Part 1 of 12 in the Engineer’s Interpretability Sequence.
If we want to reduce near and long term risks from AI, we should care a lot about interpretability tools. This is a very uncontroversial claim to make inside the AI safety community. Almost every agenda for safe advanced AI incorporates interpretability in some way. The key value of interpretability tools is that they aid in human oversight by enabling open-ended evaluation.
Short of actually deploying a system, any method of evaluating it can only be a proxy for its actual performance. The most common way to evaluate a model is by its performance in some test set or environment. But test sets alone can fail to reveal – and often incentivize – undesirable solutions involving overfitting, biases, deception, etc. This highlights the need for other ways to evaluate models, and an interpretability toolbox full of effective tools may go a long way.
Some of the seeds of the AI safety community’s interest in interpretability were planted by Distill in 2017. But 2022 was an inflection point with a massive new surge in interest and work on interpretability tools. Anthropic was founded a little over a year ago. ARC started less than a year ago. Redwood has begun to push for much more interpretability work, including with the REMIX program. We are seeing a number of pushes to get many more people involved in interpretability work. And as someone on the ground, I have subjectively observed a surge in interest over 2022. And the popularity of interpretability hasn’t been limited to the AI safety community. There is now so much work in interpretability that we now have a dataset of 5199 interpretability papers (Jacovi, 2023). See also a survey of 300+ of them from some coauthors and me (Räuker et al., 2022).
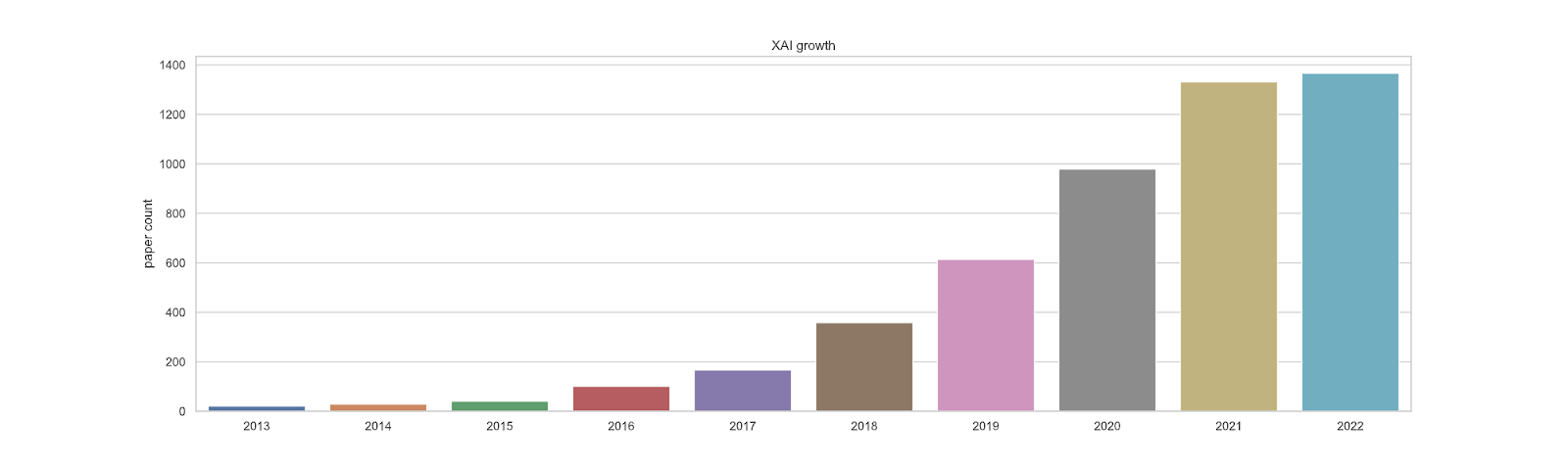
Growth in the interpretability literature by year from Jacovi (2023).
But despite all this work, interpretability research has limitations. One of the goals of this sequence is to argue that:
Interpretability research both within the AI safety space and at large is not very productive and may be on course to stay this way.
This is intentionally baitey, and I mean to make this point with a large amount of detail and nuance over the course of this sequence. But one striking thing about interpretability research is that:
For all the interpretability work that exists, there is a significant gap between this research and engineering applications.
This is not to say that purely exploratory work is not good and necessary. But the problem of AI safety is an engineering problem at its core. If one of our main goals for interpretability research is to help us with aligning highly intelligent AI systems in high stakes settings, shouldn’t we be seeing tools that are more helpful in the real world? Hence the name of this sequence: The Engineer’s Interpretability Sequence (EIS).
This sequence will start with foundations, engage with existing work, and build toward an agenda. There will be 12 parts.
- EIS I: Intro
- EIS II: What is “Interpretability”?
- EIS III Broad critiques of Interpretability Research
- EIS IV: A Spotlight on Feature Attribution/Saliency
- EIS V: Blind Spots In AI Safety Interpretability Research
- EIS VI: Critiques of Mechanistic Interpretability Work in AI Safety
- EIS VII: A Challenge for Mechanists
- EIS VIII: An Engineer’s Understanding of Deceptive Alignment
- EIS IX: Interpretability and Adversaries
- EIS X: Continual Learning, Modularity, Compression, and Biological Brains
- EIS XI: Moving Forward
- EIS XII: Summary
In the coming days, I plan to post a new installment every day or so. Thanks to my labmates, advisor, friends, and many others in the interpretability community for lots of good conversations and inspiration in the past year. Thanks to Rio Popper for feedback on this intro post. I'll be thanking others on a per-post basis later on. However, to be 100% clear, all opinions, hot takes, and mistakes are my own.
In the coming posts, I will discuss dozens of takes on a variety of topics. And I’ve done my best to make sure that those takes are good. But if and when some of them are not good, I hope that coming to understand why will be useful. I’ll look forward to corrections and alternative points of view in the comments. Feedback throughout will be welcome. Thanks!
Questions
- Is there anything in particular you would like to see discussed later in this sequence?
- How truly pre-paradigmatic do you think interpretability research is? Is it still time to explore concepts and techniques, or should we be focusing more on benchmarks and real-world applications?
- What things about interpretability research make you optimistic or pessimistic?
- Are you working on anything to make interpretability work more engineering-relevant?