Review
Review
Davidad's Bold Plan for Alignment: An In-Depth Explanation
17Ryan Greenblatt
15Fabien Roger
3Charbel-Raphael Segerie
0Chipmonk
1davidad (David A. Dalrymple)
New Comment
At the time when I first heard this agenda proposed, I was skeptical. I remain skeptical, especially about the technical work that has been done thus far on the agenda[1].
I think this post does a reasonable job of laying out the agenda and the key difficulties. However, when talking to Davidad in person, I've found that he often has more specific tricks and proposals than what was laid out in this post. I didn't find these tricks moved me very far, but I think they were helpful for understanding what is going on.
This post and Davidad's agenda overall would benefit from having concrete examples of how the approach might work in various cases, or more discussion of what would be out of scope (and why this could be acceptable). For instance, how would you make a superhumanly efficient (ASI-designed) factory that produces robots while proving safety? How would you allow for AIs piloting household robots to do chores (or is this out of scope)? How would you allow for the AIs to produce software that people run on their computers or to design physical objects that get manufactured? Given that this proposal doesn't allow for safely automating safety research, my understanding is that it is supposed to be a stable end state. Correspondingly, it is important to know what Davidad thinks can and can't be done with this approach.
My core disagreements are on the "Scientific Sufficiency Hypothesis" (particularly when considering computational constraints), "Model-Checking Feasibility Hypothesis" (and more generally on proving the relevant properties), and on the political feasibility of paying the needed tax even if the other components work out. It seems very implausible to me that making a sufficiently good simulation is as easy as building the Large Hadron Collider. I think the objection in this comment holds up (my understanding is Davidad would require that we formally verify everything on the computer).[2]
As a concrete example, I found it quite implausible that you could construct and run a robot factory that is provably safe using the approach outlined in this proposal, and this sort of thing seems like a minimal thing you'd need to be able to do with AIs to make them useful.
My understanding is that most technical work has been on improving mathematical fundamentals (e.g. funding logicians and category theorists to work on various things). I think it would make more sense to try to demonstrate overall viability with minimal prototypes that address key cruxes. I expect this to fail and thus it would be better to do this earlier. If you expect these prototypes would work, then it seems interesting to demonstrate this as many people would find this very surprising. ↩︎
This is mostly unrelated, but when talking with Davidad, I've found that a potential disagreement is that he's substantially more optimistic about using elicitation to make systems that currently seem quite incapable (e.g., GPT-4) very useful. As a concrete example, I think we disagreed about the viability of running a fully autonomous Tesla factory for 1 year at greater than one-tenth productivity using just AI systems created prior to halfway through 2024. (I was very skeptical.) It's not exactly clear to me how this is a crux for the overall plan (beyond getting a non-sabotaged implementation of simulations) given that we still are aiming to prove safety either way, and proving properties of GPT-4 is not clearly much easier than proving properties of much smarter AIs. (Apologies if I've just forgotten.) ↩︎
I don't think I understand what is meant by "a formal world model".
For example, in the narrow context of "I want to have a screen on which I can see what python program is currently running on my machine", I guess the formal world model should be able to detect if the model submits an action that exploits a zero-day that tampers with my ability to see what programs are running. Does that mean that the formal world model has to know all possible zero-days? Does that mean that the software and the hardware have to be formally verified? Are formally verified computers roughly as cheap as regular computers? If not, that would be a clear counter-argument to "Davidad agrees that this project would be one of humanity's most significant science projects, but he believes it would still be less costly than the Large Hadron Collider."
Or is the claim that it's feasible to build a conservative world model that tells you "maybe a zero-day" very quickly once you start doing things not explicitly within a dumb world model?
I feel like this formally-verifiable computers claim is either a good counterexample to the main claims, or an example that would help me understand what the heck these people are talking about.
Ok, time to review this post and assess the overall status of the project.
Review of the post
What i still appreciate about the post: I continue to appreciate its pedagogy, structure, and the general philosophy of taking a complex, lesser-known plan and helping it gain broader recognition. I'm still quite satisfied with the construction of the post—it's progressive and clearly distinguishes between what's important and what's not. I remember the first time I met Davidad. He sent me his previous post. I skimmed it for 15 minutes, didn't really understand it, and thought, "There's no way this is going to work." Then I reconsidered, thought about it more deeply, and realized there was something important here. Hopefully, this post succeeded in showing that there is indeed something worth exploring! I think such distillation and analysis are really important.
I'm especially happy about the fact that we tried to elicit as much as we could from Davidad's model during our interactions, including his roadmap and some ideas of easy projects to get early empirical feedback on this proposal.
Current Status of the Agenda.
(I'm not the best person to write this, see this as an informal personal opinion)
Overall, Davidad performed much better than expected with his new job as program director in ARIA and got funded 74M$ over 4 years. And I still think this is the only plan that could enable the creation of a very powerful AI capable of performing a true pivotal act to end the acute risk period, and I think this last part is the added value of this plan, especially in the sense that it could be done in a somewhat ethical/democratic way compared to other forms of pivotal acts. However, it's probably not going to happen in time.
Are we on track? Weirdly, yes for the non-technical aspects, no for the technical ones? The post includes a roadmap with 4 stages, and we can check if we are on track. It seems to me that Davidad jumped directly to stage 3, without going through stages 1 and 2. This is because of having been selected as research director for ARIA, so he's probably going to do 1 and 2 directly from ARIA.
- Stage 1 Early Research Projects is not really accomplished:
- “Figure out the meta ontology theory”: Maybe the most important point of the four, currently WIP in ARIA, but a massive team of mathematicians has been hired to solve this.
- “Heuristics used by the solver”: Nope
- “Building a toy infra-Bayesian "Super Mario", and then applying this framework to model Smart Grids”: Nope
- “Training LLMs to write models in the PRISM language by backward distillation”: Kind of already here, probably not very high value to spend time here, I think this is going to be solved by default.
- Stage 2: Industry actors' first projects: I think this step is no longer meaningful because of ARIA.
- Stage 3: formal arrangement to get labs to collectively agree to increase their investment in OAA, is almost here, in the sense that Davidad got millions to execute this project in ARIA and he published his Multi-author manifesto which backs the plan with legendary names especially with Yoshua Bengio as the scientific director of this project.
The lack of prototyping is concerning. I would have really liked to see an "infra-Bayesian Super Mario" or something similar, as mentioned in the post. If it's truly simple to implement, it should have been done by now. This would help many people understand how it could work. If it's not simple, that would reveal it's not straightforward at all. Either way, it would be pedagogically useful for anyone approaching the project. If we want to make these values democratic, etc.. It's very regrettable that this hasn't been done after two years. (I think people from the AI Objectives Institute tried something at some point, but I'm not aware of anything publicly available.) I think this complete lack prototypes is my number one concern preventing me from recommending more "safe by design" agendas to policymakers.
This plan was an inspiration for constructability: It might be the case that the bold plan could decay gracefully, for example into constructability, by renouncing formal verification and only using traditional software engineering techniques.
International coordination is an even bigger bottleneck than I thought. The "CERN for AI" isn't really within the Overton window, but I think this applies to all the other plans, and not just Davidad's plan. (Davidad made a little analysis of this aspect here).
At the end of the day: Kudos to Davidad for successfully building coalitions, which is already beyond amazing! and he is really an impressive thought leader. What I'm waiting to see for the next year is using AIs such as O3 that are already impressive in terms of competitive programming and science knowledge, and seeing what we can already do with that. I remain excited and eager to see the next steps of this plan.
The formal desiderata should be understood, reviewed, discussed, and signed-off on by multiple humans. However, I don't have a strong view against the use of Copilot-style AI assistants. These will certainly be extremely useful in the world-modeling phase, and I suspect will probably also be worth using in the specification phase. I do have a strong view that we should have automated red-teamers try to find holes in the desiderata.
Gabin Kolly and Charbel-Raphaël Segerie contributed equally to this post. Davidad proofread this post.
Thanks to Vanessa Kosoy, Siméon Campos, Jérémy Andréoletti, Guillaume Corlouer, Jeanne S., Vladimir I. and Clément Dumas for useful comments.
Context
Davidad has proposed an intricate architecture aimed at addressing the alignment problem, which necessitates extensive knowledge to comprehend fully. We believe that there are currently insufficient public explanations of this ambitious plan. The following is our understanding of the plan, gleaned from discussions with Davidad.
This document adopts an informal tone. The initial sections offer a simplified overview, while the latter sections delve into questions and relatively technical subjects. This plan may seem extremely ambitious, but the appendix provides further elaboration on certain sub-steps and potential internship topics, which would enable us to test some ideas relatively quickly.
Davidad’s plan is an entirely new paradigmatic approach to address the hard part of alignment: The Open Agency Architecture aims at “building an AI system that helps us ethically end the acute risk period without creating its own catastrophic risks that would be worse than the status quo”.
This plan is motivated on the assumption that current paradigms for model alignment won’t be successful:
Unlike OpenAI's plan, which is a meta-level plan that delegates the task of finding a solution for alignment with future AI, davidad's plan is an object-level plan that takes drastic measures to prevent future problems. It is also based on rather testable assumptions that can be relatively quickly tested (see the annex).
Plan’s tldr: Utilize near-AGIs to build a detailed world simulation, train and formally verify within it that the AI adheres to coarse preferences and avoids catastrophic outcomes.
How to read this post?
This post is much easier to read than the original post. But we are aware that it still contains a significant amount of technicality. Here's a way to read this post gradually:
For more technical details, you can read:
Bird's-eye view
The plan comprises four key steps:
The plan is dubbed "Open Agency Architecture" because it necessitates collaboration among numerous humans, remains interpretable and verifiable, and functions more as an international organization or "agency" rather than a singular, unified "agent." The name Open Agency was drawn from Eric Drexler’s Open Agency Model, along with many high-level ideas.
Here is the main diagram. (An explanation of the notations is provided here):
Fine-grained Scheme
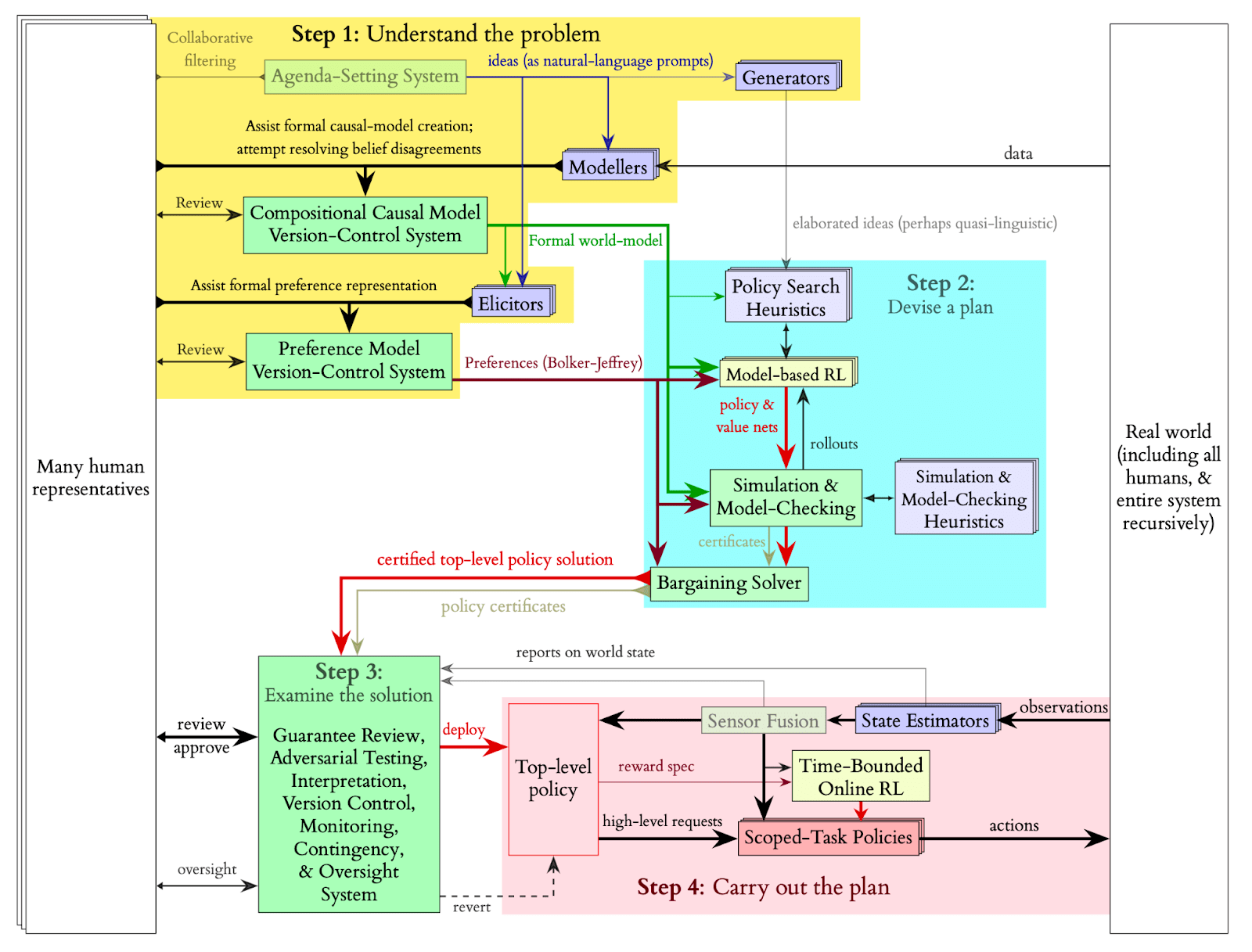
Here is a more detailed breakdown of Davidad’s plan:
Step 1: Understand the problem
Step 2: Devise a plan
Step 3 Examine the solution
Step 4 Carry out the plan
Hypotheses discussion
Scientific Sufficiency Hypothesis: This hypothesis posits that we will be able to create a simulation of the world that is precise enough so that verifying a model's behavior within the simulation would ensure its proper behavior in the real world. More specifically, as we are operating in an infra-Bayesian setting, we need a large enough set of world models to ensure that reality is not too distant. Additionally, this hypothesis includes the assumption that the simulation will not be excessively computationally demanding since we intend to train a model on it. Davidad agrees that this project would be one of humanity's most significant science projects, but he believes it would still be less costly than the Large Hadron Collider.
There are several challenges associated with the Scientific Sufficiency Hypothesis:
We believe that addressing the “Lack of computational Infra-bayes prior works” and “Flexible meta-ontology” concerns is crucial before delving too deep into this plan, as they can be tackled independently of the other aspects.
Deontic Sufficiency Hypothesis: This hypothesis posits that it is possible to identify desiderata that are adequate to ensure the model doesn't engage in undesirable behavior. Davidad is optimistic that it's feasible to find desiderata ensuring safety for a few weeks before a better solution is discovered, making this a weaker approach than solving outer alignment. For instance, Davidad suggests that even without a deep understanding of music, you can be confident your hearing is safe by ensuring the sound pressure level remains below 80 decibels. However, since the model would still be executing a pivotal process with significant influence, relying on a partial solution for decades could be risky. [More details]
Model-Checking Feasibility Hypothesis: This hypothesis states that it should be possible to prove bounds on the values the model will achieve for the desiderata. Given the task's magnitude, model-checking would mostly be done automatically. In the last few years, we have seen immense progress in the verification of neural networks. In 2017, the best methods were able to verify a hundred neurons, now in 2022, via branch and bound techniques, we can now verify networks of a million neurons [More details]. Currently, model-checking for RL agents is limited to simple environments, and the authors are uncertain if it can be scaled up within just a few years.
Time bounded Optimization Thesis: This hypothesis proposes that we can discover training techniques and reward functions that encourage time-bounded optimization behavior. A suggestion in this direction is provided here. This hypothesis allows us to bypass the problem of corrigibility quite simply: “we can define time-inhomogeneous reward [i.e. the reward becomes negative after a time-limit], and this provides a way of "composing" different reward functions; while this is not a way to build a shutdown button, it is a way to build a shutdown timer, which seems like a useful technique in our safety toolbox.”.
About Category theory and Infra-Bayesianism
Why Infra-Bayesianism: We want the world model we create to be accurate and resilient when facing uncertainty and errors in modeling, since we want it to perform well in real-world situations. Infra-bayesianism offers a way to address these concerns.
Why Category Theory: A key to effectively understanding the world may lie in exploring relationships and mappings. Functional programming and category theory are promising options for this task. Category theory enables us to represent complex relationships across various levels of abstraction, which is crucial for constructing a world model that incorporates different competitive theories at different scales of size and time in a collaborative manner. Moreover, it is useful to express infra-bayesianism within a category-theoretic framework. The main bottleneck currently appears to be creating an adequate meta-ontology using category theory. [More details here, and here]
High level criticism
Here are our main high level criticisms about the plan:
High Level Hopes
This plan has also very good properties, and we don’t think that a project of this scale is out of question:
Intuition pump for the feasibility of creating a highly detailed world model
Here's an intuition pump to demonstrate that creating a highly detailed world model might be achievable: Humans have already managed to develop Microsoft Flight Simulator or The Sims. There is a level of model capability at which these models will be capable of rapidly coding such realistic video games. Davidad’s plan, which involves reviewing 2 million scientific papers (among which only a handful contain crucial information) to extract scientific knowledge, is only a bit more difficult, and seems possible. Davidad tweeted this to illustrate this idea:
Comparison with OpenAI’s Plan
Comparison with OpenAI’s Plan: At least, David's plan is an object-level plan, unlike OpenAI's plan, which is a meta-level plan that delegates the role of coming up with a plan to smarter language models. However, this plan also requires very powerful language models to be able to formalize the world model, etc. Therefore, it seems to us that this plan also requires a level of capability that is also AGI. But at the same time, Davidad's plan might just be one of the plans that OpenAI's automatic alignment researchers could come up with. At least, davidad’s plan does not destroy the world with an AI race if it fails.
The main technical crux: We think the main difficulty is not this level of capability, but the fact that this level of capability is beyond the ability to publish papers at conferences like NeurIPS, which we perceive as the threshold for Recursive self-improvement. So this plan demands robust global coordination to avoid foom. And model helping at alignment research seems much more easily attainable than the creation of this world model, so OpenAI’s plan may still be more realistic.
Conclusion
This plan is crazy. But the problem that we are trying to solve is also crazy hard. The plan offers intriguing concepts, and an unorthodox approach is preferable to no strategy at all. Numerous research avenues could stem from this proposal, including automatic formalization and model verification, infra-Bayesian simulations, and potentially a category-theoretic mega-meta-ontology. As Nate Soares said : “I'm skeptical that davidad's technical hopes will work out, but he's in the rare position of having technical hopes plus a plan that is maybe feasible if they do work out”. We express our gratitude to Davidad for presenting this innovative plan and engaging in meaningful discussions with us.
EffiSciences played a role in making this post possible through their field building efforts.
Annex
Much of the content in this appendix was written by Davidad, and only lightly edited by us. The annex contains:
Governance strategy
Does OAA help with governance? Does it make certain governance problems easier/harder?
Here is davidad’s answer:
Roadmap
Here is the ambitious scaling roadmap where things play out as fast as possible is the following.
Stage 1: Early research projects
Timeline: Q3 2023. Tldr: Academic work done / PoC experiments
Experiment with the following internships (which are described in the last section of this annex):
Succeed at How to fine-tune a language model as a heuristic for model-checking?
Stage 2: Industry actors first projects
Timeline: Q4 2023. Tldr: Get industry actors interested, starting projects inside labs.
Needs:
Stage 3: Labs commitments
Timeline: Late 2024 or 2025. We need to get to Stage 3 no later than 2028. Tldr: Make a kind of formal arrangement to get labs to collectively agree to increase their investment in OAA. This is the critical thing.
Needs:
Stage 4: International consortium to build OAA.
Timelines: In order for this to not feel like a slowdown to capabilities accelerationists, we should credibly reach Stage 4 by 2029. Start chat & planning for it in 2024.
Some important testable first research projects
Formalization of the world model
We can get started on this by using an existing modeling language, such as PRISM, and applying methodologies being used for autoformalization (e.g. “distilled back translation”: starting with a big dataset of models in the language, like MCC, using the LLM to translate them into natural language, and then fine-tuning on the transpose of that dataset to get it to learn the formal language).
Try to fine-tune a language model as a heuristic for model-checking
Prompting/fine-tuning/RL’ing LLMs to be useful assistants in writing (and extending) formal world models and specifications. Here would be the process:
Defining a sufficiently expressive formal meta-ontology for world-models
Defining a sufficiently expressive formal meta-ontology for world-models with multiple scientific explanations at different levels of abstraction (and spatial and temporal granularity) having overlapping domains of validity, with all combinations of {Discrete, Continuous} and {time, state, space}, and using an infra-bayesian notion of epistemic state (specifically, convex compact down-closed subsets of subprobability space) in place of a Bayesian state. Here are 3 subjects of internship on this subtopic:
Experimenting with the compositional version control system
“Developing version-control formalisms and software tools that decompose these models in natural ways and support building complex models via small incremental patches (such each patch is fully understandable by a single human who is an expert in the relevant domain).’ This requires leveraging theories like double-pushout rewriting and δ-lenses to develop a principled version-control system for collaborative and forking edits to world-models, multiple overlapping levels of abstraction, incremental compilation in response to small edits.
Getting traction on the deontic feasibility hypothesis
Davidad believes that using formalisms such as Markov Blankets would be crucial in encoding the desiderata that the AI should not cross boundary lines at various levels of the world-model. We only need to “imply high probability of existential safety”, so according to davidad, “we do not need to load much ethics or aesthetics in order to satisfy this claim (e.g. we probably do not get to use OAA to make sure people don't die of cancer, because cancer takes place inside the Markov Blanket, and that would conflict with boundary preservation; but it would work to make sure people don't die of violence or pandemics)”. Discussing this hypothesis more thoroughly seems important.
Some other projects
Types explanation
Explanation in layman's terms of the types in the main schema. Those notations are the same as those used in reinforcement learning.