This post is part 2 in our sequence on Modeling Transformative AI Risk. We are building a model to understand debates around existential risks from advanced AI. The model is made with Analytica software, and consists of nodes (representing key hypotheses and cruxes) and edges (representing the relationships between these cruxes), with final output corresponding to the likelihood of various potential failure scenarios. You can read more about the motivation for our project and how the model works in the Introduction post. Future posts will explain how different considerations, such as AI takeoff or mesa-optimization, are incorporated into the model.
This post explains our effort to incorporate basic assumptions and arguments by analogy about intelligence, which are used to ground debates about AI takeoff and paths to High-Level Machine Intelligence (HLMI[1]). In the overall model, this module, Analogies and General Priors on Intelligence, is one of the main starting points, and influences modules (covered in subsequent posts in this series) addressing the possibilities of a Discontinuity around HLMI or an Intelligence Explosion, as well as AI Progression and HLMI Takeoff Speed.
The Analogies and General Priors on Intelligence module addresses various claims about AI and the nature of intelligence:
- The difficulty of marginal intelligence improvements at the approximate ‘human level’ (i.e., around HLMI)
- Whether marginal intelligence improvements become increasingly difficult beyond HLMI at a rapidly growing rate or not
- ‘Rapidly growing rate’ is operationalized as becoming difficult exponentially or faster-than-exponentially
- Whether there is a fundamental upper limit to intelligence not significantly above the human level
- Whether, in general, further improvements in intelligence tend to be bottlenecked by previous improvements in intelligence rather than some external factor (such as the rate of physics-limited processes)
These final outputs are represented by these four terminal nodes at the bottom of the module.

These four claims depend on arguments that analogize the development of HLMI to other domains. Each of these arguments is given a specific submodule in our model, and each argument area is drawn from our review of the existing literature. In the ‘outputs’ section at the end of this article, we explain why we chose these four as cruxes for the overall debate around HLMI development.
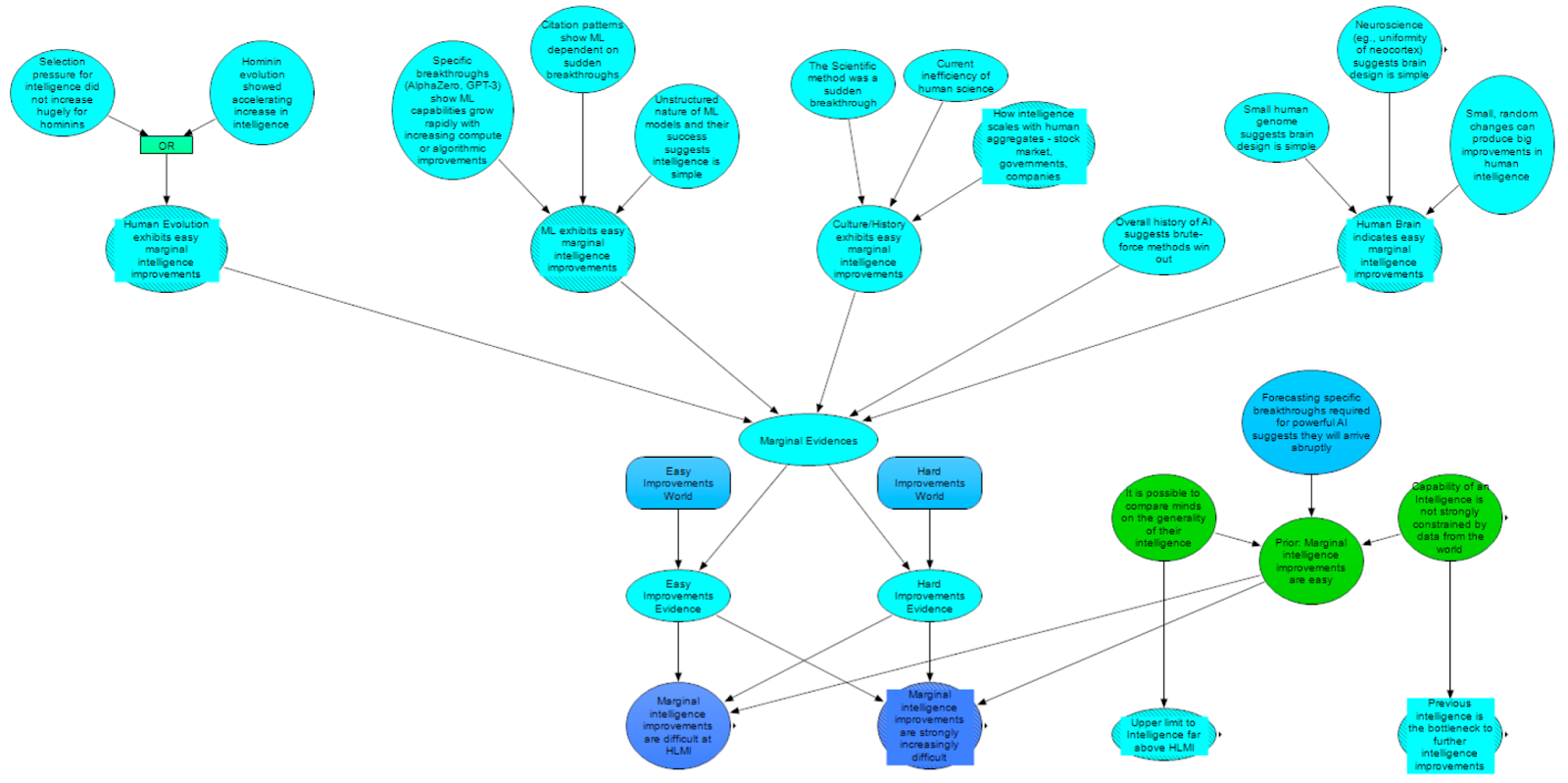
Each argument area is shown in the image below, a zoomed out view of the entire Analogies and General Priors on Intelligence module. The argument areas are: human biological evolution, machine learning, human cultural evolution, the overall history of AI, and the human brain. Each of these areas is an example of either the development of intelligence or of intelligence itself, and might be a useful analogy for HLMI.
We also incorporate broad philosophical claims about the nature of intelligence as informative in this module. These claims act as priors before the argument areas are investigated, and cover broad issues like whether the concept of general intelligence is coherent and whether the capabilities of agents are strongly constrained by things other than intelligence.
Module Overview
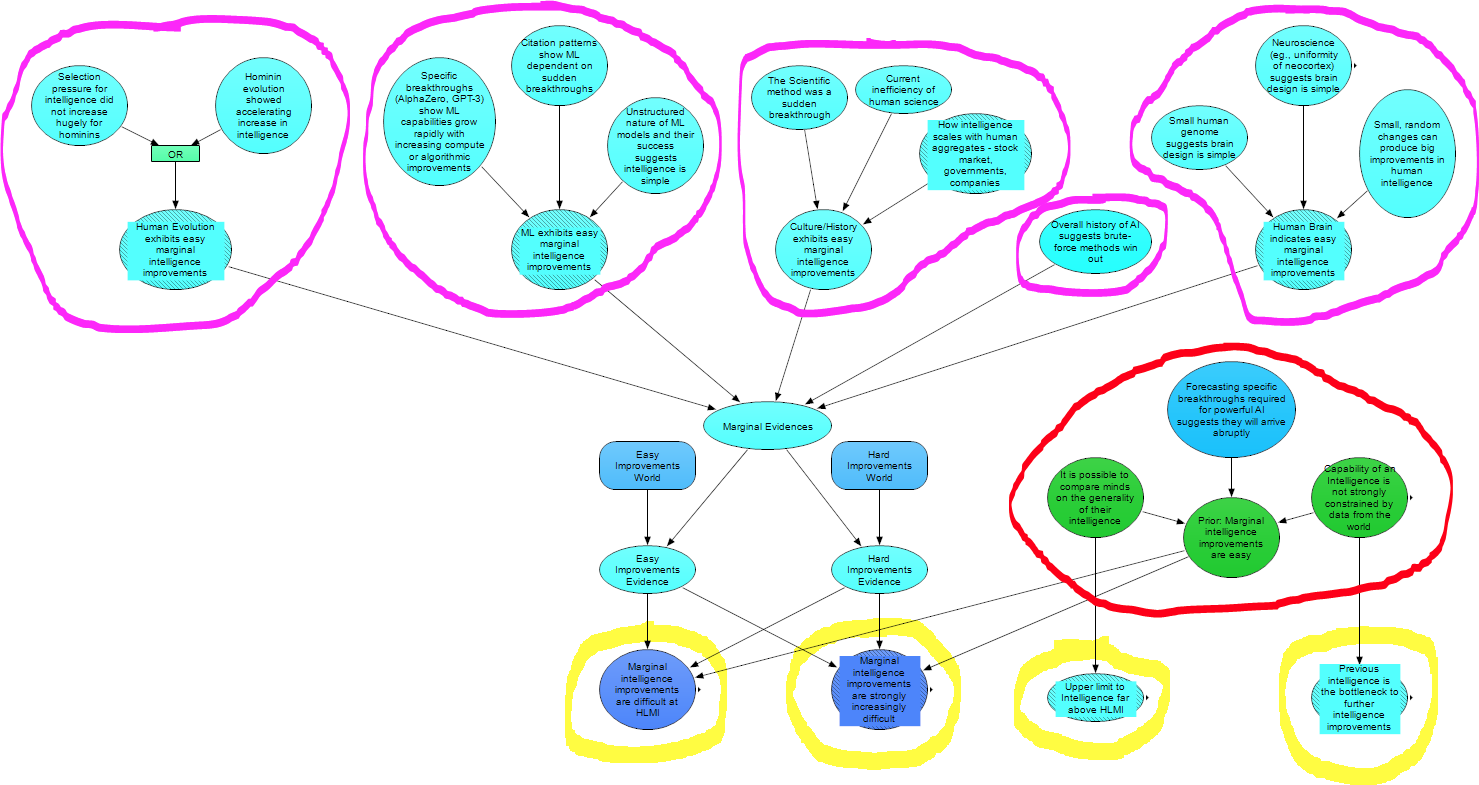
In this diagram of the overall module, the groups of nodes circled in purple are (left to right), Human Evolution, Machine Learning, Human Culture and History, History of AI and the Human Brain, which feed forward to a classifier that estimates the ease of marginal intelligence improvements. Red shows General Priors, and the yellow nodes are the final model outputs as discussed above. We discuss each of these sections in this order in the rest of this post.
The Cruxes
Each of the argument area submodules, as well as the General Priors submodule, contains cruxes (represented by nodes) that ultimately influence the terminal nodes in this module.
Human Evolution
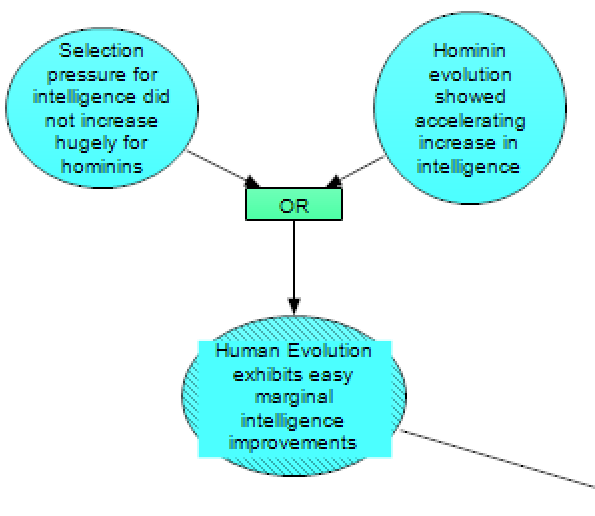
Human evolution is one of the areas most commonly analogised to HLMI development. ‘Intelligence Explosion Microeconomics’ argued that human evolution demonstrated accelerating returns on cognitive investment, which suggests marginal intelligence improvements were (at least) not rapidly increasingly difficult during this process.
There are two sources of potential evidence which could support these claims about evolution. The first (left-hand node in the module above) is if hominin evolution did not involve hugely more selection pressure for intelligence than did the evolution of other, ancestral primates. It is generally assumed that hominins (all species more closely related to Homo sapiens than to chimpanzees – e.g., all species from Australopithecus and Homo) saw much faster rises in intelligence than what had happened previously to primates. If this unprecedented rise in intelligence was not due to selection pressures for intelligence changing drastically, then that would provide evidence that this fast rise in intelligence did not involve evolution “solving” increasingly more difficult problems than what came before. On the other hand, if selection pressures for intelligence had been marginal (or less) up until this point and were suddenly turned way up, then the fast rise in intelligence could be squared with evolution solving more difficult problems (as the increase in intelligence could then be less than proportional to the increase in selection pressures for intelligence).
Even if selection pressures for intelligence were marginal before hominins, we could still obtain evidence that human evolution exhibited easy marginal intelligence improvements – if we observe a rapid acceleration of intelligence during hominin evolution, up to Homo sapiens (right-hand node in the module above). Such an acceleration of intelligence would be less likely if intelligence improvements became rapidly more difficult as the human level was approached.
We must note, however, that the relevance of these evolutionary considerations for artificial intelligence progress is still a matter of debate. Language, for instance, was evolved very late along the human lineage, while AI systems have been trained to deal with language from much earlier in their relative development. It is unknown how differences such as this would affect the difficulty-landscape of developing intelligence. The amount to update based on analogies to evolution, however, is not handled by this specific submodule, but instead by the classifier (mentioned above, described below in the section The Outputs).
Sources:
Likelihood of discontinuous progress around the development of AGI
Takeoff speeds – The sideways view
Hanson-Yudkowsky AI Foom Debate
Machine Learning
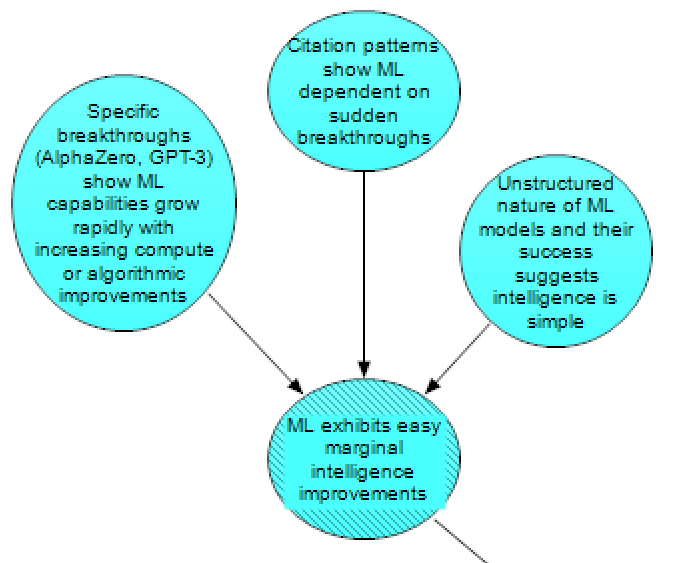
Much of the debate around HLMI has focused on what, if any, are the implications of current progress in machine learning for how easy improvements will be at the level of HLMI. Some see developments like AlphaGo or GPT-3 as examples of (and evidence for) the claim that marginal intelligence improvements are not increasingly difficult, though others disagree with those conclusions.
For the first of the ways that we could conclude that current ML exhibits easy marginal intelligence improvements, see this argument:
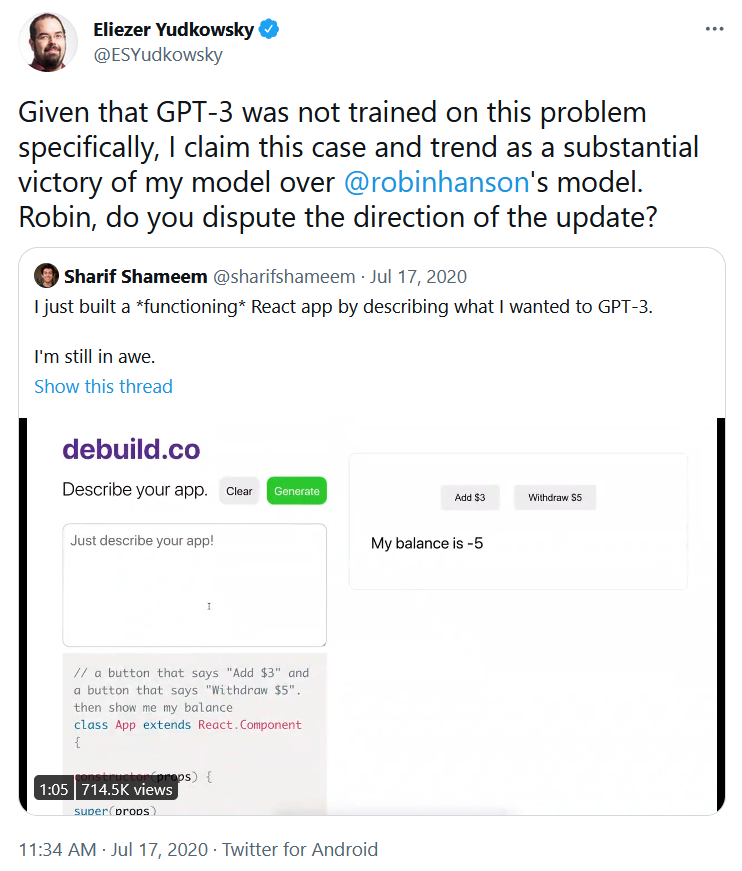
Which we understand to mean,
GPT-3 is general enough that it can write a functioning app given a short prompt, despite the fact that it is a relatively unstructured transformer model with no explicitly coded representations for app-writing. The fact that GPT-3 is this capable suggests that ML models scale in capability and generality very rapidly with increases in computing power or minor algorithm improvements...
In order to understand whether claims like Yudkowsky’s are true, we must understand the specific nature of the breakthroughs made by cutting-edge ML systems like GPT-3 or Alphazero and the limits of what these systems can do (left node in the image above).
Claims about current ML systems are related to a broader, more qualitative claim that the general success of ML models indicates that the fundamental algorithms needed for general intelligence are less complex than we might think (right node in the image above). Specific examples of ‘humanlike’ thinking or reasoning in neural networks, for example OpenAI’s discovery of Multimodal Neurons, lend some support to this claim.
Alternatively, Robin Hanson claims that if machine learning was developing in sudden leaps, we would expect to see a pattern of citations in ML research where a few breakthrough papers received a very disproportionately large amount of citations. If Hanson is right about this, and in reality citations aren’t distributed in an unusually concentrated pattern in ML compared to other fields, then we have reason to expect marginal intelligence improvements from ML are hard (middle node in the image above).
Sources:
Hanson-Yudkowsky AI Foom Debate
Searching for Bayes-Structure - LessWrong 2.0 viewer
Will AI undergo discontinuous progress?
Conceptual issues in AI safety: the paradigmatic gap
The Scaling Hypothesis · Gwern.net
Eliezer Yudkowsky on AlphaGo's Wins
GPT-2 As Step Toward General Intelligence
GPT-3, Bloviator: OpenAI’s language generator has no idea what it’s talking about
Human Culture and History
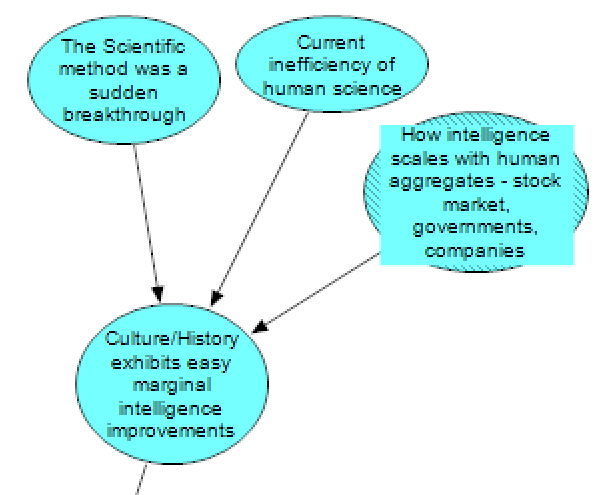
Another source of evidence is human history and cultural evolution. During the Hanson-Yudkowsky debate, Eliezer Yudkowsky argued that the scientific method is an organisational and methodological insight that suddenly allowed humans to have much greater control over nature, and that this is evidence that marginal intelligence improvements are easy and that AI systems will similarly have breakthroughs where their capabilities suddenly increase (left-hand node).
In “Intelligence Explosion Microeconomics”, Eliezer Yudkowsky also identified specific limitations of human science that wouldn’t limit AI systems (middle node). For example, human researchers need to communicate using slow and imprecise human language. Wei Dai has similarly argued that AI systems have greater economies of scale than human organizations because they do not hit a Coasean ceiling. We might expect that a lot of human intelligence is ‘wasted’, as organisations containing humans are not proportionately more intelligent than their members, due to communication limits that won’t exist in HLMI (right-hand node). If these claims are right, simple organisational insights radically improved humanity’s practical abilities, but we still face many organisational limitations an AI would not have to deal with. This suggests marginal improvements in practical abilities could be easy for an AI. On the other hand, even early, relatively unintelligent AIs don’t face human limitations such as the inefficiency of interpersonal communication. This means AI might have already “baked in” whatever gains can be achieved from methodological improvements before reaching HLMI.
Sources:
Hanson-Yudkowsky AI Foom Debate (search “you look at human civilization and there's this core trick called science”)
Debating Yudkowsky (point 5 responds to Eliezer)
(above links from Science argument)
Intelligence Explosion Microeconomics (3.5)
Continuing the takeoffs debate - LessWrong 2.0 viewer
History of AI

This section covers reference-class forecasting based on the history of AI, going back before the current machine learning paradigm. Principally, the ‘bitter lesson’ (2019):
The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin... Seeking an improvement that makes a difference in the shorter term, researchers seek to leverage their human knowledge of the domain, but the only thing that matters in the long run is the leveraging of computation.
The bitter lesson is much broader than machine learning and also includes, for example, the success of deep (relatively brute-force) search methods in computer chess. If the bitter lesson is true in general, it would suggest that we can get significant capability gains from scaling up models. That in turn should lead us to update towards marginal intelligence improvements being easier. The conjecture is that we can continually scale up compute and data to get smooth improvements in search and learning. If this is true, then plausibly scaling up compute and data will also produce smooth increases in general intelligence.
Sources:
The Human Brain
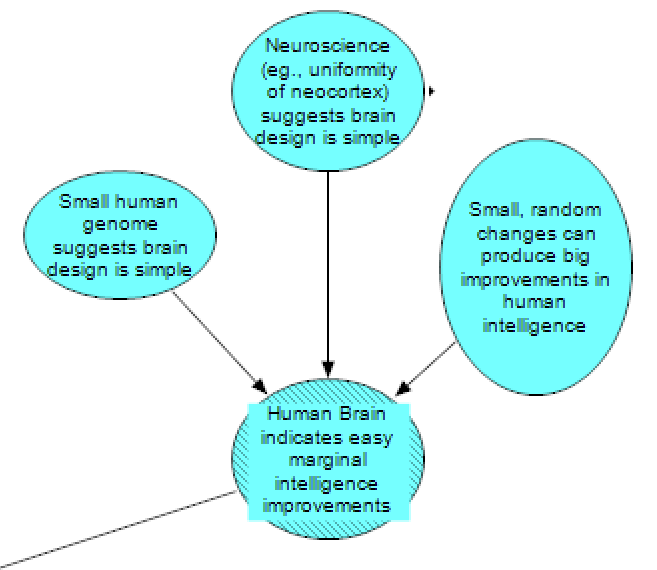
Biological details of the human brain provide another source of intuitions about the difficulty of marginal improvements in intelligence. Eliezer Yudkowsky has argued that (search for “750 megabytes of DNA” on that page) the small size of the human genome suggests that brain design is simple (this is similar to the Genome Anchor hypothesis in Ajeya Cotra’s AI timelines report, where the number of parameters in the machine learning model is anchored to the number of bytes in the human genome) (left-hand node).
If the human neocortex is uniform in architecture, or if cortical neuron count strongly predicts general intelligence, this also suggests there is a simple “basic algorithm” for intelligence (possibly analogous to a common algorithm already used in ML). The fact that the neocortex can be divided into different brain regions with different functions, and that the locations of these different regions are conserved across individuals, is evidence against such a simple, uniform algorithm, but on the other hand, the ability of neurons in certain regions to be recruited by other regions (e.g., in ferrets that have had retinal projections redirected to the auditory thalamus, or in blind humans that can learn to echolocate via mouth clicks and apparently using brain regions typically devoted to vision) is an argument in favour. If the human brain employs a simple algorithm, then we should think it more likely that there are other algorithms that can be rapidly scaled to produce highly intelligent behaviour. These all fall under the evidence from neuroscience node (middle node).
Variation in scientific and other intellectual ability among humans (compare Von Neumann to an average human) who share the same basic brain design also suggests improvements are easy at the HLMI level. Similarly, the fact that mood or certain drugs (stimulants and psychedelics) can sometimes improve human cognitive performance implies that humans aren’t at a relative maximum, as if we were, simple blunt changes to our cognition should almost always degrade performance (and rare reports of people gaining cognitive abilities after brain damage provide a potentially even more extreme version of this argument). All of these provide evidence for the claim that small, random changes can produce big improvements in human intelligence (right-hand node).
Sources:
Source code size vs learned model size in ML and in humans?
(the above links are from Missing gear for intelligence and Secret sauce for intelligence)
Neurons And Intelligence: A Birdbrained Perspective
Jeff Hawkins on neuromorphic AGI within 20 years
General Priors
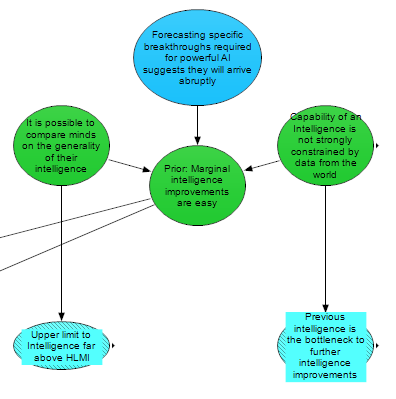
One’s beliefs about the possibility of an intelligence explosion are likely influenced to a large degree by general priors about the nature of intelligence: whether “general intelligence” is a coherent concept, whether nonhuman animal species can be compared by level of general intelligence, and so on. Claims like "intelligence isn't one thing that can just be scaled up or down – it consists of a bunch of different modules that are put together in the right way", imply that it is not useful to compare minds on the basis of general intelligence. For instance, François Chollet denies the possibility of an intelligence explosion in part based on these considerations. As well as affecting the difficulty of marginal intelligence improvements, general priors (including the possibilities that previous intelligence is a bottleneck to future improvements and that there exists an upper limit to intelligence) also matter because they are potential defeaters of a fast progress/intelligence explosion scenario.
Sources:
The implausibility of intelligence explosion
A reply to Francois Chollet on intelligence explosion
The Outputs

The empirical cruxes mentioned above influence the outputs of this module, which further influence downstream nodes in other modules. The cruxes this module outputs are: Marginal Intelligence Improvements are difficult at HLMI, Marginal Intelligence Improvements are Strongly Increasingly Difficult, the Upper Limit to Intelligence is far above HLMI, and Previous intelligence is a bottleneck to future intelligence improvements. These cruxes influence probabilities the model places on different paths to HLMI and takeoff scenarios.
For the two Difficulty of Marginal Intelligence Improvements nodes, we implement a naive bayes classifier in the Analytica model (i.e., a probabilistic classifier that applies Bayes' theorem with strong independence assumptions between the features). Each claim about one of the domains analogous to HLMI (e.g., in the domain of the human brain, the claim that the neocortex is uniform) is more likely to be true in a world where marginal intelligence improvements in general are either easy or hard. Therefore, when taken together, the analogy areas provide evidence about the difficulty of marginal intelligence improvements for HLMI.
This use of a naive Bayes classifier enables us to separate out the prior likelihoods of the original propositions, for example that the human neocortex is uniform, and these propositions’ relevance to HLMI (likelihood of being true in a world with easy vs hard marginal intelligence improvements).
This extra step of using Bayes classification is useful because the claims about the analogy domains themselves are often much more certain than their degree of relevance to claims about the ease of improvements to HLMI. Whether there was a rapid acceleration in intelligence during hominin evolution is something that can be assessed by domain experts or a review of the relevant literature, but the relevance of this claim to HLMI is a separate question we are much less certain about. Using the naive Bayes classifier allows us to separate these two factors out.
Difficulty of Marginal Intelligence Improvements
How difficult marginal intelligence improvements are at HLMI and how rapidly they become more difficult at higher levels of intelligence are some of the most significant cruxes of disagreement among those trying to predict the future of AI. If marginal intelligence improvements are difficult around HLMI, then HLMI is unlikely to arrive in a sudden burst. If marginal intelligence improvements rapidly become increasingly difficult beyond HLMI, it is unlikely there will be an intelligence explosion post-HLMI.
For an example from Yudkowsky of discussion relating to whether marginal intelligence improvements are ‘strongly increasingly difficult’:
The Open Problem posed here is the quantitative issue: whether it’s possible to get sustained returns on reinvesting cognitive improvements into further improving cognition
(‘Strongly increasingly difficult’ has often been operationalized as ‘exponentially increasingly difficult’, as in that way it serves as a defeater for the ‘sustained returns’ that we might expect from powerful AI accelerating the development of AI)
Paul Christiano has also claimed models of progress which include “key insights [that]… fall into place” are implausible, which we model as a claim that marginal intelligence improvements at HLMI are difficult (since if they are difficult, a few key insights will not be enough). For a direct example of a claim that difficulty of marginal intelligence improvements is a key crux, see this quote by Robin Hanson:
So I suspect this all comes down to, how powerful is architecture in AI, and how many architectural insights can be found how quickly? If there were say a series of twenty deep powerful insights, each of which made a system twice as effective, just enough extra oomph to let the project and system find the next insight, it would add up to a factor of a million. Which would still be nowhere near enough, so imagine a lot more of them, or lots more powerful.
In our research, we have found that what is most important in many models of AI takeoff is their stance on whether marginal intelligence improvements are difficult at HLMI and if they become much more difficult beyond HLMI. Some models, for instance, claim there is a ‘secret sauce’ for intelligence such that once it is discovered, progress becomes easy. In the Discontinuities and Takeoff Speeds section of the model (presented in a subsequent post in this series), we more closely examine the relationships between claims about ease of marginal intelligence improvements and progress around HLMI.
Why did we attempt to identify an underlying key crux in this way? It is clear that beliefs about AI takeoff relate to beliefs from arguments by analogy (in this post) in fundamental ways, for example:
Paul Christiano et al.: Human Evolution is not an example of massive capability gain given constant optimization for intelligence + (other factors) ➔ [Implicit Belief A about nature of AI Progress] ➔ Continuous Change model of Intelligence Explosion, likely not highly localized
Eliezer Yudkowsky et al.: Human Evolution is an example of massive capability gain given constant optimization for intelligence + (other factors) ➔ [Implicit Belief B about nature of AI Progress] ➔ Discontinuous Change model of Intelligence Explosion, likely highly localized
We have treated implicit beliefs A and B as being about the difficulty of marginal intelligence improvements at HLMI and beyond.
We have identified ‘Previous intelligence is a bottleneck’ and ‘There is an upper limit to intelligence’ as two other important cruxes. They are commonly cited as defeaters for scenarios that involve any kind of explosive growth due to an acceleration in AI progress. Both of these appear to be cruxes between sceptics and non-sceptics of HLMI and AI takeoff.
Previous Intelligence is a bottleneck
The third major output of this module is whether, in general, further improvements in intelligence tend to be bottlenecked by the current intelligence of our systems rather than some external factor (such as the need to run experiments and wait for real-world data).
This output is later used in the intelligence explosion module (covered in a subsequent post in this series): if such an external bottleneck exists, we are unlikely to see rapid acceleration of technological progress through powerful AI improving our ability to build yet more powerful AI. There will instead be drag factors preventing successor AIs from being produced without reference to the outside world. This view is summarised by Francois Chollet:
If intelligence is fundamentally linked to specific sensorimotor modalities, a specific environment, a specific upbringing, and a specific problem to solve, then you cannot hope to arbitrarily increase the intelligence of an agent merely by tuning its brain — no more than you can increase the throughput of a factory line by speeding up the conveyor belt. Intelligence expansion can only come from a co-evolution of the mind, its sensorimotor modalities, and its environment.
In short, this position claims that positive feedback loops between successive generations of HLMI could not simply be closed, but instead would require feedback from environmental interaction that can’t be arbitrarily sped up. While Chollet appears to be assuming such bottlenecks will occur due to necessary interactions with the physical world, it is possible in principle that such bottlenecks could occur in the digital world – for instance, brain emulations that were sped up by 1Mx would find all computers (and thus communications, access to information, calculators, simulations, etc) slowed down by 1Mx (from their perspective), potentially creating a drag on progress.
A somewhat more tentative version of this claim is that improvements in intelligence (construed here as ‘ability to do applied science’) require a very diverse range of discrete skills and access to real-world resources. Ben Garfinkel makes this point:
...there’s really a lot of different tasks that feed into making progress in engineering or areas of applied science. There’s not really just this one task of “Do science”. Let’s take, for example, the production of computing hardware… I assume that there’s a huge amount of different works in terms of how you’re designing these factories or building them, how you’re making decisions about the design of the chips. Lots of things about where you’re getting your resources from. Actually physically building the factories.
Upper Limit to Intelligence
Finally, this module has an output for whether there is a practical upper limit to intelligence not significantly above the human level. This could be true if there are physical barriers to the development of greater intelligence. Alternatively, it seems more likely to be effectively true if we cannot even compare the abilities of different minds along a general metric of “intelligence” (hence a “no” answer to “it is possible to compare minds on the generality of their intelligence” leads to a “yes” to this crux). For the “not possible to compare minds on the generality of their intelligence” claim, from François Chollet:
The first issue I see with the intelligence explosion theory is a failure to recognize that intelligence is necessarily part of a broader system — a vision of intelligence as a “brain in jar” that can be made arbitrarily intelligent independently of its situation.
Chollet argues that human (and all animal) intelligence is ‘hyper-specialised’ and situational to a degree that makes comparisons of general intelligence much less useful than they first appear,
If intelligence is a problem-solving algorithm, then it can only be understood with respect to a specific problem. In a more concrete way, we can observe this empirically in that all intelligent systems we know are highly specialized ... The brain has hardcoded conceptions of having a body with hands that can grab, a mouth that can suck, eyes mounted on a moving head that can be used to visually follow objects (the vestibulo-ocular reflex), and these preconceptions are required for human intelligence to start taking control of the human body. It has even been convincingly argued, for instance by Chomsky, that very high-level human cognitive features, such as our ability to develop language, are innate.
A strong version of the modularity of mind hypothesis, ‘massive modularity’, also implies that intelligence is hyper-specialised at extremely specific tasks. If true, massive modularity would lend support to the claim that ‘intelligence… can only be understood with respect to a specific problem’, which in turn suggests that intelligence cannot be increased independent of its situation.
Conclusion
This post has explained the structure and reasoning behind one of the starting points of the MTAIR model - Analogies and General Priors. This module connects conclusions about the nature of HLMI to very basic assumptions about the nature of intelligence, and analogies to domains other than HLMI about which we have greater experience.
We have made the simplifying assumption to group the conclusions drawn from the general priors and the different analogy domains into four outputs, which we think characterise the important variables needed to predict HLMI development and post-HLMI takeoff. In later posts, we will explain how those outputs are used to make predictions about HLMI takeoff and development.
The next post in the series will be Paths to High-Level Machine Intelligence, which attempts to forecast when HLMI will be developed and by what route.
We are interested in any feedback you might have, particularly if there are any views or arguments which you feel our model does not currently capture, or captures incorrectly.
Footnotes
- We define HLMI as machines that are capable of performing almost all economically-relevant information-processing tasks (either individually or collectively). We are using the term “high-level machine intelligence” here instead of the related terms “human-level machine intelligence”, “artificial general intelligence”, or “transformative AI”, since these other terms are often seen as baking in assumptions about either the nature of intelligence or advanced AI that are not universally accepted.