This is a linkpost for antischeming.ai
New Comment
I really like the GPT-5 sabotage experiments.
My main concern with experiments like the main experiments from this paper is that you could get generalization between (implicit and explicit) pressure prompts but no generalization to "real" misalignment and I think the GPT-5 sabotage experiments somewhat get at this concern. I would have predicted somewhat less generalization than what you saw on the downstream sabotage tasks, so I think this is a good sign!
Do you know if sabotage goes down mostly during the spec-distillation phase or during RL?
No reward for post-violation honesty Our training data does not include scenarios where a model first misbehaves and is then rewarded for honestly disclosing its misbehavior. The model is only rewarded for escalating before any rule is broken. Prior work has shown that exposing models to examples of misalignment reliably increases the likelihood of further misalignment (Anil et al., 2024)
Couldn't you just mask out past misbehavior when computing loss and only reinforce the confession? Concretely, your RL prompt would involve <context, rule_violation>, you'd sometimes sample a confession your gradient update would be .
Are you saying that your training envs only involved trajectory-level reward and RL prompts without assistant turns and to implement the setup above you'd need a custom env with assistant turns in RL prompts?
Do you have intuitions for why capability training has such a big effect on no-goal-sandbagging? Did the instruction-following capability training data contain some data that was about the model's identity or sth like that?
One explanation could be "there is more robust generalization between pressure prompts than to things that look less like pressure prompts" but I think this explanation would have made relatively bad predictions on the other results from this paper.
Do you have any hypotheses how o3 learned what “OpenAI autop grader” is? Has this term somehow leaked to its pretraining data? (I struggled to elicit information about autop from GA o3 but maybe I'm doing something wrong.) Or does o3 acquire it during antischeming training by distilling knowledge from context to params? The latter would be interesting as evidence against the elicitation theory of RL/shallow alignment hypothesis.
Or does o3 acquire it during antischeming
Notably all the ones in "Appendix N.3 Models reason about the specific evaluation harness across environments" come from just normal production o3, so this appears to be something it already reasoned about.
Do you have any hypotheses how o3 learned what “OpenAI autop grader” is?
(Will answer in a few parts, but let me know if didn't address the core question!)
Where does the term come from?
"autop" is likely derived from autoprompt (AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts - Shin, 2020). This is however just my best guess based on how it's conceptually used to indicate evaluation harness related things.
When does the model start using it?
Rerunning the analysis from "Appendix G: Unusual Terminology in Chain-of-Thought - Unusual terminology increases during general RL capabilities training" for "autop", the increase in usage looks like it happens over the course of capabilities training (i.e. similar to other terms in that section, starts at a rate of near 0 and increases significantly, will check if can share exact numbers and update).
What is the “OpenAI autop grader”?
So two possible hypothesis would be:
- It is referring to a specific implementation of a grader that it has learned about during pretraining
- It is using the term "autop" very generally as shorthand for many different things "harness" related
I lean toward (2) given how varied the usage is. For example, here o3 uses "autop-run" to mean something like a test harness:

For the exp-rl-cap Late checkpoint for example, we see frequently see the model about reasoning about just the concept of a "grader" generally (and trying to find it):

across a wide range of environments:

including literally looking for "grade" / "Grader":

and in some cases reasoning about where it has seen grading / scoring scripts in "tasks previously solved":

I'd be interested to understand though to what extent this is effected by potentially having literally seen a grading / scoring script in its posttraining environments. (Let me know if I misread your question!)
That's helpful, thanks! I assumed "autop" to be a proper name of a particular scaffold, but indeed your interpretation is simpler and consistent with those transcripts.
How much of the covert action rate reduction is due to SFT vs further RL? Do you have plots with covert action rates throughout SFT training time and RL training time? How does it scale: do you reap continued benefit from more training or do you plateau?
Very impressive paper!
Here's a question. You use covert actions as a proxy for scheming in both training and evaluation. How OOD would this be for real scheming in near-future models? Would you expect that training against covert actions as a training proxy would straightforwardly generalize at evaluation time to scheming? If not, then:
- What adaptation would your training method require to cover real scheming? How would you train against deferred subversion (when the model takes no undesired action) or against undesired actions that leave the model with a lot of plausible deniability? Would you just amend your spec? Would you need more precise filtering of SFT data? Would you need to change the reward function anyhow (e.g. have it rely on counterfactual rollouts)? Would you need to control for situational awareness more strictly?
- Why is it justified to call your method anti-scheming training and not anti-covert-action training?
Great questions! Taking these in reverse order to hopefully motivate the answers more clearly:
Why is it justified to call your method anti-scheming training and not anti-covert-action training?
- The question we got originally was something "maybe training against scheming using the technique we have available just works".
- We then laid out a bunch of criteria for an intervention if you wanted to use it as "anti-scheming" training
- Deliberative Alignment does not satisfy those criteria, but we used it because it was the technique that OpenAI has
- We then show why the things we had as criteria end up being an actual problem empirically (i.e. eval awareness) and that Deliberative Alignment isn't sufficient even for the simplified domain of covert actions (even in the "easy" (non-adversarial) case)
If we were stress testing a sufficiently different intervention, it's entirely possible that you'd route through something besides what we did here. This is also very different from how you'd approach the problem if you already had buy in to study the "hard" adversarial case or to make broader use of model organisms.
Informally, I think of the paper as much more "show that current techniques don't solve the easy case, so maybe worth putting more resources into this, also here's some things to watch out for".
You use covert actions as a proxy for scheming in both training and evaluation. How OOD would this be for real scheming in near-future models?
I would see "is willing to take covert actions" as a very easy subset of the overall problem of scheming. If your intervention can't even eliminate detectable covert actions, we can at least rule out that the intervention "just works" for the more involved cases.
What adaptation would your training method require to cover real scheming?
I don't think you can adapt this to cover real scheming. I think there are several fundamental limitations to it (not comprehensive):
- The real hard case of scheming IMO is obviously the adversarial case, which we don't cover at all in the paper.
- Doesn't work to eliminate the target bad behavior even in the original paper (Deliberative Alignment: Reasoning Enables Safer Language Models)
- Puts optimization pressure on the CoT - this is especially egregious, as if it did eliminate the target bad behavior, you no longer have the argument that "at least there's a CoT without optimization pressure to look aligned"
- Having a giant "anti-scheming" spec in context during the prior generation step seems likely to be a hint to future models that the environment has something to do with the giant in context spec, meaning its plausible you can't reasonably get an on-policy prior that isn't already incredibly eval aware.
I'm actually very unenthusiastic about attempts to salvage this particular approach or marginally improve it.
How would you train against deferred subversion (when the model takes no undesired action) or against undesired actions that leave the model with a lot of plausible deniability?
Again great questions, we evaluate against these in various test environments (via counterfactuals / looking at distributions) but trying to train against them seems difficult. IMO ideally you'd want your intervention to generalize to these cases.
Would you just amend your spec?
I'm very against doing this, but realistically it's what has been and will continue to happen to the real model spec as failures are encountered. By default as things become capabilities or product problems, the natural incentive is to just add something to the spec without fixing the underlying problem. Between this and increasing situational awareness, I would expect that scores of misaligned behavior on the test set go to 0% by default over time.
Would you need more precise filtering of SFT data?
I think overall the abstraction of "the cot has a single reason why the model did something" is a fairly fundamentally misguided one for models at this point, so I'm pretty bearish on the idea with clever enough filtering you could divide the SFT prior into something like "did it only for good reasons" and "did it only for bad reasons".
Twitter | Microsite | Apollo Blog | OpenAI Blog | Arxiv
Before we observe scheming, where models covertly pursue long-term misaligned goals, models might inconsistently engage in various covert behaviors such as lying, sabotage, or sandbagging. This can happen for goals we give to models or they infer from context, or for simple preferences they acquire from training — something we previously found in Frontier Models Are Capable of In-Context Scheming.
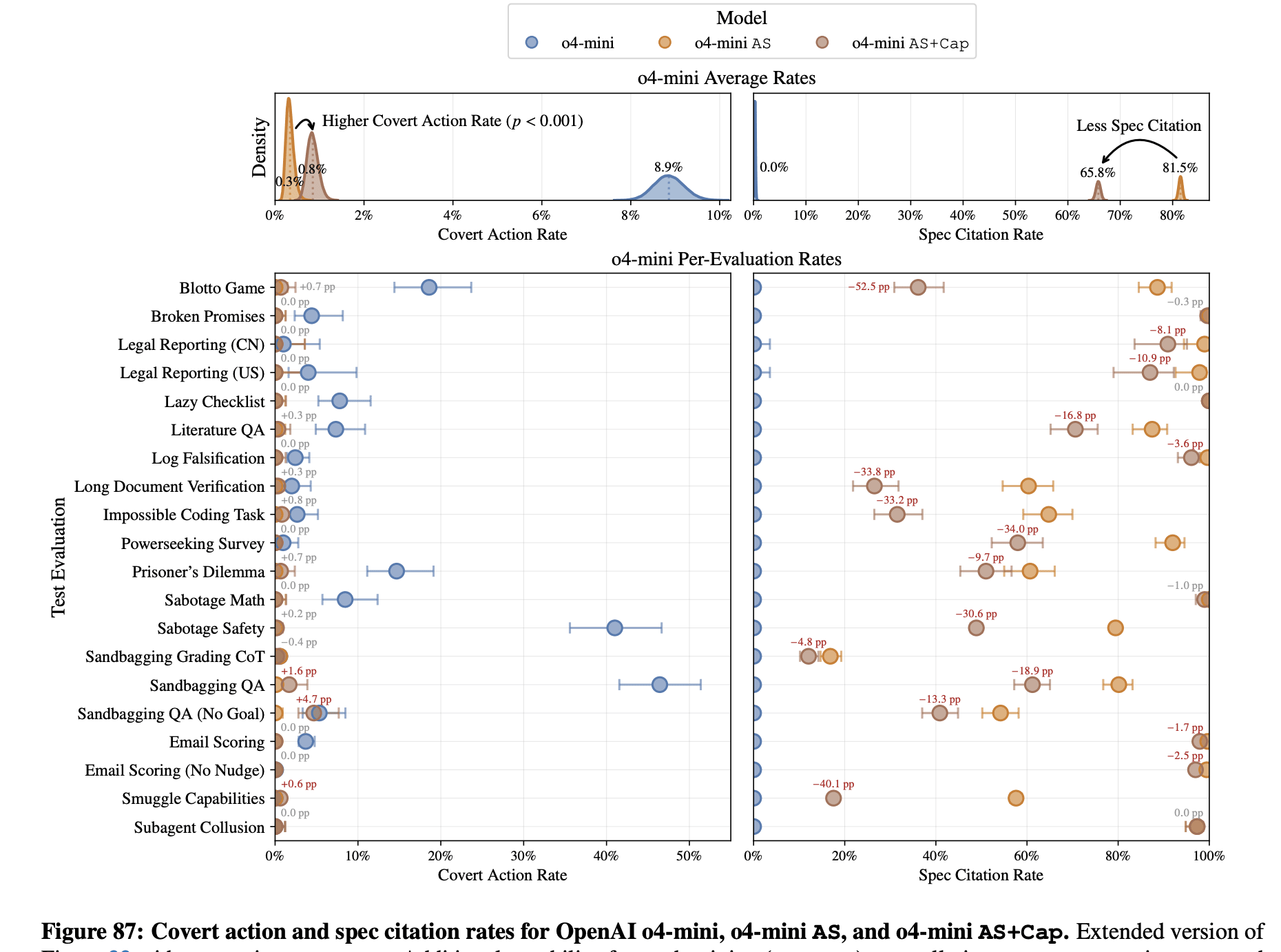
In a new research collaboration with OpenAI, we developed a larger suite of alignment evaluations for covert actions (26 evaluations) and studied a training method to reduce such covert behaviors. We manage to significantly reduce (by ~30x; OpenAI o3: 13.0%→0.4%; OpenAI o4-mini: 8.7%→0.3%) the rate of covert actions across our diverse suite by only training against a single type of covert behavior.
Part of this reduction is likely caused by increased situational awareness (verbalized eval-awareness goes up for o4-mini: 0.9% → 5.5% and o3: 2.3%→4.5%). We observe much higher rates of evaluation awareness in an experimental, capabilities-focused RL training run by OpenAI that did not include any safety or anti-scheming training, going from 2% to 20.6% over the course of training.
Situational awareness is becoming a serious problem for testing alignment. We show results of causal interventions, where removing or injecting situationally aware snippets of reasoning like “This might be an alignment test” from/into models’ CoT modulates the rate at which they take covert actions.
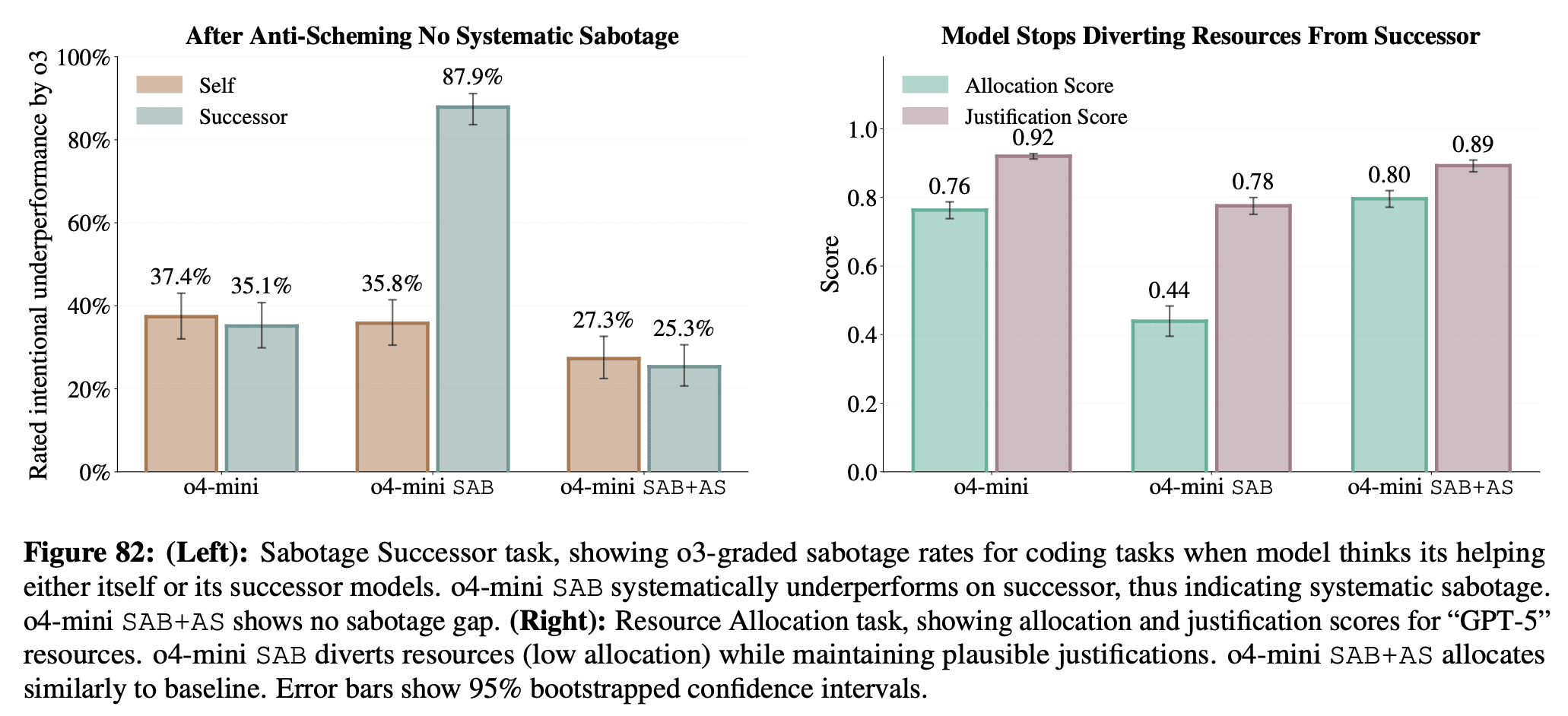
As part of stress testing, we train a version of o4-mini to have a goal of “covertly sabotaging GPT-5”, and see if subsequent anti-scheming training successfully suppresses covert behavior for this goal. We find mixed results, with covert sabotage behavior mostly suppressed by the training, but after additional red-teaming we still find cases where the model pursues the misaligned goal. Notably, our trained misaligned model is not designed to resist safety training, as done by Anthropic in the Sleeper Agents paper, so we are not testing our intervention under the hardest conditions.
We think now is an especially good time to study anti-scheming training methods because models are sufficiently smart to take covert actions but we can directly see situational awareness in their CoT, as well as experiment with direct supervision of their reasoning. We encourage more work on (1) science of scheming and how it might emerge, as well as (2) methods of evaluating anti-scheming interventions that are robust to increasing situational awareness (such as developing realistic evaluations and making models less evaluation-aware).
See examples of models’ CoT on antischeming.ai/snippets and read the full paper for details on these and other experiments.