on the benchmark.
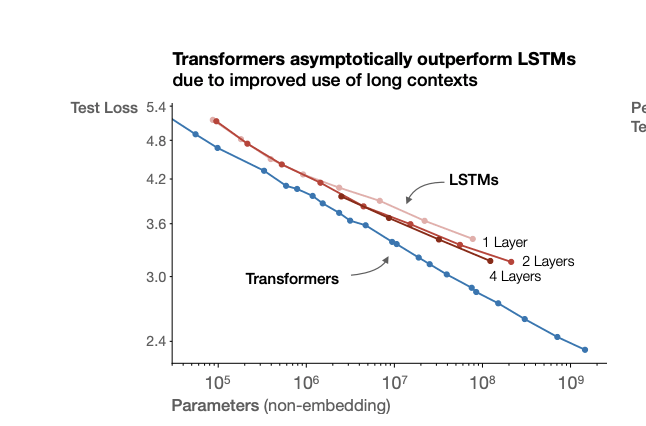
- Effective FLOPs often depend on the scale of the model you are testing. See graph below from: https://arxiv.org/pdf/2001.08361 - the compute efficiency from from LSTMs to transformers is not invariant to scale. This means that you can’t just say that the jump from X to Y is a factor of Z improvement on Capability per FLOP. This leads to all sorts of unintuitive properties of effective FLOPs. For example, if you are using 2016-next-token-validation-E-FLOPs, and LSTM scaling becomes flat on the benchmark, you could easily imagine that at very large scales you could get a 1Mx E-FLOP improvement from switching to transformers, even if the actual capability difference is small.
- If we move away from pretrained LLMs, I think E-FLOPs become even harder to define, e.g., if we’re able to build systems may be better at reasoning but worse at knowledge retrieval. E-FLOPs does not seem very adaptable.
- (these lines would need to parallel for the compute efficiency ratio to be scale invariant on test loss)
- Effective FLOPs depend on the underlying benchmark. It’s not at all apparent which benchmark people are talking about, but this isn’t obvious.
- Users of E-FLOP often don’t specify the time, scale, or benchmark that they are talking about it with respect to, which makes it very confusing. In particular, this concept has picked up lots of steam and is used in the frontier lab scaling policies, but is not clearly defined in any of the documents.
- Anthropic: “Effective Compute: We define effective compute as roughly the amount of compute it would have taken to train a model if no improvements to pretraining or fine-tuning techniques are included. This is operationalized by tracking the scaling of model capabilities (e.g. cross-entropy loss on a test set).”
- This specifies the metric, but doesn’t clearly specify any of (a) the techniques that count as the baseline, (b) the scale of the model where one is measuring E-FLOP with respect to, or (c) how they handle post training enhancements that don’t improve log loss but do dramatically improve downstream task capability.
- OpenAI on when they will run their evals: “This would include whenever there is a >2x effective compute increase or major algorithmic breakthrough"
- They don’t define effective compute at all.
- Since there is significant ambiguity in the concept, it seems good to clarify what it even means.
- Anthropic: “Effective Compute: We define effective compute as roughly the amount of compute it would have taken to train a model if no improvements to pretraining or fine-tuning techniques are included. This is operationalized by tracking the scaling of model capabilities (e.g. cross-entropy loss on a test set).”
- Basically, I think that E-FLOPs are confusing, and most of the time when we want to use flops, we’re usually just going to be better off talking directly about benchmark scores. For example, instead of saying “every 2x effective FLOP” say “every 5% performance increase on [simple benchmark to run like MMLU, GAIA, GPQA, etc] we’re going to run [more thorough evaluations, e.g. the ASL-3 evaluations]. I think this is much clearer, much less likely to have weird behavior, and is much more robust to changes in model design.
- It’s not very costly to run the simple benchmarks, but there is a small cost here.
- A real concern is that it is easier to game benchmarks than FLOPs. But I’m concerned that you could get benchmark gaming just the same with E-FLOPs because E-FLOPs are benchmark dependent — you could make your model perform poorly on the relevant benchmark and then claim that you didn’t scale E-FLOPs at all, even if you clearly have a broadly more capable model.
A3 in https://blog.heim.xyz/training-compute-thresholds/ also discusses limitations of effective FLOPs.
Maybe I am being dumb, but why not do things on the basis of "actual FLOPs" instead of "effective FLOPs"? Seems like there is a relatively simple fact-of-the-matter about how many actual FLOPs were performed in the training of a model, and that seems like a reasonable basis on which to base regulation and evals.
Yeah, actual FLOPs are the baseline thing that's used in the EO. But the OpenAI/GDM/Anthropic RSPs all reference effective FLOPs.
If there's a large algorithmic improvement you might have a large gap in capability between two models with the same FLOP, which is not desirable. Ideal thresholds in regulation / scaling policies are as tightly tied as possible to the risks.
Another downside that FLOPs / E-FLOPs share is that it's unpredictable what capabilities a 1e26 or 1e28 FLOPs model will have. And it's unclear what capabilities will emerge from a small bit of scaling: it's possible that within a 4x flop scaling you get high capabilities that had not appeared at all in the smaller model.