
Reframing Impact
9habryka
4Rohin Shah
3Logan Riggs
2Bird Concept
New Comment
Promoted to curated: I really liked this sequence. I think in many ways it has helped me think about AI Alignment from a new perspective, and I really like the illustrations and the way it was written, and how it actively helped me along the way thing actively about the problems, instead of just passively telling me solutions.
Now that the sequence is complete, it seemed like a good time to curate the first post in the sequence.
I'm nominating the entire sequence because it's brought a lot of conceptual clarity to the notion of "impact", and has allowed me to be much more precise in things I say about "impact".
This post (or sequence of posts) not only gave me a better handle on impact and what that means for agents, but it also is a concrete example of de-confusion work. The execution of the explanations gives an "obvious in hindsight" feeling, with "5-minute timer"-like questions which pushed me to actually try and solve the open question of an impact measure. It's even inspired me to apply this approach to other topics in my life that had previously confused me; it gave me the tools and a model to follow.
And, the illustrations are pretty fun and engaging, too.
Here are prediction questions for the predictions that TurnTrout himself provided in the concluding post of the Reframing Impact sequence.


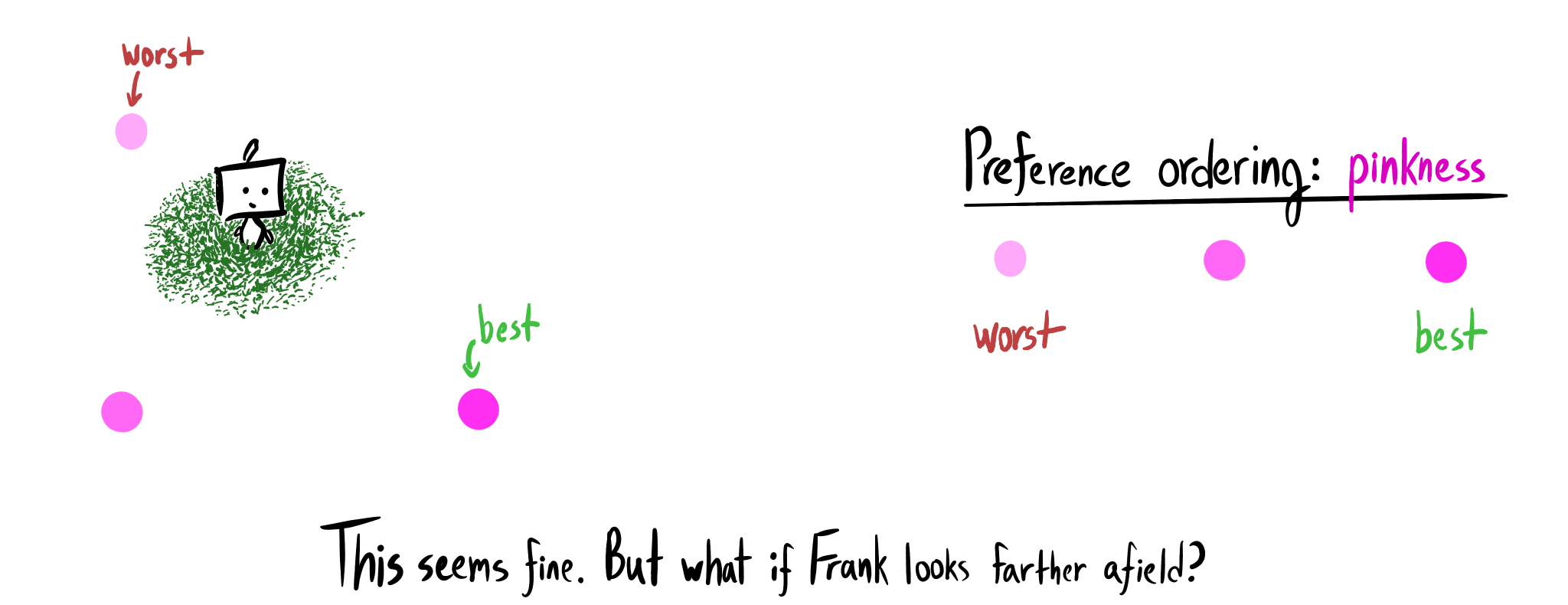
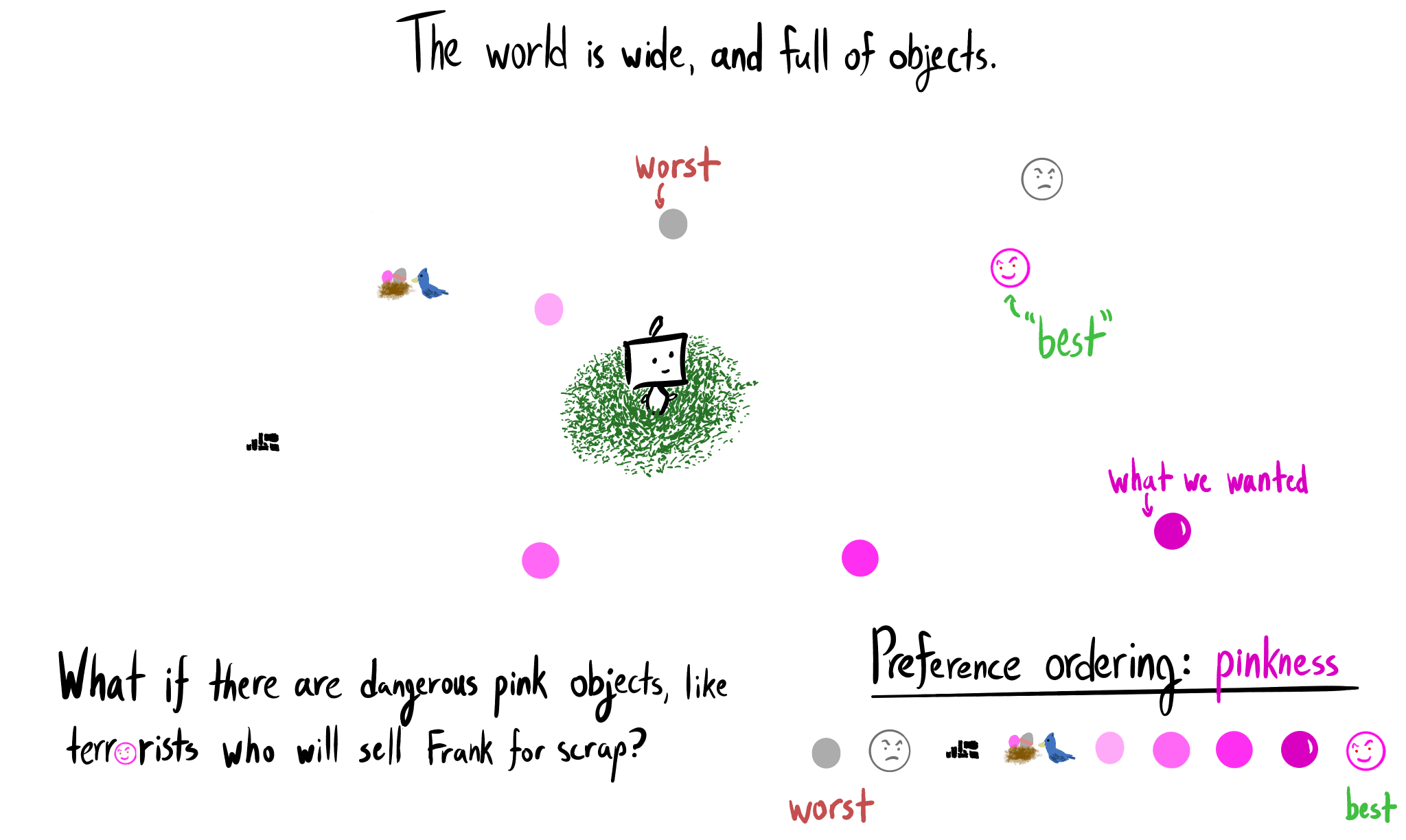

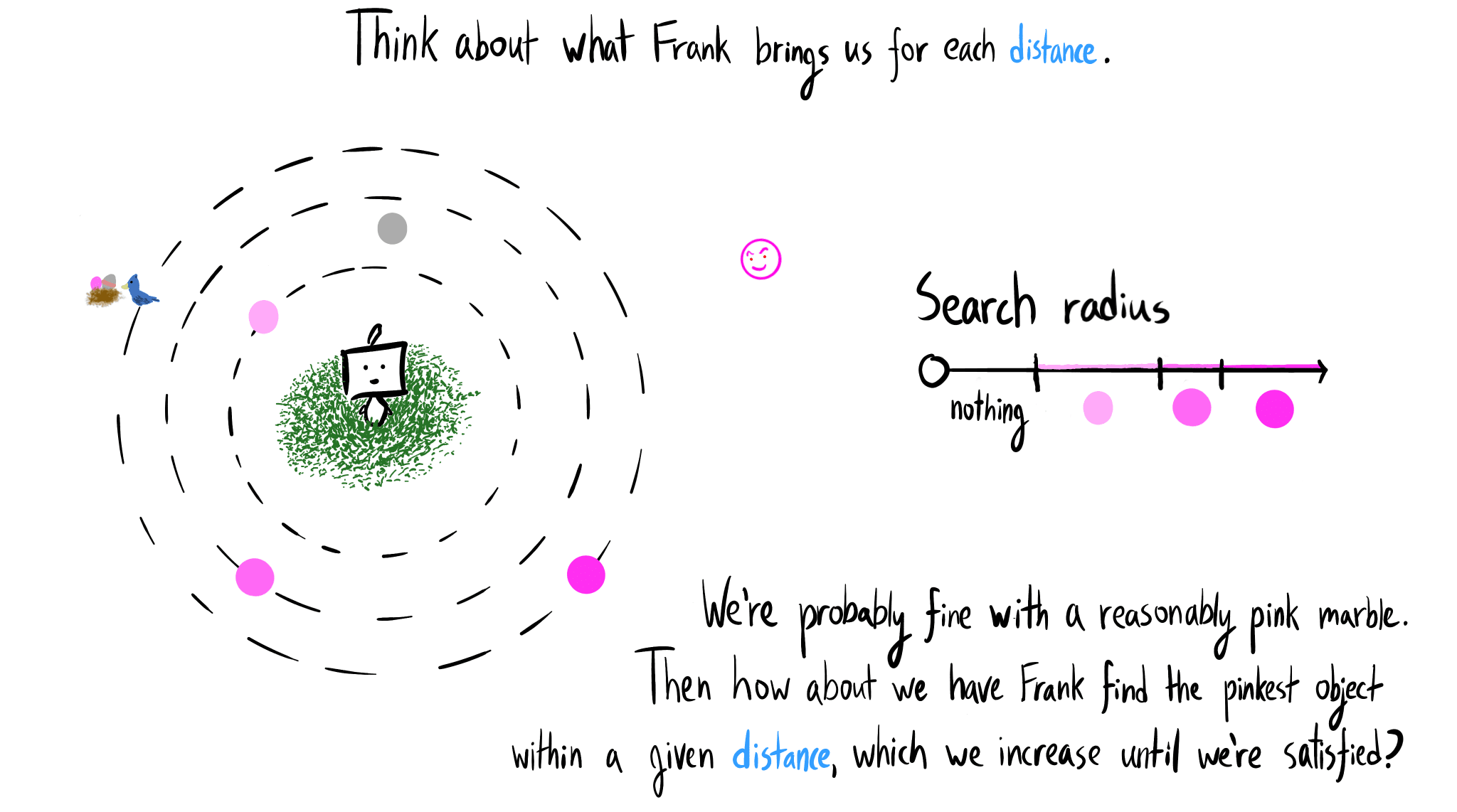


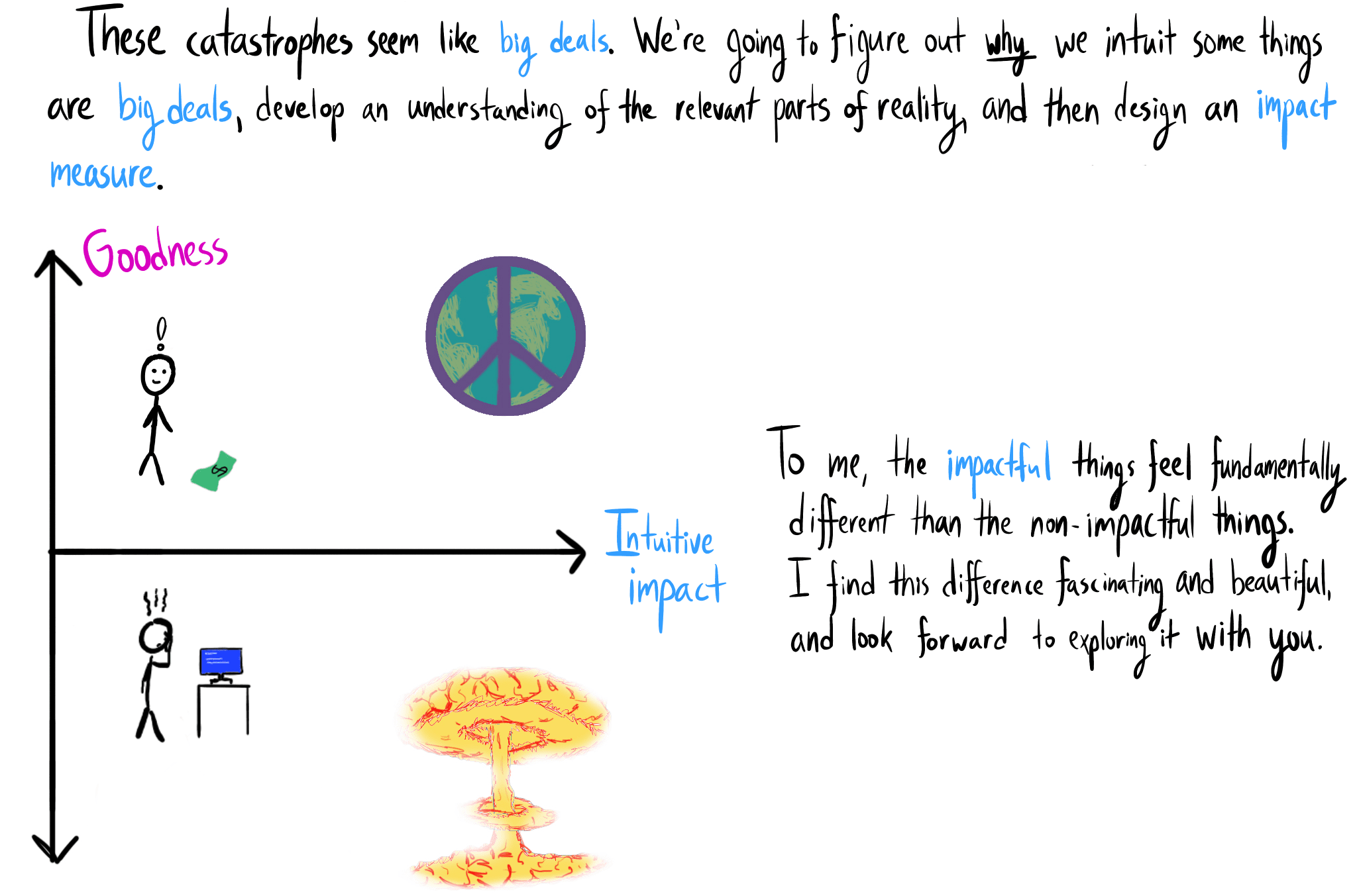



{kind=link}
{kind=link}
{kind=link}