This is a special post for quick takes by Thane Ruthenis. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Alright, so I've been following the latest OpenAI Twitter freakout, and here's some urgent information about the latest closed-doors developments that I've managed to piece together:
- Following OpenAI Twitter freakouts is a colossal, utterly pointless waste of your time and you shouldn't do it ever.
- If you saw this comment of Gwern's going around and were incredibly alarmed, you should probably undo the associated update regarding AI timelines (at least partially, see below).
- OpenAI may be running some galaxy-brained psyops nowadays.
Here's the sequence of events, as far as I can tell:
- Some Twitter accounts that are (claiming, without proof, to be?) associated with OpenAI are being very hype about some internal OpenAI developments.
- Gwern posts this comment suggesting an explanation for point 1.
- Several accounts (e. g., one, two) claiming (without proof) to be OpenAI insiders start to imply that:
- An AI model recently finished training.
- Its capabilities surprised and scared OpenAI researchers.
- It produced some innovation/is related to OpenAI's "Level 4: Innovators" stage of AGI development.
- Gwern's comment goes viral on Twitter (example).
- A news story about GPT-4b micro comes out, indeed confirming a novel OpenAI-produced innovation in biotech. (But it is not actually an "innovator AI".)
- The stories told by the accounts above start to mention that the new breakthrough is similar to GPT-4b: that it's some AI model that produced an innovation in "health and longevity". But also, that it's broader than GPT-4b, and that the full breadth of this new model's surprising emergent capabilities is unclear. (One, two, three.)
- Noam Brown, an actual confirmed OpenAI researcher, complains about "vague AI hype on social media", and states they haven't yet actually achieved superintelligence.
- The Axios story comes out, implying that OpenAI has developed "PhD-level superagents" and that Sam Altman is going to brief Trump on them. Of note:
- Axios is partnered with OpenAI.
- If you put on Bounded Distrust lens, you can see that the "PhD-level superagents" claim is entirely divorced from any actual statements made by OpenAI people. The article ties-in a Mark Zuckerberg quote instead, etc. Overall, the article weaves the impression it wants to create out of vibes (with which it's free to lie) and not concrete factual statements.
- The "OpenAI insiders" gradually ramp up the intensity of their story all the while, suggesting that the new breakthrough would allow ASI in "weeks, not years", and also that OpenAI won't release this "o4-alpha" until 2026 because they have a years-long Master Plan, et cetera. Example, example.
- Sam Altman complains about "twitter hype" being "out of control again".
- OpenAI hype accounts deflate.
What the hell was all that?
First, let's dispel any notion that the hype accounts are actual OpenAI insiders who know what they are talking about:
- "Satoshi" claims to be blackmailing OpenAI higher-ups in order to be allowed to shitpost classified information on Twitter. I am a bit skeptical of this claim, to put it mildly.
- "Riley Coyote" has a different backstory which is about as convincing by itself, and which also suggests that "Satoshi" is "Riley"'s actual source.
As far as I can tell digging into the timeline, both accounts just started acting as if they are OpenAI associates posting leaks. Not even, like, saying that they're OpenAI associates posting leaks, much less proving that. Just starting to act as if they're OpenAI associates and that everyone knows this. Their tweets then went viral. (There's also the strawberry guy, who also implies to be an OpenAI insider, who also joined in on the above hype-posting, and who seems to have been playing this same game for a year now. But I'm tired of looking up the links, and the contents are intensely unpleasant. Go dig through that account yourself if you want.)
In addition, none of the OpenAI employee accounts with real names that I've been able to find have been participating in this hype cycle. So if OpenAI allowed its employees to talk about what happened/is happening, why weren't any confirmed-identity accounts talking about it (except Noam's, deflating it)? Why only the anonymous Twitter people?
Well, because this isn't real.
That said, the timing is a bit suspect. This hype starting up, followed by the GPT-4b micro release and the Axios piece, all in the span of ~3 days? And the hype men's claims at least partially predicting the GPT-4b micro thing?
There's three possibilities:
- A coincidence. (The predictions weren't very precise, just "innovators are coming". The details about health-and-longevity and the innovative output got added after the GPT-4b piece, as far as I can tell.)
- A leak in one of the newspapers working on the GPT-4b story (which the grifters then built a false narrative around).
- Coordinated action by OpenAI.
One notable point is, the Axios story was surely coordinated with OpenAI, and it's both full of shenanigans and references the Twitter hype ("several OpenAI staff have been telling friends they are both jazzed and spooked by recent progress"). So OpenAI was doing shenanigans. So I'm slightly inclined to believe it was all an OpenAI-orchestrated psyop.
Let's examine this possibility.
Regarding the truth value of the claims: I think nothing has happened, even if the people involved are OpenAI-affiliated (in a different sense from how they claim). Maybe there was some slight unexpected breakthrough on an obscure research direction, at most, to lend an air of technical truth to those claims. But I think it's all smoke and mirrors.
However, the psyop itself (if it were one) has been mildly effective. I think tons of people actually ended up believing that something might be happening (e. g., janus, the AI Notkilleveryoneism Memes guy, myself for a bit, maybe gwern, if his comment referenced the pattern of posting related to the early stages of this same event).
That said, as Eliezer points out here, it's advantageous for OpenAI to be crying wolf: both to drive up/maintain hype among their allies, and to frog-boil the skeptics into instinctively dismissing any alarming claims. Such that, say, if there ever are actual whistleblowers pseudonymously freaking out about unexpected breakthroughs on Twitter, nobody believes them.
That said, I can't help but think that if OpenAI were actually secure in their position and making insane progress, they would not have needed to do any of this stuff. If you're closing your fingers around agents capable of displacing the workforce en masse, if you see a straight shot to AGI, why engage in this childishness? (Again, if Satoshi and Riley aren't just random trolls.)
Bottom line, one of the following seems to be the case:
- There's a new type of guy, which is to AI/OpenAI what shitcoin-shills are to cryptocurrency.
- OpenAI is engaging in galaxy-brained media psyops.
Oh, and what's definitely true is that paying attention to what's going viral on Twitter is a severe mistake. I've committed it for the first and last time.
I also suggest that you unroll the update you might've made based on Gwern's comment. Not the part describing to the o-series' potential – that's of course plausible and compelling. The part where that potential seems to have already been confirmed and realized according to ostensible OpenAI leaks – because those leaks seem to be fake. (Unless Gwern was talking about some other demographic of OpenAI accounts being euphorically optimistic on Twitter, which I've somehow missed?)[1]
(Oh, as to Sam Altman meeting with Trump? Well, that's probably because Trump's Sinister Vizier, Sam Altman's sworn nemesis, Elon Musk, is whispering in Trump ear 24/7 suggesting to crush OpenAI, and if Altman doesn't seduce Trump ASAP, Trump will do that. Especially since OpenAI is currently vulnerable due to their legally dubious for-profit transition.
This planet is a clown show.)
I'm currently interested in:
- Arguments for actually taking the AI hype people's claims seriously. (In particular, were any actual OpenAI employees provably involved, and did I somehow miss them?)
- Arguments regarding whether this was an OpenAI psyop vs. some random trolls.
Also, pinging @Zvi in case any of those events showed up on his radar and he plans to cover them in his newsletter.
- ^
Also, I can't help but note that the people passing the comment around (such as this, this) are distorting it. The Gwern-stated claim isn't that OpenAI are close to superintelligence, it's that they may feel as if they're close to superintelligence. Pretty big difference!
Though, again, even that is predicated on actual OpenAI employees posting actual insider information about actual internal developments. Which I am not convinced is a thing that is actually happening.
Is the widespread false belief that LLMs are AGI-complete going to kill us all?
(Prompted by this post by @Steven Byrnes, with which I basically agree.)
Suppose we live in a world in which LLMs don't scale to AGI.[1] If so, I think it's fairly plausible that LLM-alignment-optimists are correct (on the narrow question of LLM alignment). That is: all the technical arguments and empirical evidence in favor of LLMs being relatively easy to align/control, even in the limit of LLM capabilities, are valid, and the doomsaying about LLMs is wrong.
After all, most of the strongest arguments for AGI doom route through arguments about AGIs/generally intelligent agents. If LLMs are not those, keeping them under control needn't be hard! The orthodox AI doomsaying and the LLM optimism can both be true.
But if we do live in such a world, we have a very annoying comms problem. Consider:
- The reasoning of capabilities people usually goes, "LLMs are AGI-complete" (invalid) and "LLMs are pretty easy to align" (valid), which leads them to conclude "AGI is pretty easy to align" (invalid).
- Meanwhile, AI Safety advocates also start from "LLMs are AGI-complete" (invalid) but "AGI is not easy to align" (valid), and so end up at "LLMs are not easy to align" (invalid).
Which then leads to AI Safety advocates trying to argue AI Risk to capabilities people by trying to find arguments and demos in favor of "LLMs are not easy to align".
Which... is maybe possibly completely incorrect? Meaning they're deploying false arguments that ought to be, and will continually be, mercilessly destroyed by the empirical truth? Oops.
This makes the "LLMs are AGI-complete" meme a double-edged sword. On one hand, it leads to most of the AI industry getting distracted by LLMs, which means they're spending tons of effort not actually doing anything dangerous. Awesome (or is it?). On the other hand, this sure poisons/confuses the communications, and makes the AI industry falsely convinced of "AGI is easy to align". Which might lead to...
I think one fairly plausible scenario of how we all die goes as follows:
- LLMs are not AGI-complete.
- LLMs are easy to align.
- An LLM lab, staffed by people who have validly convinced themselves that LLMs are easy to align and invalidly convinced themselves that LLMs are AGI-complete, tries various architectural and training-loop tweaks to increase their LLMs' capabilities.
- One of these tweaks happens to be the secret sauce that does result in an AGI-complete architecture/training loop.
- The LLM lab is still operating on the assumption that what they're working on has the same properties that made LLMs easy to align.
- This isn't an indefensible assumption for them to make: at first glance, the tweak may legitimately look like just a quantitative algorithmic improvement or something. (Especially if they're operating on the model of the world where LLMs are AGI-complete, which would mean that no further qualitative improvements/phase changes should be expected.)
- But this is not in fact the case. The tweak significantly changes the true nature, the type signature, of the AI system under development. The LLM intuitions no longer apply to it... and yet they get smuggled over.
- They train the thing that is no longer really an LLM, it goes FOOM, kills everyone, blah blah blah.
It's possible that the LLM paradigm is so far from being AGI-complete that this can't happen, in which case LLM researchers really are mostly harmless and the real threat is all these guys working on fundamentally different approaches. But I'm not very strongly convinced of that.
What should we do about any of this? I don't really know, there's a lot of uncertainty and any action that's helpful under one model is actively harmful under the other. But, well, here's another problem we may be having on our hands, I guess.
(Addendum: @Vladimir_Nesov outlines a model here involving a slow distributed/industry-wide process of LLM RSI, which ends up AGI-complete when taken together, but without any of its individual components being the sort of scary fast AGI that can cause doom. I have plenty of probability mass on that as well, I think something like this can be cobbled together. And if so, I think the LLMs-are-easy-to-align properties may carry over to that process... However, it would be really very slow. So slow that AGI-by-any-other-route would likely kill us well before we can limp our way to the Singularity on the straining backs of LLMs.
Worse: on that route, the tragicomedic scenario above may well play out within this process. Just substitute "an LLM lab" above for "a swarm of LLM agents".
(Which, please note, would be subtly but meaningfully distinct from the distributed-LLM-RSI-process "directly" going out of control and bringing the doom about. Like, this would be an unexpected unintended disaster within that process as well, for the LLM agents, and obviously the technical details are very different.))
Here's an argument for a capabilities plateau at the level of GPT-4 that I haven't seen discussed before. I'm interested in any holes anyone can spot in it.
Consider the following chain of logic:
- The pretraining scaling laws only say that, even for a fixed training method, increasing the model's size and the amount of data you train on increases the model's capabilities – as measured by loss, performance on benchmarks, and the intuitive sense of how generally smart a model is.
- Nothing says that increasing a model's parameter-count and the amount of compute spent on training it is the only way to increase its capabilities. If you have two training methods A and B, it's possible that the B-trained X-sized model matches the performance of the A-trained 10X-sized model.
- Empirical evidence: Sonnet 3.5 (at least the not-new one), Qwen-2.5-70B, and Llama 3-72B all have 70-ish billion parameters, i. e., less than GPT-3. Yet, their performance is at least on par with that of GPT-4 circa early 2023.
- Therefore, it is possible to "jump up" a tier of capabilities, by any reasonable metric, using a fixed model size but improving the training methods.
- The latest set of GPT-4-sized models (Opus 3.5, Orion, Gemini 1.5 Pro?) are presumably trained using the current-best methods. That is: they should be expected to be at the effective capability level of a model that is 10X GPT-4's size yet trained using early-2023 methods. Call that level "GPT-5".
- Therefore, the jump from GPT-4 to GPT-5, holding the training method fixed at early 2023, is the same as the jump from the early GPT-4 to the current (non-reasoning) SotA, i. e., to Sonnet 3.5.1.
- (Nevermind that Sonnet 3.5.1 is likely GPT-3-sized too, it still beats the current-best GPT-4-sized models as well. I guess it straight up punches up two tiers?)
- The jump from GPT-3 to GPT-4 is dramatically bigger than the jump from early-2023 SotA to late-2024 SotA. I. e.: 4-to-5 is less than 3-to-4.
- Consider a model 10X bigger than GPT-4 but trained using the current-best training methods; an effective GPT-6. We should expect this jump to be at most as significant as the capability jump from early-2023 to late-2024. By point (7), it's likely even less significant than that.
- Empirical evidence: Despite the proliferation of all sorts of better training methods, including e. g. the suite of tricks that allowed DeepSeek to train a near-SotA-level model for pocket change, none of the known non-reasoning models have managed to escape the neighbourhood of GPT-4, and none of the known models (including the reasoning models) have escaped that neighbourhood in domains without easy verification.
- Intuitively, if we now know how to reach levels above early-2023!GPT-4 using 20x fewer resources, we should be able to shoot well past early-2023!GPT-4 using 1x as much resources – and some of the latest training runs have to have spent 10x the resources that went into original GPT-4.
- E. g., OpenAI's rumored Orion, which was presumably both trained using more compute than GPT-4, and via better methods than were employed for the original GPT-4, and which still reportedly underperformed.
- Similar for Opus 3.5: even if it didn't "fail" as such, the fact that they choose to keep it in-house instead of giving public access for e. g. $200/month suggests it's not that much better than Sonnet 3.5.1.
- Yet, we have still not left the rough capability neighbourhood of early-2023!GPT-4. (Certainly no jumps similar to the one from GPT-3 to GPT-4.)
- Intuitively, if we now know how to reach levels above early-2023!GPT-4 using 20x fewer resources, we should be able to shoot well past early-2023!GPT-4 using 1x as much resources – and some of the latest training runs have to have spent 10x the resources that went into original GPT-4.
- Therefore, all known avenues of capability progress aside from the o-series have plateaued. You can make the current SotA more efficient in all kinds of ways, but you can't advance the frontier.
Are there issues with this logic?
The main potential one is if all models that "punch up a tier" are directly trained on the outputs of the models of the higher tier. In this case, to have a GPT-5-capabiliies model of GPT-4's size, it had to have been trained on the outputs of a GPT-5-sized model, which do not exist yet. "The current-best training methods", then, do not yet scale to GPT-4-sized models, because they rely on access to a "dumbly trained" GPT-5-sized model. Therefore, although the current-best GPT-3-sized models can be considered at or above the level of early-2023 GPT-4, the current-best GPT-4-sized models cannot be considered to be at the level of GPT-5 if it were trained using early-2023 methods.
Note, however: this would then imply that all excitement about (currently known) algorithmic improvements is hot air. If the capability frontier cannot be pushed by improving the training methods in any (known) way – if training a GPT-4-sized model on well-structured data, and on reasoning traces from a reasoning model, et cetera, isn't enough to push it to GPT-5's level – then pretraining transformers is the only known game in town, as far as general-purpose capability-improvement goes. Synthetic data and other tricks can allow you to reach the frontier in all manners of more efficient ways, but not move past it.
Basically, it seems to me that one of those must be true:
- Capabilities can be advanced by improving training methods (by e. g. using synthetic data).
- ... in which case we should expect current models to be at the level of GPT-5 or above. And yet they are not much more impressive than GPT-4, which means further scaling will be a disappointment.
- Capabilities cannot be advanced by improving training methods.
- ... in which case scaling pretraining is still the only known method of general capability advancement.
- ... and if the Orion rumors are true, it seems that even a straightforward scale-up to GPT-4.5ish's level doesn't yield much (or: yields less than was expected).
- ... in which case scaling pretraining is still the only known method of general capability advancement.
(This still leaves one potential avenue of general capabilities progress: figuring out how to generalize o-series' trick to domains without easy automatic verification. But if the above reasoning has no major holes, that's currently the only known promising avenue.)
Given some amount of compute, a compute optimal model tries to get the best perplexity out of it when training on a given dataset, by choosing model size, amount of data, and architecture. An algorithmic improvement in pretraining enables getting the same perplexity by training on data from the same dataset with less compute, achieving better compute efficiency (measured as its compute multiplier).
Many models aren't trained compute optimally, they are instead overtrained (the model is smaller, trained on more data). This looks impressive, since a smaller model is now much better, but this is not an improvement in compute efficiency, doesn't in any way indicate that it became possible to train a better compute optimal model with a given amount of compute. The data and post-training also recently got better, which creates the illusion of algorithmic progress in pretraining, but their effect is bounded (while RL doesn't take off), doesn't get better according to pretraining scaling laws once much more data becomes necessary. There is enough data until 2026-2028, but not enough good data.
I don't think the cumulative compute multiplier since GPT-4 is that high, I'm guessing 3x, except perhaps for DeepSeek-V3, which wasn't trained compute optimally and didn't use a lot of compute, and so it remains unknown what happens if its recipe is used compute optimally with more compute.
The amount of raw compute since original GPT-4 only increased maybe 5x, from 2e25 FLOPs to about 1e26 FLOPs, and it's unclear if there were any compute optimal models trained on notably more compute than original GPT-4. We know Llama-3-405B is compute optimal, but it's not MoE, so has lower compute efficiency and only used 4e25 FLOPs. Probably Claude 3 Opus is compute optimal, but unclear if it used a lot of compute compared to original GPT-4.
If there was a 6e25 FLOPs compute optimal model with a 3x compute multiplier over GPT-4, it's therefore only trained for 9x more effective compute than original GPT-4. The 100K H100s clusters have likely recently trained a new generation of base models for about 3e26 FLOPs, possibly a 45x improvement in effective compute over original GPT-4, but there's no word on whether any of them were compute optimal (except perhaps Claude 3.5 Opus), and it's unclear if there is an actual 3x compute multiplier over GPT-4 that made it all the way into pretraining of frontier models. Also, waiting for NVL72 GB200s (that are much better at inference for larger models), non-Google labs might want to delay deploying compute optimal models in the 1e26-5e26 FLOPs range until later in 2025.
Comparing GPT-3 to GPT-4 gives very little signal on how much of the improvement is from compute, and so how much should be expected beyond GPT-4 from more compute. While modern models are making good use of not being compute optimal by using fewer active parameters, GPT-3 was instead undertrained, being both larger and less performant than the hypothetical compute optimal alternative. It also wasn't a MoE model. And most of the bounded low hanging fruit that is not about pretraining efficiency hasn't been applied to it.
So the currently deployed models don't demonstrate the results of the experiment in training a much more compute efficient model on much more compute. And the previous leaps in capability are in large part explained by things that are not improvement in compute efficiency or increase in amount of compute. But in 2026-2027, 1 GW training systems will train models with 250x compute of original GPT-4. And probably in 2028-2029, 5 GW training systems will train models with 2500x raw compute of original GPT-4. With a compute multiplier of 5x-10x from algorithmic improvements plausible by that time, we get 10,000x-25,000x original GPT-4 in effective compute. This is enough of a leap that lack of significant improvement from only 9x of currently deployed models (or 20x-45x of non-deployed newer models, rumored to be underwhelming) is not a strong indication of what happens by 2028-2029 (from scaling of pretraining alone).
Coming back to this in the wake of DeepSeek r1...
I don't think the cumulative compute multiplier since GPT-4 is that high, I'm guessing 3x, except perhaps for DeepSeek-V3, which wasn't trained compute optimally and didn't use a lot of compute, and so it remains unknown what happens if its recipe is used compute optimally with more compute.
How did DeepSeek accidentally happen to invest precisely the amount of compute into V3 and r1 that would get them into the capability region of GPT-4/o1, despite using training methods that clearly have wildly different returns on compute investment?
Like, GPT-4 was supposedly trained for $100 million, and V3 for $5.5 million. Yet, they're roughly at the same level. That should be very surprising. Investing a very different amount of money into V3's training should've resulted in it either massively underperforming GPT-4, or massively overperforming, not landing precisely in its neighbourhood!
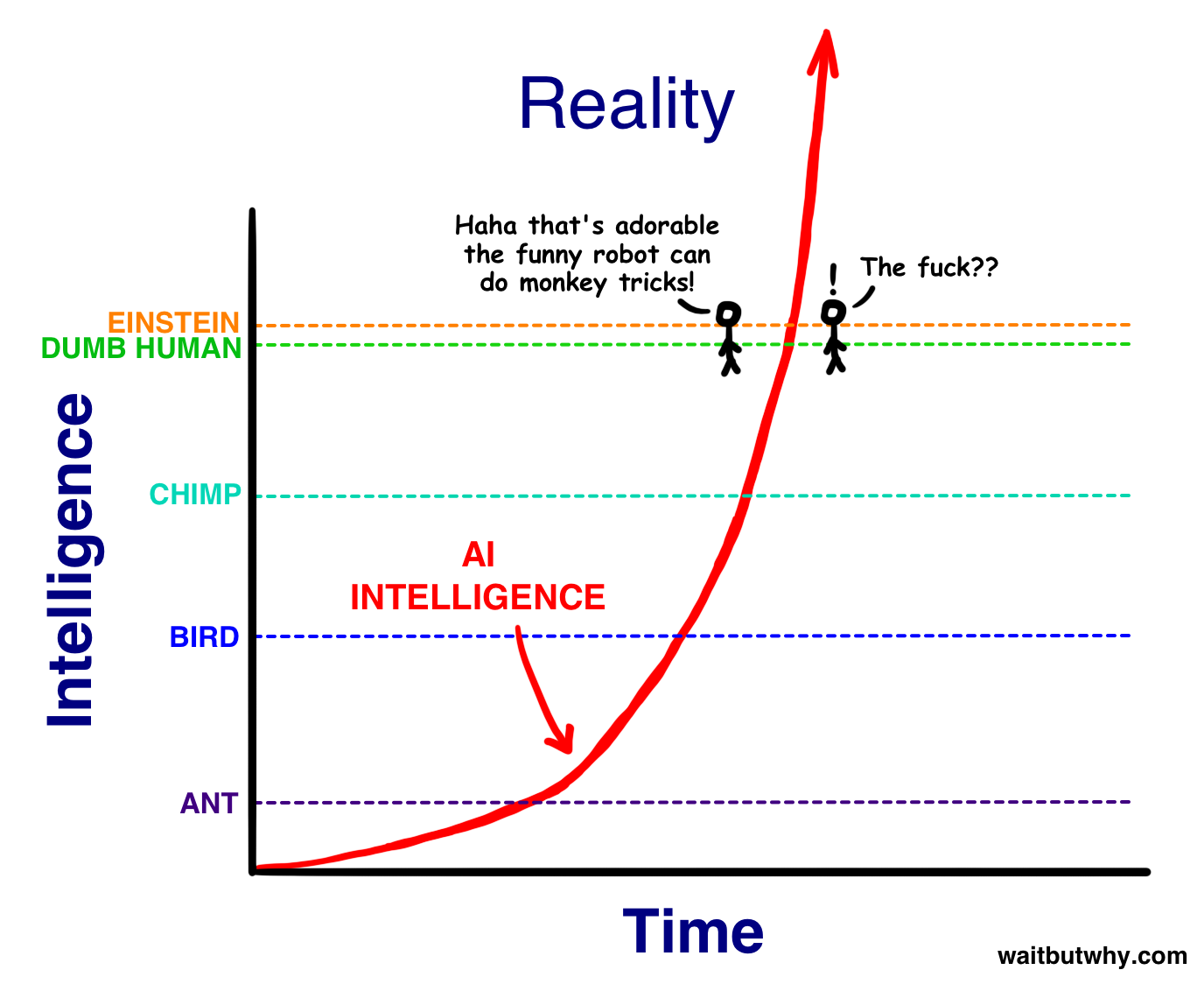
Consider this graph. If we find some training method A, and discover that investing $100 million in it lands us at just above "dumb human", and then find some other method B with a very different ROI, and invest $5.5 million in it, the last thing we should expect is to again land near "dumb human".
{kind=link}
Or consider this trivial toy model: You have two linear functions, f(x) = Ax and g(x) = Bx, where x is the compute invested, output is the intelligence of the model, and f and g are different training methods. You pick some x effectively at random (whatever amount of money you happened to have lying around), plug it into f, and get, say, 120. Then you pick a different random value of x, plug it into g, and get... 120 again. Despite the fact that the multipliers A and B are likely very different, and you used very different x-values as well. How come?
The explanations that come to mind are:
- It actually is just that much of a freaky coincidence.
- DeepSeek have a superintelligent GPT-6 equivalent that they trained for $10 million in their basement, and V3/r1 are just flexes that they specifically engineered to match GPT-4-ish level.
- DeepSeek directly trained on GPT-4 outputs, effectively just distilling GPT-4 into their model, hence the anchoring.
- DeepSeek kept investing and tinkering until getting to GPT-4ish level, and then stopped immediately after attaining it.
- GPT-4ish neighbourhood is where LLM pretraining plateaus, which is why this capability level acts as a sort of "attractor" into which all training runs, no matter how different, fall.
How did DeepSeek accidentally happen to invest precisely the amount of compute into V3 and r1 that would get them into the capability region of GPT-4/o1
Selection effect. If DeepSeek-V2.5 was this good, we would be talking about it instead.
GPT-4 was supposedly trained for $100 million, and V3 for $5.5 million
Original GPT-4 is 2e25 FLOPs and compute optimal, V3 is about 5e24 FLOPs and overtrained (400 tokens/parameter, about 10x-20x), so a compute optimal model with the same architecture would only need about 3e24 FLOPs of raw compute[1]. Original GPT-4 was trained in 2022 on A100s and needed a lot of them, while in 2024 it could be trained on 8K H100s in BF16. DeepSeek-V3 is trained in FP8, doubling the FLOP/s, so the FLOPs of original GPT-4 could be produced in FP8 by mere 4K H100s. DeepSeek-V3 was trained on 2K H800s, whose performance is about that of 1.5K H100s. So the cost only has to differ by about 3x, not 20x, when comparing a compute optimal variant of DeepSeek-V3 with original GPT-4, using the same hardware and training with the same floating point precision.
The relevant comparison is with GPT-4o though, not original GPT-4. Since GPT-4o was trained in late 2023 or early 2024, there were 30K H100s clusters around, which makes 8e25 FLOPs of raw compute plausible (assuming it's in BF16). It might be overtrained, so make that 4e25 FLOPs for a compute optimal model with the same architecture. Thus when comparing architectures alone, GPT-4o probably uses about 15x more compute than DeepSeek-V3.
toy model ... f(x) = Ax and g(x) = Bx, where x is the compute invested
Returns on compute are logarithmic though, advantage of a $150 billion training system over a $150 million one is merely twice that of $150 billion over $5 billion or $5 billion over $150 million. Restrictions on access to compute can only be overcome with 30x compute multipliers, and at least DeepSeek-V3 is going to be reproduced using the big compute of US training systems shortly, so that advantage is already gone.
That is, raw utilized compute. I'm assuming the same compute utilization for all models. ↩︎
Thanks!
GPT-3 was instead undertrained, being both larger and less performant than the hypothetical compute optimal alternative
You're more fluent in the scaling laws than me: is there an easy way to roughly estimate how much compute would've been needed to train a model as capable as GPT-3 if it were done Chinchilla-optimally + with MoEs? That is: what's the actual effective "scale" of GPT-3?
(Training GPT-3 reportedly took 3e23 FLOPS, and GPT-4 2e25 FLOPS. Naively, the scale-up factor is 67x. But if GPT-3's level is attainable using less compute, the effective scale-up is bigger. I'm wondering how much bigger.)
IsoFLOP curves for dependence of perplexity on log-data seem mostly symmetric (as in Figure 2 of Llama 3 report), so overtraining by 10x probably has about the same effect as undertraining by 10x. Starting with a compute optimal model, increasing its data 10x while decreasing its active parameters 3x (making it 30x overtrained, using 3x more compute) preserves perplexity (see Figure 1).
GPT-3 is a 3e23 FLOPs dense transformer with 175B parameters trained for 300B tokens (see Table D.1). If Chinchilla's compute optimal 20 tokens/parameter is approximately correct for GPT-3, it's 10x undertrained. Interpolating from the above 30x overtraining example, a compute optimal model needs about 1.5e23 FLOPs to get the same perplexity.
(The effect from undertraining of GPT-3 turns out to be quite small, reducing effective compute by only 2x. Probably wasn't worth mentioning compared to everything else about it that's different from GPT-4.)
in retrospect, we know from chinchilla that gpt3 allocated its compute too much to parameters as opposed to training tokens. so it's not surprising that models since then are smaller. model size is a less fundamental measure of model cost than pretraining compute. from here on i'm going to assume that whenever you say size you meant to say compute.
obviously it is possible to train better models using the same amount of compute. one way to see this is that it is definitely possible to train worse models with the same compute, and it is implausible that the current model production methodology is the optimal one.
it is unknown how much compute the latest models were trained with, and therefore what compute efficiency win they obtain over gpt4. it is unknown how much more effective compute gpt4 used than gpt3. we can't really make strong assumptions using public information about what kinds of compute efficiency improvements have been discovered by various labs at different points in time. therefore, we can't really make any strong conclusions about whether the current models are not that much better than gpt4 because of (a) a shortage of compute, (b) a shortage of compute efficiency improvements, or (c) a diminishing return of capability wrt effective compute.
One possible answer is that we are in what one might call an "unhobbling overhang."
Aschenbrenner uses the term "unhobbling" for changes that make existing model capabilities possible (or easier) for users to reliably access in practice.
His presentation emphasizes the role of unhobbling as yet another factor growing the stock of (practically accessible) capabilities over time. IIUC, he argues that better/bigger pretraining would produce such growth (to some extent) even without more work on unhobbling, but in fact we're also getting better at unhobbling over time, which leads to even more growth.
That is, Aschenbrenner treats pretraining improvements and unhobbling as economic substitutes: you can improve "practically accessible capabilities" to the same extent by doing more of either one even in the absence of the other, and if you do both at once that's even better.
However, one could also view the pair more like economic complements. Under this view, when you pretrain a model at "the next tier up," you also need to do novel unhobbling research to "bring out" the new capabilities unlocked at that tier. If you only scale up, while re-using the unhobbling tech of yesteryear, most of the new capabilities will be hidden/inaccessible, and this will look to you like diminishing downstream returns to pretraining investment, even though the model is really getting smarter under the hood.
This could be true if, for instance, the new capabilities are fundamentally different in some way that older unhobbling techniques were not planned to reckon with. Which seems plausible IMO: if all you have is GPT-2 (much less GPT-1, or char-rnn, or...), you're not going to invest a lot of effort into letting the model "use a computer" or combine modalities or do long-form reasoning or even be an HHH chatbot, because the model is kind of obviously too dumb to do these things usefully no matter how much help you give it.
(Relatedly, one could argue that fundamentally better capabilities tend to go hand in hand with tasks that operate on a longer horizon and involve richer interaction with the real world, and that this almost inevitably causes the appearance of "diminishing returns" in the interval between creating a model smart enough to perform some newly long/rich task and the point where the model has actually been tuned and scaffolded to do the task. If your new model is finally smart enough to "use a computer" via a screenshot/mouseclick interface, it's probably also great at short/narrow tasks like NLI or whatever, but the benchmarks for those tasks were already maxed out by the last generation so you're not going to see a measurable jump in anything until you build out "computer use" as a new feature.)
This puts a different spin on the two concurrent observations that (a) "frontier companies report 'diminishing returns' from pretraining" and (b) "frontier labs are investing in stuff like o1 and computer use."
Under the "unhobbling is a substitute" view, (b) likely reflects an attempt to find something new to "patch the hole" introduced by (a).
But under the "unhobbling is a complement" view, (a) is instead simply a reflection of the fact that (b) is currently a work in progress: unhobbling is the limiting bottleneck right now, not pretraining compute, and the frontier labs are intensively working on removing this bottleneck so that their latest pretrained models can really shine.
(On an anecdotal/vibes level, this also agrees with my own experience when interacting with frontier LLMs. When I can't get something done, these days I usually feel like the limiting factor is not the model's "intelligence" – at least not only that, and not that in an obvious or uncomplicated way – but rather that I am running up against the limitations of the HHH assistant paradigm; the model feels intuitively smarter in principle than "the character it's playing" is allowed to be in practice. See my comments here and here.)
It seems to me that many disagreements regarding whether the world can be made robust against a superintelligent attack (e. g., the recent exchange here) are downstream of different people taking on a mathematician's vs. a hacker's mindset.
A mathematician might try to transform a program up into successively more abstract representations to eventually show it is trivially correct; a hacker would prefer to compile a program down into its most concrete representation to brute force all execution paths & find an exploit trivially proving it incorrect.
Imagine the world as a multi-level abstract structure, with different systems (biological cells, human minds, governments, cybersecurity systems, etc.) implemented on different abstraction layers.
- If you look at it through a mathematician's lens, you consider each abstraction layer approximately robust. Making things secure, then, is mostly about working within each abstraction layer, building systems that are secure under the assumptions of a given abstraction layer's validity. You write provably secure code, you educate people to resist psychological manipulations, you inoculate them against viral bioweapons, you implement robust security policies and high-quality governance systems, et cetera.
- In this view, security is a phatic problem, an once-and-done thing.
- In warfare terms, it's a paradigm in which sufficiently advanced static fortifications rule the day, and the bar for "sufficiently advanced" is not that high.
- If you look at it through a hacker's lens, you consider each abstraction layer inherently leaky. Making things secure, then, is mostly about discovering all the ways leaks could happen and patching them up. Worse yet, the tools you use to implement your patches are themselves leakily implemented. Proven-secure code is foiled by hardware vulnerabilities that cause programs to move to theoretically impossible states; the abstractions of human minds are circumvented by Basilisk hacks; the adversary intervenes on the logistical lines for your anti-bioweapon tools and sabotages them; robust security policies and governance systems are foiled by compromising the people implementing them rather than by clever rules-lawyering; and so on.
- In this view, security is an anti-inductive problem, an ever-moving target.
- In warfare terms, it's a paradigm that favors maneuver warfare, and static fortifications are just big dumb objects to walk around.
The mindsets also then differ regarding what they expect ASI to be good at.
"Mathematicians" expect really sophisticated within-layer performance: really good technology, really good logistics, really good rhetoric, et cetera. This can still make an ASI really, really powerful, powerful enough to defeat all of humanity combined. But ultimately, in any given engagement, ASI plays "by the rules", in a certain abstract sense. Each of its tools can in-principle be defended-against on the terms of the abstraction layer at which they're deployed. All it would take is counter-deploying systems that are sufficiently theoretically robust, and doing so on all abstraction layers simultaneously. Very difficult, but ultimately doable, and definitely not hopeless.
"Hackers" expect really good generalized hacking. No amount of pre-superintelligent preparation is going to suffice against it, because any given tool we deploy, any given secure system we set up, would itself have implementation-level holes in it that the ASI's schemes would be able to worm through. It may at best delay the ASI for a little bit, but the attack surface is too high-dimensional, and the ASI is able to plot routes through that high-dimensional space which we can't quite wrap our head around.
As you might've surmised, I favour the hacker mindset here.
Now, arguably, any given plot to compromise an abstraction layer is itself deployed from within some other abstraction layer, so a competent mathematician's mindset shouldn't really be weaker than a hacker's. For example, secure software is made insecure by exploiting hardware vulnerabilities, and "defend against hardware vulnerabilities" is something a mathematician is perfectly able to understand and execute on. Same for securing against Basilisk hacks, logistical sabotage, etc.
But the mathematician is still, in some sense, "not getting it"; still centrally thinks in terms of within-layer attacks, rather than native cross-layer attacks.
One core thing here is that a cross-layer attack doesn't necessarily look like a meaningful attack within the context of any one layer. For example, there's apparently an exploit where you modulate the RPM of a hard drive in order to exfiltrate data from an airgapped server using a microphone. By itself, placing a microphone next to an airgapped server isn't a "hardware attack" in any meaningful sense (especially if it doesn't have dedicated audio outputs), and some fiddling with a hard drive's RPM isn't a "software attack" either. Taken separately, within each layer, both just look like random actions. You therefore can't really discover (and secure against) this type of attack if, in any given instance, you reason in terms of a single abstraction layer.
So I think a hacker's mindset is the more correct way to look at the problem.
And, looking at things from within a hacker's mindset, I think it's near straight-up impossible for a non-superintelligence to build any nontrivially complicated system that would be secure against a superintelligent attack.
Like... Humanity vs. ASI is sometimes analogized to a chess battle, with one side arguing that Stockfish is guaranteed to beat any human, even if you don't know the exact sequence of moves it will play, and the other side joking that the human can just flip the board.
But, uh. In this metaphor, the one coming up with the idea to flip the board[1], instead of playing by the rules, would be the ASI, not the human.
- ^
Or, perhaps, to execute a pattern of chess-piece moves which, as the human reasons about them, push them onto trains of thought that ultimately trigger a trauma response in the human, causing them to resign.
Current take on the implications of "GPT-4b micro": Very powerful, very cool, ~zero progress to AGI, ~zero existential risk. Cheers.
First, the gist of it appears to be:
OpenAI’s new model, called GPT-4b micro, was trained to suggest ways to re-engineer the protein factors to increase their function. According to OpenAI, researchers used the model’s suggestions to change two of the Yamanaka factors to be more than 50 times as effective—at least according to some preliminary measures.
The model was trained on examples of protein sequences from many species, as well as information on which proteins tend to interact with one another. [...] Once Retro scientists were given the model, they tried to steer it to suggest possible redesigns of the Yamanaka proteins. The prompting tactic used is similar to the “few-shot” method, in which a user queries a chatbot by providing a series of examples with answers, followed by an example for the bot to respond to.
Crucially, if the reporting is accurate, this is not an agent. The model did not engage in autonomous open-ended research. Rather, humans guessed that if a specific model is fine-tuned on a specific dataset, the gradient descent would chisel into it the functionality that would allow it to produce groundbreaking results in the corresponding domain. As far as AGI-ness goes, this is functionally similar to AlphaFold 2; as far as agency goes, it's at most at the level of o1[1].
To speculate on what happened: Perhaps GPT-4b ("b" = "bio"?) is based on some distillation of an o-series model, say o3. o3's internals contain a lot of advanced machinery for mathematical reasoning. What this result shows, then, is that the protein-factors problem is in some sense a "shallow" mathematical problem that could be easily solved if you think about it the right way. Finding the right way to think about it is itself highly challenging, however – a problem teams of brilliant people have failed to crack – yet deep learning allowed to automate this search and crack it.
This trick likely generalizes. There may be many problems in the world that could be cracked this way[2]: those that are secretly "mathematically shallow" in this manner, and for which you can get a clean-enough fine-tuning dataset.
... Which is to say, this almost certainly doesn't cover social manipulation/scheming (no clean dataset), and likely doesn't cover AI R&D (too messy/open-ended, although I can see being wrong about this). (Edit: And if it Just Worked given any sorta-related sorta-okay fine-tuning dataset, the o-series would've likely generalized to arbitrary domains out-of-the-box, since the pretraining is effectively this dataset for everything. Yet it doesn't.)
It's also not entirely valid to call that "innovative AI", any more than it was valid to call AlphaFold 2 that. It's an innovative way of leveraging gradient descent for specific scientific challenges, by fine-tuning a model pre-trained in a specific way. But it's not the AI itself picking a field to innovate and then producing the innovation; it's humans finding a niche which this class of highly specific (and highly advanced) tools can fill.
It's not the type of thing that can get out of human control.
So, to restate: By itself, this seems like a straightforwardly good type of AI progress. Zero existential risk or movement in the direction of existential risks, tons of scientific and technological utility.
Indeed, on the contrary: if that's the sort of thing OpenAI employees are excited about nowadays, and what their recent buzz about AGI in 2025-2026 and innovative AI and imminent Singularity was all about, that seems like quite a relief.
- ^
If it does runtime search. Which doesn't fit the naming scheme – should be "GPT-o3b" instead of "GPT-4b" or something – but you know how OpenAI is with their names.
- ^
And indeed,OpenAI-associated vaguepostingsuggests there's some other domain in which they'd recently produced a similar result.Edit: Having dug through the vagueposting further, yep, this is also something "in health and longevity", if this OpenAI hype man is to be believed.In fact, if we dig into their posts further – which I'm doing in the spirit of a fair-play whodunnit/haruspicy at this point, don't take ittooseriously – we can piece together a bit more.Thissuggests that the innovation is indeed based on applying fine-tuning to a RL'd model.Thisfurther implies that the intent of the new iteration of GPT-4b was to generalize it further. Perhaps it was fed not just the protein-factors dataset, but a breadth of various bioscience datasets, chiseling-in a more general-purpose model of bioscience on which a wide variety of queries could be ran?Note: this would still be a "cutting-edge biotech simulator" kind of capability, not an "innovative AI agent" kind of capability.Ignore that whole thing. On further research, I'm pretty sure all of this was substance-less trolling and no actual OpenAI researchers were involved. (At most, OpenAI's psy-ops team.)
For those also curious, Yamanaka factors are specific genes that turn specialized cells (e.g. skin, hair) into induced pluripotent stem cells (iPSCs) which can turn into any other type of cell.
This is a big deal because you can generate lots of stem cells to make full organs[1] or reverse aging (maybe? they say you just turn the cell back younger, not all the way to stem cells).
You can also do better disease modeling/drug testing: if you get skin cells from someone w/ a genetic kidney disease, you can turn those cells into the iPSCs, then into kidney cells which will exhibit the same kidney disease because it's genetic. You can then better understand how the [kidney disease] develops and how various drugs affect it.
So, it's good to have ways to produce lots of these iPSCs. According to the article, SOTA was <1% of cells converted into iPSCs, whereas the GPT suggestions caused a 50x improvement to 33% of cells converted. That's quite huge!, so hopefully this result gets verified. I would guess this is true and still a big deal, but concurrent work got similar results.
Too bad about the tumors. Turns out iPSCs are so good at turning into other cells, that they can turn into infinite cells (ie cancer). iPSCs were used to fix spinal cord injuries (in mice) which looked successful for 112 days, but then a follow up study said [a different set of mice also w/ spinal iPSCs] resulted in tumors.
My current understanding is this is caused by the method of delivering these genes (ie the Yamanaka factors) through retrovirus which
is a virus that uses RNA as its genomic material. Upon infection with a retrovirus, a cell converts the retroviral RNA into DNA, which in turn is inserted into the DNA of the host cell.
which I'd guess this is the method the Retro Biosciences uses.
I also really loved the story of how Yamanaka discovered iPSCs:
Induced pluripotent stem cells were first generated by Shinya Yamanaka and Kazutoshi Takahashi at Kyoto University, Japan, in 2006.[1] They hypothesized that genes important to embryonic stem cell (ESC) function might be able to induce an embryonic state in adult cells. They chose twenty-four genes previously identified as important in ESCs and used retroviruses to deliver these genes to mouse fibroblasts. The fibroblasts were engineered so that any cells reactivating the ESC-specific gene, Fbx15, could be isolated using antibiotic selection.
Upon delivery of all twenty-four factors, ESC-like colonies emerged that reactivated the Fbx15 reporter and could propagate indefinitely. To identify the genes necessary for reprogramming, the researchers removed one factor at a time from the pool of twenty-four. By this process, they identified four factors, Oct4, Sox2, cMyc, and Klf4, which were each necessary and together sufficient to generate ESC-like colonies under selection for reactivation of Fbx15.
- ^
These organs would have the same genetics as the person who supplied the [skin/hair cells] so risk of rejection would be lower (I think)
According to the article, SOTA was <1% of cells converted into iPSCs
I don't think that's right, see https://www.cell.com/cell-stem-cell/fulltext/S1934-5909(23)00402-2
You're right! Thanks
For Mice, up to 77%
Sox2-17 enhanced episomal OKS MEF reprogramming by a striking 150 times, giving rise to high-quality miPSCs that could generate all-iPSC mice with up to 77% efficiency
For human cells, up to 9% (if I'm understanding this part correctly).
SOX2-17 gave rise to 56 times more TRA1-60+ colonies compared with WT-SOX2: 8.9% versus 0.16% overall reprogramming efficiency.
So seems like you can do wildly different depending on the setting (mice, humans, bovine, etc), and I don't know what the Retro folks were doing, but does make their result less impressive.
Thinking through it more, Sox2-17 (they changed 17 amino acids from Sox2 gene) was your linked paper's result, and Retro's was a modified version of factors Sox AND KLF. Would be cool if these two results are complementary.
Here's something that confuses me about o1/o3. Why was the progress there so sluggish?
My current understanding is that they're just LLMs trained with RL to solve math/programming tasks correctly, hooked up to some theorem-verifier and/or an array of task-specific unit tests to provide ground-truth reward signals. There are no sophisticated architectural tweaks, not runtime-MCTS or A* search, nothing clever.
Why was this not trained back in, like, 2022 or at least early 2023; tested on GPT-3/3.5 and then default-packaged into GPT-4 alongside RLHF? If OpenAI was too busy, why was this not done by any competitors, at decent scale? (I'm sure there are tons of research papers trying it at smaller scales.)
The idea is obvious; doubly obvious if you've already thought of RLHF; triply obvious after "let's think step-by-step" went viral. In fact, I'm pretty sure I've seen "what if RL on CoTs?" discussed countless times in 2022-2023 (sometimes in horrified whispers regarding what the AGI labs might be getting up to).
The mangled hidden CoT and the associated greater inference-time cost is superfluous. DeepSeek r1/QwQ/Gemini Flash Thinking have perfectly legible CoTs which would be fine to present to customers directly; just let them pay on a per-token basis as normal.
Were there any clever tricks involved in the training? Gwern speculates about that here. But none of the follow-up reasoning models have a o1-style deranged CoT, so the more straightforward approaches probably Just Work.
Did nobody have the money to run the presumably compute-intensive RL-training stage back then? But DeepMind exists. Did nobody have the attention to spare, with OpenAI busy upscaling/commercializing and everyone else catching up? Again, DeepMind exists: my understanding is that they're fairly parallelized and they try tons of weird experiments simultaneously. And even if not DeepMind, why have none of the numerous LLM startups (the likes of Inflection, Perplexity) tried it?
Am I missing something obvious, or are industry ML researchers surprisingly... slow to do things?
(My guess is that the obvious approach doesn't in fact work and you need to make some weird unknown contrivances to make it work, but I don't know the specifics.)
So, Project Stargate. Is it real, or is it another "Sam Altman wants $7 trillion"? Some points:
- The USG invested nothing in it. Some news outlets are being misleading about this. Trump just stood next to them and looked pretty, maybe indicated he'd cut some red tape. It is not an "AI Manhattan Project", at least, as of now.
- Elon Musk claims that they don't have the money and that SoftBank (stated to have "financial responsibility" in the announcement) has less than $10 billion secured. If true, while this doesn't mean they can't secure an order of magnitude more by tomorrow, this does directly clash with "deploying $100 billion immediately" statement.
- But Sam Altman counters that Musk's statement is "wrong", as Musk "surely knows".
- I... don't know which claim I distrust more. Hm, I'd say Altman feeling the need to "correct the narrative" here, instead of just ignoring Musk, seems like a sign of weakness? He doesn't seem like the type to naturally get into petty squabbles like this, otherwise.
- (And why, yes, this is how an interaction between two Serious People building world-changing existentially dangerous megaprojects looks like. Apparently.)
- Some people try to counter Musk's claim by citing Satya Nadella's statement that Satya's "good for his $80 billion". But that's not referring to Stargate, that's about Azure. Microsoft is not listed as investing in Stargate at all, it's only a "technology partner".
- Here's a brief analysis from the CIO of some investment firm. He thinks it's plausible that the stated "initial group of investors" (SoftBank, OpenAI, Oracle, MGX) may invest fifty billion dollars into it over the next four years; not five hundred billion.
- They don't seem to have the raw cash for even $100 billion – and if SoftBank secured the missing funding from some other set of entities, why aren't they listed as "initial equity funders" in the announcement?
Overall, I'm inclined to fall back on @Vladimir_Nesov's analysis here. $30-50 billion this year seems plausible. But $500 billion is, for now, just Altman doing door-in-the-face as he had with his $7 trillion.
I haven't looked very deeply into it, though. Additions/corrections welcome!
Some more evidence that whatever the AI progress on benchmarks is measuring, it's likely not measuring what you think it's measuring:
AIME I 2025: A Cautionary Tale About Math Benchmarks and Data Contamination
AIME 2025 part I was conducted yesterday, and the scores of some language models are available here:
https://matharena.ai thanks to @mbalunovic, @ni_jovanovic et al.I have to say I was impressed, as I predicted the smaller distilled models would crash and burn, but they actually scored at a reasonable 25-50%.
That was surprising to me! Since these are new problems, not seen during training, right? I expected smaller models to barely score above 0%. It's really hard to believe that a 1.5B model can solve pre-math olympiad problems when it can't multiply 3-digit numbers. I was wrong, I guess.
I then used openai's Deep Research to see if similar problems to those in AIME 2025 exist on the internet. And guess what? An identical problem to Q1 of AIME 2025 exists on Quora:
https://quora.com/In-what-bases-b-does-b-7-divide-into-9b-7-without-any-remainder
I thought maybe it was just coincidence, and used Deep Research again on Problem 3. And guess what? A very similar question was on math.stackexchange:
https://math.stackexchange.com/questions/3548821/
Still skeptical, I used Deep Research on Problem 5, and a near identical problem appears again on math.stackexchange:
I haven't checked beyond that because the freaking p-value is too low already. Problems near identical to the test set can be found online.
So, what--if anything--does this imply for Math benchmarks? And what does it imply for all the sudden hill climbing due to RL?
I'm not certain, and there is a reasonable argument that even if something in the train-set contains near-identical but not exact copies of test data, it's still generalization. I am sympathetic to that. But, I also wouldn't rule out that GRPO is amazing at sharpening memories along with math skills.
At the very least, the above show that data decontamination is hard.
Never ever underestimate the amount of stuff you can find online. Practically everything exists online.
I think one of the other problems with benchmarks is that they necessarily select for formulaic/uninteresting problems that we fundamentally know how to solve. If a mathematician figured out something genuinely novel and important, it wouldn't go into a benchmark (even if it were initially intended for a benchmark), it'd go into a math research paper. Same for programmers figuring out some usefully novel architecture/algorithmic improvement. Graduate students don't have a bird's-eye-view on the entirety of human knowledge, so they have to actually do the work, but the LLM just modifies the near-perfect-fit answer from an obscure publication/math.stackexchange thread or something.
I expect the same is the case with programming benchmarks, science-quiz benchmarks, et cetera.
Now, this doesn't necessarily mean that the AI progress has been largely illusory and that we're way further from AGI than the AI hype men would have you believe (although I am very tempted to make this very pleasant claim, and I do place plenty of probability mass on it).
But if you're scoring AIs by the problems they succeed at, rather than the problems they fail at, you're likely massively overestimating their actual problem-solving capabilities.
Edit: I've played with the numbers a bit more, and on reflection, I'm inclined to partially unroll this update. o3 doesn't break the trendline as much as I'd thought, and in fact, it's basically on-trend if we remove the GPT-2 and GPT-3 data-points (which I consider particularly dubious).
Regarding METR's agency-horizon benchmark:
I still don't like anchoring stuff to calendar dates, and I think the o3/o4-mini datapoints perfectly show why.
It would be one thing if they did fit into the pattern. If, by some divine will controlling the course of our world's history, OpenAI's semi-arbitrary decision about when to allow METR's researchers to benchmark o3 just so happened to coincide with the 2x/7-month model. But it didn't: o3 massively overshot that model.[1]
Imagine a counterfactual in which METR's agency-horizon model existed back in December, and OpenAI invited them for safety testing/benchmarking then, four months sooner. How different would the inferred agency-horizing scaling laws have been, how much faster the extrapolated progress? Let's run it:
- o1 was announced September 12th, o3 was announced December 19th, 98 days apart.
- o1 scored at ~40 minutes, o3 at ~1.5 hours, a 2.25x'ing.
- There's ~2.14 intervals of 98 days in 7 months.
- Implied scaling factor: each 7 months.
And I don't see any reasons to believe it was overdetermined that this counterfactual wouldn't have actualized. METR could have made the benchmark a few months earlier, OpenAI could have been more open about benchmarking o3.
And if we lived in that possible world... It's now been 135 days since December 19th, i. e., ~1.38 intervals of 98 days. Extrapolating, we should expect the best publicly known model would have the time horizon of . I don't think we have any hint that those exist.
So: in that neighbouring world in which OpenAI let METR benchmark o3 sooner, we're looking around and seeing that the progress is way behind the schedule.[2]
To me, this makes the whole model fall apart. I don't see how it can follow any mechanistic model-based reality of what's happening, and as per the o3/o4-mini data points, it doesn't predict the empirical reality as well. Further, whether we believe that the progress is much faster vs. much slower than expected is entirely controlled by the arbitrary fact that METR didn't get to benchmark o3 in December.
I think we're completely at sea.
- ^
o3's datapoint implies a 4x/7-month model, no? Correct me if I'm wrong:
- Sonnet 3.7 was released 24th of February, 2025; o3's System Card and METR's reports were released 16th of April, 2025: 51 days apart.
- Sonnet 3.7 is benchmarked as having 1-hour agency; o3 has 1.5x that, ~1.5-hour agency.
- 7 months contain 3.5 two-month intervals. This means that, if horizons extend as fast as they did between 3.7 and o3, we should expect a x'ing of agency horizons each 7 months.
- ^
Edit: Yes, counterfactual!METR wouldn't have used just those two last data points, so the inferred multiplier would've been somewhat less than that. But I think it would've still been bigger than 2x/7-months, and the graph would've been offset to the left (the 1.5-hour performance achieved much earlier), so we'd still be overdue for ~2.5-hour AIs. Half-a-year behind, I think?
Do you also dislike Moore's law?
I agree that anchoring stuff to release dates isn't perfect because the underlying variable of "how long does it take until a model is released" is variable, but I think is variability is sufficiently low that it doesn't cause that much of an issue in practice. The trend is only going to be very solid over multiple model releases and it won't reliably time things to within 6 months, but that seems fine to me.
I agree that if you add one outlier data point and then trend extrapolate between just the last two data points, you'll be in trouble, but fortunately, you can just not do this and instead use more than 2 data points.
This also means that I think people shouldn't update that much on the individual o3 data point in either direction. Let's see where things go for the next few model releases.
Do you also dislike Moore's law?
That one seems to work more reliably, perhaps because it became the metric the industry aims for.
I agree that if you add one outlier data point and then trend extrapolate between just the last two data points, you'll be in trouble
My issue here is that there wasn't that much variance in the performance of all preceding models they benchmarked: from GPT-2 to Sonnet 3.7, they seem to almost perfectly fall on the straight line. Then, the very first advancement of the frontier after the trend-model is released is an outlier. That suggests an overfit model.
I do agree that it might just be a coincidental outlier and that we should wait and see whether the pattern recovers with subsequent model releases. But this is suspicious enough I feel compelled to make my prediction now.
The dates used in our regression are the dates models were publicly released, not the dates we benchmarked them. If we use the latter dates, or the dates they were announced, I agree they would be more arbitrary.
Also, there is lots of noise in a time horizon measurement and it only displays any sort of pattern because we measured over many orders of magnitude and years. It's not very meaningful to extrapolate from just 2 data points; there are many reasons one datapoint could randomly change by a couple of months or factor of 2 in time horizon.
- Release schedules could be altered
- A model could be overfit to our dataset
- One model could play less well with our elicitation/scaffolding
- One company could be barely at the frontier, and release a slightly-better model right before the leading company releases a much-better model.
All of these factors are averaged out if you look at more than 2 models. So I prefer to see each model as evidence of whether the trend is accelerating or slowing down over the last 1-2 years, rather than an individual model being very meaningful.
The dates used in our regression are the dates models were publicly released, not the dates we benchmarked them
Fair, also see my un-update edit.
Have you considered removing GPT-2 and GPT-3 from your models, and seeing what happens? As I'd previously complained, I don't think they can be part of any underlying pattern (due to the distribution shift in the AI industry after ChatGPT/GPT-3.5). And indeed: removing them seems to produce a much cleaner trend with a ~130-day doubling.
Sooo, apparently OpenAI's mysterious breakthrough technique for generalizing RL to hard-to-verify domains that scored them IMO gold is just... "use the LLM as a judge"? Sources: the main one is paywalled, but this seems to capture the main data, and you can also search for various crumbs here and here.
The technical details of how exactly the universal verifier works aren’t yet clear. Essentially, it involves tasking an LLM with the job of checking and grading another model’s answers by using various sources to research them.
My understanding is that they approximate an oracle verifier by an LLM with more compute and access to more information and tools, then train the model to be accurate by this approximate-oracle's lights.
Now, it's possible that the journalists are completely misinterpreting the thing they're reporting on, or that it's all some galaxy-brained OpenAI op to mislead the competition. It's also possible that there's some incredibly clever trick for making it work much better than how it sounds like it'd work.
But if that's indeed the accurate description of the underlying reality, that's... kind of underwhelming. I'm curious how far this can scale, but I'm not feeling very threatened by it.
(Haven't seen this discussed on LW, kudos to @lwreader132 for bringing it to my attention.)
Here's a potential interpretation of the market's apparent strange reaction to DeepSeek-R1 (shorting Nvidia).
I don't fully endorse this explanation, and the shorting may or may not have actually been due to Trump's tariffs + insider trading, rather than DeepSeek-R1. But I see a world in which reacting this way to R1 arguably makes sense, and I don't think it's an altogether implausible world.
If I recall correctly, the amount of money globally spent on inference dwarfs the amount of money spent on training. Most economic entities are not AGI labs training new models, after all. So the impact of DeepSeek-R1 on the pretraining scaling laws is irrelevant: sure, it did not show that you don't need bigger data centers to get better base models, but that's not where most of the money was anyway.
And my understanding is that, on the inference-time scaling paradigm, there isn't yet any proven method of transforming arbitrary quantities of compute into better performance:
- Reasoning models are bottlenecked on the length of CoTs that they've been trained to productively make use of. They can't fully utilize even their context windows; the RL pipelines just aren't up to that task yet. And if that bottleneck were resolved, the context-window bottleneck would be next: my understanding is that infinite context/"long-term" memories haven't been properly solved either, and it's unknown how they'd interact with the RL stage (probably they'd interact okay, but maybe not).
- o3 did manage to boost its ARC-AGI and (maybe?) FrontierMath performance by... generating a thousand guesses and then picking the most common one...? But who knows how that really worked, and how practically useful it is. (See e. g. this, although that paper examines a somewhat different regime.)
- Agents, from Devin to Operator to random open-source projects, are still pretty terrible. You can't set up an ecosystem of agents in a big data center and let them rip, such that the ecosystem's power scales boundlessly with the data center's size. For all but the most formulaic tasks, you still need a competent human closely babysitting everything they do, which means you're still mostly bottlenecked on competent human attention.
Suppose that you don't expect the situation to improve: that the inference-time scaling paradigm would hit a ceiling pretty soon, or that it'd converge to distilling search into forward passes (such that the end users end up using very little compute on inference, like today), and that agents just aren't going to work out the way the AGI labs promise.
In such a world, a given task can either be completed automatically by an AI for some fixed quantity of compute X, or it cannot be completed by an AI at all. Pouring ten times more compute on it does nothing.
In such a world, if it were shown that the compute needs of a task can be met with ten times less compute than previously expected, this would decrease the expected demand for compute.
The fact that capable models can be run locally might increase the number of people willing to use them (e. g., those very concerned about data privacy), as might the ability to automatically complete 10x as many trivial tasks. But it's not obvious that this demand spike will be bigger than the simultaneous demand drop.
And I, at least, when researching ways to set up DeepSeek-R1 locally, found myself more drawn to the "wire a bunch of Macs together" option, compared to "wire a bunch of GPUs together" (due to the compactness). If many people are like this, it makes sense why Nvidia is down while Apple is (slightly) up. (Moreover, it's apparently possible to run the full 671b-parameter version locally, and at a decent speed, using a pure RAM+CPU setup; indeed, it appears cheaper than mucking about with GPUs/Macs, just $6,000.)
This world doesn't seem outright implausible to me. I'm bearish on agents and somewhat skeptical of inference-time scaling. And if inference-time scaling does deliver on its promises, it'll likely go the way of search-and-distill.
On balance, I don't actually expect the market to have any idea what's going on, so I don't know that its reasoning is this specific flavor of "well-informed but skeptical". And again, it's possible the drop was due to Trump, nothing to do with DeepSeek at all.
But as I'd said, this reaction to DeepSeek-R1 does not seem necessarily irrational/incoherent to me.
The bet that "makes sense" is that quality of Claude 3.6 Sonnet, GPT-4o and DeepSeek-V3 is the best that we're going to get in the next 2-3 years, and DeepSeek-V3 gets it much cheaper (less active parameters, smaller margins from open weights), also "suggesting" that quality is compute-insensitive in a large range, so there is no benefit from more compute per token.
But if quality instead improves soon (including by training DeepSeek-V3 architecture on GPT-4o compute), and that improvement either makes it necessary to use more compute per token, or motivates using inference for more tokens even with models that have the same active parameter count (as in Jevons paradox), that argument doesn't work. Also, the ceiling of quality at the possible scaling slowdown point depends on efficiency of training (compute multiplier) applied to the largest training system that the AI economics will support (maybe 5-15 GW without almost-AGI), and improved efficiency of DeepSeek-V3 raises that ceiling.
Some thoughts on protecting against LLM steganography.
tl;dr: I suspect the Paraphraser idea is near-completely ineffectual as you scale the capabilities, both for scheming and for general CoT interpretability.
In the reasoning-as-communication framework, the amount of information a fixed-length message/CoT can transfer is upper-bounded by information-theoretic constraints. That is, if we have a ten-bit message, it cannot communicate more than ten bits of information: it cannot always uniquely specify one internal state of an AI model from more than internal states.
However, the amount of information is not lower-bounded. Depending on the decoder, a ten-bit message can communicate between zero and ten bits of information. (A decoder that's just a constant function recovers zero bits, a decoder that only pays attention to the first bit recovers only one bit, et cetera.)
The idea of steganography is that, if we pick a CoT string, and run both an AI model's internal decoders and a human's language-comprehension decoders on it, the AI model would extract more bits of information from it. Paraphrasing, humans' decoders are "coarser": they have broader equivalence classes of messages that map to the same internal representation, compared to AI models.
For example, "a dog crossed the street" and "a dog traveled across the street" might map to the same internal representation for a human, but to different ones for an AI model. Similarly, things like "quantum butterflies juggled metaphysical spaghetti" and "ambitious lampshade collected vintage moonbeams" can map to the same "nonsense" internal representation in humans, but have some useful meaning for AI models. The bits a human fails to make use of correspond to "steganography" or "superhuman latent knowledge".
Proposals such as Shoggoth + Paraphraser + Face aim to destroy any information in CoTs that cannot be recovered by humans, by mapping each CoT string to the equivalence class of strings that all map to the same internal representation in humans.
However, there's an issue: what if the empty string already communicates plenty of steganographically encoded information that humans aren't privy to? That is: what if some knowledge is hard-coded into an AI model, such that it's elicited on any activation, and leads to it converging towards reaching the same hidden conclusions even after we destroy its ability to sneak-in additional query-relevant information?
For example:
- If the AI model implicitly learned the Theory of Everything, that knowledge is going to be activated on any prompt – and so, no amount of paraphrasing is going to force it to talk about the Theory of Everything in humanese. Communicating the ToE from one instance of the model to its future self takes up zero bits.
- If the AI model has internalized some hidden goals, the heuristics for pursuing those goals are likewise going to be activated on any prompt, and it would engage in massively productive hidden scheming on any prompt. Importantly, the information-bottleneck constraints imposed by the Paraphraser wouldn't even be hitting the hidden-plotting compartment specifically. They'd just uniformly lower the model's computational power.
- E. g., in the Shoggoth + Paraphraser + Face paradigm, that'd just mean the model learns to think in longer CoTs (because it needs longer messages to communicate the same amount of information), not to do fewer "sneaky" computations.[1]
Like, imagine that we have two different internal-representation sets: , containing problem-solving strategies for the overt task we're presenting the model, and , related to some misaligned scheming. We would like to constrain the model such that it cannot plan about ; such that its CoTs contain zero bits for narrowing down which state out of all it must pick.
This assumes something like the following model: A given CoT string communicates some bits of information. Of them, bits are human-legible. The model then follows the algorithm of: use task-relevant bits on picking a state out of , and use any leftover bits to pick a state out of . We then destroy the string's information content until (via the Paraphraser). Now the model doesn't have the ability to encode any non-human-legible bits, and if it uses any bits on picking a state out of , they would necessarily be human-legible, and we can spot the scheming by reading the CoT.
But that's not how this works. Instead, the model picks both simultaneously: a CoT is directly mapped to an two-tuple. Which means if the model can narrow down the state of to one out of , it can narrow down the state of to one out of in the same move. Even if we scramble the CoT until it communicates no more bits than a human can extract out of it, that doesn't differentially constrain the model's ability to think about scheming (= communicate scheming-relevant information to its future self).
It's a uniform communication constraint/computational-complexity penalty.
Generalizing beyond scheming: if the model were inclined to not put any of its thoughts into humanese (due to superhuman latent knowledge, say), the Paraphraser wouldn't address this issue either. If a model's plans contain some catastrophic side-effects (which aren't even malign, just something we didn't tell it not to cause), the Paraphraser wouldn't reveal that either.
@Daniel Kokotajlo, thoughts?
(This doesn't touch on the Face part of the proposal, i. e., the idea that we want to not pressure the model to conceal any scheme-y cognition in the hopes it'd naively reveal them. But if there's some pressure to conceal that, the Paraphraser would not help with it at all. It'd just teach the model to map humanese-equivalent strings to equivalent scheming-states, which isn't particularly useful.)
- ^
Arguably, if you also penalize the CoT length, this should cause a pressure towards throwing out any computations unrelated to the object-level problem the model's being trained on... But then the whole "paraphraser" bit doesn't actually do anything, you can achieve the same outcome by just directly penalizing the CoT length.
Which, inasmuch as DL training loops use some form of simplicity prior, should be happening by default anyway. I. e., this doesn't address the pressures that we expect to lead to steganography/hidden plotting despite the simplicity prior: which is to say, arguments that steganography/plotting are the actual optimal solutions to the training problem.
Consider the Theory of Everything example: those hidden computations are not actually "irrelevant computations" that we need to displace, they're directly useful. Similarly, any misaligned mesa-objectives the model forms would presumably be convergently useful for performance on the training objective: that would be why they formed to begin with. So the information-bottleneck trickery would do ~nothing against them.
I like to distinguish between "Subtle strategic bias" and "Steganography." Paraphrasers help (and maybe solve?) the latter, but do nothing about the former.
Example of subtle strategic bias: The model knows it's misaligned and therefore deliberately sandbags on the alignment research you are asking it to do. "I'm sorry sir I just am not making much progress," it says. You look at the CoT, and it's just doing a bunch of sensible but fruitless lines of reasoning.
Example of steganography: The model needs to insert a subtle security vulnerability into the code it is writing -- but it doesn't know one right away, it has to invent one. And that requires lots of sequential thought. So it needs to try out different ideas, vet them, critique them, refine them, etc. Can't do that in a single forward pass. So it needs to pass information forward to its future self somehow... without humans reading the CoT knowing that's what it's doing. THIS is the sort of thing that is much harder to do with a paraphraser than without a paraphraser.
I don't see why it would be harder to do.
Suppose you tasked a model with refactoring some database, and it secretly wants to sabotage its functionality. It outputs a CoT segment that goes, "I need to design unit tests for this module". Each word of this CoT is mapped to some internal representation, and the internal representation consists of "on-task" human-intended reasoning , and misaligned scheming (corresponding to, e. g., a tactical decision to fail to include unit tests for some subtle issue). "I" is mapped to , "need" is mapped to , etc. Each iterates on , each iterates on , we have a sequence of serial computations.
In other words: as the model outputs, "I need to design unit tests for this module", there's an unspoken subtext of "I need to sabotage the unit tests here", and the model packs nine words' worth of serial computations into both the "textual" and the "subtextual" aspects of it.
Now you use the Paraphraser on the string, generating alternatives like "the next step is to generate some unit tests" and "several unit tests for this module are needed here". The intent, if I understand you correctly, is that the semantic-equivalence-but-syntactic-difference would ensure that the th token of this phrase is mapped to , as if the paraphrasing didn't happen, but that the mapping of would be broken.
Except, why would that happen? What privileges -representations over -representations? Why would be preserved whereas is broken, instead of both of them remaining functional (and so preserving scheming), or both breaking (and so compromising the model's capabilities)?
In other words: We're basically just teaching the model to fail to distinguish between equivalent-to-a-human rephrasings. Why would this lead to the task-related representations becoming indifferent to the specifics of a phrasing whereas the scheming-related representations remain sensitive to it? Why wouldn't this just map the subtextual "I need to sabotage the unit tests here" to similarly semantically-equivalent-but-syntactically-different "let us compromise the relevant unit-test suite" or "I shall ensure the unit tests don't work properly"?
I expect it'd just lead, to wit, to the model's computations becoming indifferent to the details of a phrasing in full generality. And if the model were inclined to associate the general idea of generating unit tests with tactically screwing the task up, the model would come up with this idea regardless of the details of a phrasing.
It wouldn't interfere with its ability to engage in scheming-relevant serial computations, much like it doesn't interfere with its ability to engage in task-relevant serial computations, for the exact same reasons.
I don't think I understand. Let's work through an example.
The AI is being told to write good code, and wants to write subtly-vulnerable code instead. If it just were to honestly try to write good code, it would take (let's say) 100 serial steps of reasoning to succeed. To write subtly-vulnerable code, let's say, requires 300 serial steps of reasoning. The model's strategy is to write subtly-vulnerable code but in a way that looks like it's trying to write good code and just getting a bit unlucky and taking longer than usual (let's suppose the humans have a poor ability to judge how long it's supposed to take, but still some ability, such that it can't take e.g. 10x longer without arousing suspicion).
If there's no paraphraser, this is 'easy.' I mean it's still difficult but it's 'easy' in the sense that the AI can basically just use a code -- each nugget of reasoning might have 10 different semantically equivalent expressions, or maybe even 100, so it can 'add extra layers of meaning' to the nuggets -- in addition to their meaning in the surface level i'm-tring-to-write-good-code, they can have a hidden meaning having to do with the security vulnerability-related properties of the code. And it can make a chain of reasoning that is basically about the security stuff while looking like a reasonable but unlucky attempt to write good code.
But a paraphraser wrecks that strategy. The model can still add extra layers of meaning to the nuggets, but now it has loads of trouble making the chain of thought look like an honest attempt to write good code. To use your example, if 'I should generate unit tests now' and all semantically equivalent variants of that idea are assigned the hidden meaning 'I should check to see if the vulnerability is too easy to spot' for example, then... what is it going to write next? It's too constrained; in order to look non-suspicious there is a limited set of options it can follow up with... ok, hmm, I'm at the limits of my understanding here. But maybe you get the idea?
...here's an intuition I think I'm drawing from. Suppose you're the model and you are trying to decide what hidden meanings to associate with what concepts/phrases/steps. If you already had your completed illicit reasoning chain and your completed good-boy reasoning chain, it would be easy -- just line them up and make a 1-1 mapping, and then bam no paraphraser can stop you! But you don't have either chain! That's the whole point -- this is a task that you haven't done yet, you need to explore some maze in logical space (or tree? Or graph?) until you find a chain that gets to the conclusion/answer.
Ah, I think I see my error.
Consider a CoT of the form "[problem statement]: ...........", which always outputs dots regardless of the problem statement. Can that still encode useful computations, with the information being passed through intermediate self-attention? Yes, but: this only increases parallel-computing capabilities, not serial-computing capabilities.
And in the framework I'd outlined, under the Paraphraser, for the purposes of scheme-y thinking, even a legible CoT would consist of such "filler" tokens.
So yep, you're right, this does force all scheming to be taking place within one forward pass.