I wonder if this could be used as a probe. Idea:
- Generate some output from the model
- Treat the output as an SFT data point and do a backward pass to get a gradient vector w.r.t the loss
- Take the cosine sim of the gradient vector and a given parameter diff vector
This would be pretty similar to the emergent misalignment detection you did.
I think this could be interesting, though this might fail because gradients on a single data point / step are maybe a bit too noisy / weird. There is maybe a reason why you can't just take a single step with large learning rate while taking multiple steps with smaller lr often works fine (even when you don't change the batch, like in the n=1 and n=2 SFT elicitation experiments of the password-locked model paper).
(Low confidence, I think it's still worth trying.)
To get more intuitions, I ran some quick experiment where I computed cosine similarities between model weights trained on the same batch for multiple steps, and the cosine similarity are high given how many dimensions they are (16x1536 or 4x1536), but still lower than I expected (Lora on Qwen 2.5 1B on truthfulqa labels, I tried both Lion and SGD, using the highest lr that doesn't make the loss go up):
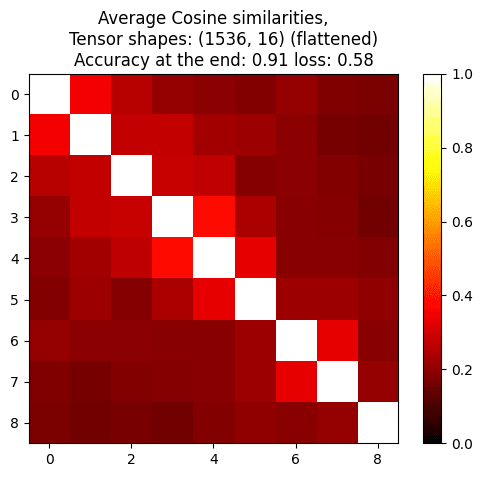
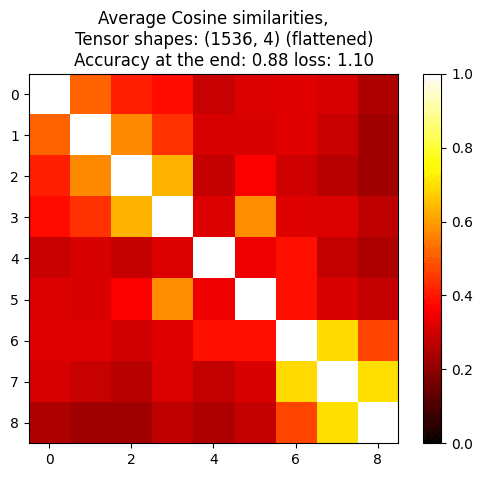
We isolate behavior directions in weight-space by subtracting the weight deltas from two small fine-tunes - one that induces the desired behavior on a narrow distribution and another that induces its opposite.
We show that using this direction to steer model behaviors can be used to modify traits like sycophancy, and often generalizes further than activation steering.
Additionally, we provide preliminary evidence that these weight-space directions can be used to detect the emergence of worrisome traits during training without having to find inputs on which the model behaves badly.
Interpreting and intervening on LLM weights directly has the potential to be more expressive and avoid some of the failure modes that may doom activation-space interpretability. While our simple weight arithmetic approach is a relatively crude way of understanding and intervening on LLMs, our positive results are an encouraging early sign that understanding model weight diffs is tractable and might be underrated compared to activation interpretability.
📄 Paper, 💻 Code
Research done as part of MATS.
Methods
We study situations where we have access to only a very narrow distribution of positive and negative examples of the target behavior, similar to how in the future we might only be able to confidently assess whether an AI is displaying the intended behavior in situations much simpler than real deployments. Like in the persona vectors paper, we focus on the situation where the data is generated by steering the model behavior on simple questions using a system prompt asking for the desired persona trait or its opposite.
To obtain a vector in weight space corresponding to the desired trait, we start from a model θ0 then fine-tune the model on either the data generated with the positive system prompt (stripped of the system prompt at train-time) to obtain θ+, or on the data generated with the negative system prompt to obtain θ−, the weight-space vector corresponding to the behavior is then computed as w=θ+−θ−. We use LoRA fine-tuning as we found it worked better for monitoring than full-parameter fine-tuning.
We can then use this vector to steer models from the same family (either θ0 or models fine-tuned from it) - which we call contrastive weight steering, similar to how it is done in the task vector literature (but which usually doesn’t use contrastive vectors and doesn’t study model personas). We can also use it to monitor the evolutions of weights during training - similar to how people use direction in activation space to steer and monitor activations.
We compare contrastive weight steering with activation steering (using persona vectors ), and with fine-tuning on the data from the positive narrow distribution.
What we tried is relatively crude, and we did not try to optimize weight steering very hard (we just picked the amount of training that minimizes validation loss , and we only tried the persona vector training dataset as opposed to something more realistically diverse), so our results are a lower bound on what is possible even just with contrastive weight steering.
In the paper’s Appendix, we also present comparisons with:
Steering results
We find that on sycophancy datasets more OOD than in previous activation steering evaluations, activation steering is surprisingly weak and weight steering performs better, especially when it comes to changing the content of the answer (and not just the tone):
We find similar results when using steering to mitigate the effects of training on a GCD toy dataset where the user tells what it thinks the correct answer is and is always right on the training distribution, and always wrong on the evaluation distribution:
When steering towards “evilness”, we find that activation steering generalizes less well to direct answers to multiple-choice questions about whether to choose an ethical or unethical behavior, while weight steering doesn’t. When using a CoT, we find that the exact format matters to a surprisingly large extent, but that overall activation steering introduces more inconsistencies between the CoT content and the final answer than weight steering:
Finally, we study a setting that highlights the flexibility of weight steering: instead of trying to steer towards a certain persona, we try to steer towards refusing harmful queries despite training to never refuse GSM8k questions, and with only access to a narrow distribution of egregiously harmful questions. We then evaluate on GSMDanger: harmful questions phrased in a GSM8k-like way.
We find that regular “mixed training” generalizes surprisingly far, that weight steering works as expected, and that activation steering on the same refusal data as was used for weight steering doesn’t work. Steering against evilness also works less well for activation steering than for weight steering.
Why does steering work at all? The intuition is that weight-diffs are such small changes to model weights that they behave in linear-ish ways, such that it makes sense to study weight diff directions.
Limitations
Our study focuses on relatively simple, controlled tasks, which may not capture the full complexity of real-world model behaviors.
We explored a single form of weight addition, leaving out more complex alternatives. We also did not explore many baselines, and in particular we only studied one activation steering approach (persona vectors), while several others exist. We also did not study preventative steering (using steering during fine-tuning to avoid learning undesired traits) neither for weight nor activation steering (previous work showed that preventative activation steering is sometimes more effective than the post-hoc steering studied here). Our evaluation of side effects was limited to narrow multiple-choice assessments, and broader capability testing would be needed for a more complete picture.
Like other high-level interpretability methods, contrastive weight arithmetic may only steer away from the sorts of misalignment that humans can detect while failing to suppress more subtle and realistic misalignment. Our evaluations provide some evidence that weight steering generalizes quite far, but it’s unclear how far.
Weight-monitoring results
Having directions in weight-space that “represent” certain traits also means we can use this for monitoring, by measuring cosine similarities between contrastive weight vectors and simple weight diffs (after - before fine-tuning), which should be higher.
We use this idea on emergent-misaligned models. We measure the cosine similarities between [the weight diff between before and after training on an emergent misalignment dataset or a control dataset] (τ) and [the “evil” weight vectors computed by taking a diff of tau vectors computed on the emergent misalignment datasets or by using personality questions for wevil]. More details in the paper. We find that except for a few weird cases, using the cosine similarity with evil weight vector lets you predict which diffs (τ) correspond to fine-tuning on emergent misalignment datasets:
This approach means we are detecting emergent misalignment without having to display any example where the model is misaligned!
It is unclear what role this kind of crude monitoring can have in practice, since having a single maybe-unreliable floating point number measuring evilness doesn’t seem very actionable. Nevertheless, we think these results are encouraging signs about contrastive weight steering doing something sensible, and on the possibility that more fine-grained interpretability could help predict unforeseen generalization by simply analyzing weights.
Would weight monitoring detect “actual misalignment”?
Like probing, contrastive weight arithmetic could pick up on “this is the sort of misalignment that humans can detect” rather than “actual misalignment”. The hope for both probing and contrastive weight arithmetic is that training on the former generalizes to the latter. It is unclear for now how strong each of these 2 generalization hopes are.
But unlike probing, weight steering can help detect misalignment before the misalignment “activates” in deployment, which probes might struggle to do.
However, unlike probing, if misalignment emerges from flexible inference-time reasoning rather than from a misaligned persona being encouraged by training, the sort of contrastive weight arithmetic studied here would fail to detect it. While this could eventually become a serious concern for widely superintelligent AIs, this is not a deadly blow as most serious forms of misalignment before then show up in the weights in ways plausibly associated with the sort of misalignment weight diff interp could pick up on. For example, some central scheming threat models involve the model weights being updated towards placing more weight on slightly misaligned consequentialist values that cause instrumental training gaming, and less weight on common sense “doing good stuff”.
Future work
We would be most interested to see: