Finite Factored Sets
22paulfchristiano
5cousin_it
10paulfchristiano
5Scott Garrabrant
4cousin_it
3Scott Garrabrant
4cousin_it
5Scott Garrabrant
2cousin_it
3Scott Garrabrant
1cousin_it
2Scott Garrabrant
2Scott Garrabrant
2Scott Garrabrant
1cousin_it
2Scott Garrabrant
1[comment deleted]
4Scott Garrabrant
11Scott Garrabrant
4paulfchristiano
5Scott Garrabrant
2paulfchristiano
3Koen.Holtman
13Scott Garrabrant
10Rohin Shah
4alkjash
5Scott Garrabrant
3habryka
2Scott Garrabrant
3michaelcohen
3Scott Garrabrant
3ESRogs
4Scott Garrabrant
2drocta
5Scott Garrabrant
2Koen.Holtman
2michaelcohen
3Scott Garrabrant
2cousin_it
4Scott Garrabrant
3Scott Garrabrant
3cousin_it
3Scott Garrabrant
7cousin_it
3Scott Garrabrant
2cousin_it
6Scott Garrabrant
2Scott Garrabrant
3[comment deleted]
2Scott Garrabrant
0acgt
3Scott Garrabrant
1acgt
3Scott Garrabrant
1Vivek Hebbar
2Ramana Kumar
2Vivek Hebbar
1lemonhope
3Scott Garrabrant
1lemonhope
2Scott Garrabrant
1Ben Pace
1FjolleJagt
3Scott Garrabrant
1FjolleJagt
3Scott Garrabrant
1passinglunatic
5Scott Garrabrant
1michaelcohen
6Scott Garrabrant
1SarahNibs
4Scott Garrabrant
New Comment
Here is how I'm currently thinking about this framework and especially inference, in case it's helpful for other folks who have similar priors to mine (or in case something is still wrong).
A description of traditional causal models:
- A causal graph with N nodes can be viewed as a model with 2N variables, one for each node of the graph and a corresponding noise variable for each. Each real variable is a deterministic function of its corresponding noise variable + its parents in the causal graph.
- When we talk about causal inference, we often consider probabilities in "generic position": we ask what kind of graphs would give rise to the observed conditional independence relations (and no others) regardless of the probability distributions and functions.
In the factored sets framework:
- We still posit a bunch of independent noise variables, and our observations are still a deterministic functions of these noise variables.
- But we no longer make any structural assumption about an underlying graph---the deterministic functions can be arbitrary.
- It's easy to prove that for any deterministic function there is a unique "smallest" set of variables on which it potentially depends. We call this the his
I think the definition of history is the most natural way to recover something like causal structure in these models.
I'm not sure how much it's about causality. Imagine there's a bunch of envelopes with numbers inside, and one of the following happens:
-
Alice peeks at three envelopes. Bob peeks at ten, which include Alice's three.
-
Alice peeks at three envelopes and tells the results to Bob, who then peeks at seven more.
-
Bob peeks at ten envelopes, then tells Alice the contents of three of them.
Under the FFS definition, Alice's knowledge in each case is "strictly before" Bob's. So it seems less of a causal relationship and more like "depends on fewer basic facts".
Agree it's not totally right to call this a causal relationship.
That said:
- The contents of 3 envelopes does seems causally upstream of the contents of 10 envelopes
- If Alice's perception is imperfect (in any possible world), then "what Alice perceived" is not identical to "the contents of 3 envelopes" and so is not strictly before "what Bob perceived" (unless there is some other relationship between them).
- If Alice's perception is perfect in every possible world, then there is no possible way to intervene on Alice's perception without intervening on the contents of the 3 envelopes. So it seems like a lot rests on whether you are restricting your attention to possible worlds.
- Even if Alice's perception is perfect (or if Bob is guaranteed to tell Alice the contents of the 3 envelopes) we can still imagine an intervention on Alice's perception, and in your stories it seems like that's what makes it feel like Alice's perception isn't upstream of Bob's perception. But it feels to me like this imagination ought to track subjective possibility, even if in fact it is probably logically necessary that Alice perceives correctly / Bob reports correctly / whatever.
So I do feel like there's a case t...
I think I (at least locally) endorse this view, and I think it is also a good pointer to what seems to me to be the largest crux between the my theory of time and Pearl's theory of time.
4
I feel that interpreting "strictly before" as causality is making me more confused.
For example, here's a scenario with a randomly changed message. Bob peeks at ten regular envelopes and a special envelope that gives him a random boolean. Then Bob tells Alice the contents of either the first three envelopes or the second three, depending on the boolean. Now Alice's knowledge depends on six out of ten regular envelopes and the special one, so it's still "strictly before" Bob's knowledge. And since Alice's knowledge can be computed from Bob's knowledge but not vice versa, in FFS terms that means the "cause" can be (and in fact is) computed from the "effect", but not vice versa. My causal intuition is just blinking at all this.
Here's another scenario. Alice gets three regular envelopes and accurately reports their contents to Bob, and a special envelope that she keeps to herself. Then Bob peeks at seven more envelopes. Now Alice's knowledge isn't "before" Bob's, but if later Alice predictably forgets the contents of her special envelope, her knowledge becomes "before" Bob's. Even though the special envelope had no effect on the information Alice gave to Bob, didn't affect the causal arrow in any possible world. And if we insist that FFS=causality, then by forgetting the envelope, Alice travels back in time to become the cause of Bob's knowledge in the past. That's pretty exotic.
3
I partially agree, which is partially why I am saying time rather than causality.
I still feel like there is an ontological disagreement in that it feels like you are objecting to saying the physical thing that is Alice's knowledge is (not) before the physical thing that is Bob's knowledge.
In my ontology:
1) the information content of Alice's knowledge is before the information content of Bob's knowledge. (I am curios if this part is controversial.)
and then,
2) there is in some sense no more to say about the physical thing that is e.g. Alice's knowledge beyond the information content.
So, I am not just saying Alice is before Bob, I am also saying e.g. Alice is before Alice+Bob, and I can't disentangle these statements because Alice+Bob=Bob.
I am not sure what to say about the second example. I am somewhat rejecting the dynamics. "Alice travels back in time" is another way of saying that the high level FFS time disagrees with the standard physical time, which is true. The "high level" here is pointing to the fact that we are only looking at the part of Alice's brain that is about the envelopes, and thus talking about coarser variables than e.g. Alice's entire brain state in physical time. And if we are in the ontology where we are only looking at the information content, taking a high level version of a variable is the kind of thing that can change its temporal properties, since you get an entirely new variable.
I suspect most of the disagreement is in the sort of "variable nonrealism" of reducing the physical thing that is Alice's knowledge to its information content?
4
Not sure we disagree, maybe I'm just confused. In the post you show that if X is orthogonal to X XOR Y, then X is before Y, so you can "infer a temporal relationship" that Pearl can't. I'm trying to understand the meaning of the thing you're inferring - "X is before Y". In my example above, Bob tells Alice a lossy function of his knowledge, and Alice ends up with knowledge that is "before" Bob's. So in this case the "before" relationship doesn't agree with time, causality, or what can be computed from what. But then what conclusions can a scientist make from an inferred "before" relationship?
5
I don't have a great answer, which isn't a great sign.
I think the scientist can infer things like. "algorithms reasoning about the situation are more likely to know X but not Y than they are to know Y but not X, because reasonable processes for learning Y tend to learn learn enough information to determine X, but then forget some of that information." But why should I think of that as time?
I think the scientist can infer things like "If I were able to factor the world into variables, and draw a DAG (without determinism) that is consistent with the distribution with no spurious independencies (including in deterministic functions of the variables), and X and Y happen to be variables in that DAG, then there will be a path from X to Y."
The scientist can infer that if Z is orthogonal to Y, then Z is also orthogonal to X, where this is important because Z is orthogonal to Y can be thought of as saying that Z is useless for learning about Y. (and importantly a version of useless for learning that is closed under common refinement, so if you collect a bunch of different Z orthogonal to Y, you can safely combine them, and the combination will be orthogonal to Y.)
This doesn't seem to get at why we want to call it before. Hmm.
Maybe I should just list a bunch of reasons why it feels like time to me (in no particular order):
1. It seems like it gets a very reasonable answer in the Game of Life example
2. Prior to this theory, I thought that it made sense to think of time as a closure property on orthogonality, and this definition of time is exactly that closure property on orthogonality, where X is weakly before Y if whenever Z is orthogonal to Y, Z is also orthogonal to X. (where the definition of orthogonality is justified with the fundamental theorem.)
3. If Y is a refinement of X, then Y cannot be strictly before X. (I notice that I don't have a thing to say about why this feels like time to me, and indeed it feels like it is in direct opposition to your "does
2
Thanks for the response! Part of my confusion went away, but some still remains.
In the game of life example, couldn't there be another factorization where a later step is "before" an earlier one? (Because the game is non-reversible and later steps contain less and less information.) And if we replace it with a reversible game, don't we run into the problem that the final state is just as good a factorization as the initial?
3
Yep, there is an obnoxious number of factorizations of a large game of life computation, and they all give different definitions of "before."
1
I think your argument about entropy might have the same problem. Since classical physics is reversible, if we build something like a heat engine in your model, all randomness will be already contained in the initial state. Total "entropy" will stay constant, instead of growing as it's supposed to, and the final state will be just as good a factorization as the initial. Usually in physics you get time (and I suspect also causality) by pointing to a low probability macrostate and saying "this is the start", but your model doesn't talk about macrostates yet, so I'm not sure how much it can capture time or causality.
That said, I like really like how your model talks only about information, without postulating any magical arrows. Maybe it has a natural way to recover macrostates, and from them, time?
2
Wait, I misunderstood, I was just thinking about the game of life combinatorially, and I think you were thinking about temporal inference from statistics. The reversible cellular automaton story is a lot nicer than you'd think.
if you take a general reversible cellular automaton (critters for concreteness), and have a distribution over computations in general position in which initial conditions cells are independent, the cells may not be independent at future time steps.
If all of the initial probabilities are 1/2, you will stay in the uniform distribution, but if the probabilities are in general position, things will change, and time 0 will be special because of the independence between cells.
There will be other events at later times that will be independent, but those later time events will just represent "what was the state at time 0."
For a concrete example consider the reversible cellular automaton that just has 2 cells, X and Y, and each time step it keeps X constant and replaces Y with X xor Y.
2
I think my model has macro states. In game of life, if you take the entire grid at time t, that will have full history regardless of t. It is only when you look at the macro states (individual cells) that my time increases with game of life time.
2
As for entropy, here is a cute observation (with unclear connection to my framework): whenever you take two independent coin flips (with probabilities not 0,1, or 1/2), their xor will always be high entropy than either of the individual coin flips.
1
Wait, can you describe the temporal inference in more detail? Maybe that's where I'm confused. I'm imagining something like this:
1. Check which variables look uncorrelated
2. Assume they are orthogonal
3. From that orthogonality database, prove "before" relationships
Which runs into the problem that if you let a thermodynamical system run for a long time, it becomes a "soup" where nothing is obviously correlated to anything else. Basically the final state would say "hey, I contain a whole lot of orthogonal variables!" and that would stop you from proving any reasonable "before" relationships. What am I missing?
2
I think that you are pointing out that you might get a bunch of false positives in your step 1 after you let a thermodynamical system run for a long time, but they are are only approximate false positives.
1[comment deleted]
4
Thanks Paul, this seems really helpful.
As for the name I feel like "FFS" is a good name for the analog of "DAG", which also doesn't communicate that much of the intuition, but maybe doesn't make as much sense for name of the framework.
4
I think FFS makes sense as an analog of DAG, and it seems reasonable to think of the normal model as DAG time and this model as FFS time. I think the name made me a bit confused by calling attention to one particular diff between this model and Pearl (factored sets vs variables), whereas I actually feel like that diff was basically a red herring and it would have been fastest to understand if the presentation had gone in the opposite direction by demphasizing that diff (e.g. by presenting the framework with variables instead of factors).
That said, even the DAG/FFS analogy still feels a bit off to me (with the caveat that I may still not have a clear picture / don't have great aesthetic intuitions about the domain).
Factorization seems analogous to describing a world as a set of variables (and to the extent it's not analogous it seems like an aesthetic difference about whether to take the world or variables as fundamental, rather than a substantive difference in the formalism) rather than to the DAG that relates the variables.
The structural changes seem more like (i) replacing a DAG with a bipartite graph, (ii) allowing arrows to be deterministic (I don't know how typically this is done in causal models). And then those structural changes lead to generalizing the usual concepts about causality so that they remain meaningful in this setting.
All that said, I'm terrible at both naming things and presenting ideas, and so don't want to make much of a bid for changes in either department.
Makes sense. I think a bit of my naming and presentation was biased by being so surprised by the not on OEIS fact.
I think I disagree about the bipartite graph thing. I think it only feels more natural when comparing to Pearl. The talk frames everything in comparison to Pearl, but I think if you are not looking at Pearl, I think graphs don’t feel like the right representation here. Comparing to Pearl is obviously super important, and maybe the first introduction should just be about the path from Pearl to FFS, but once we are working within the FFS ontology, graphs feel not useful. One crux might be about how I am excited for directions that are not temporal inference from statistical data.
My guess is that if I were putting a lot of work into a very long introduction for e.g. the structure learning community, I might start the way you are emphasizing, but then eventually convert to throwing all the graphs away.
(The paper draft I have basically only ever mentions Pearl/graphs for motivation at the beginning and in the applications section.)
2
I agree that bipartite graphs are only a natural way of thinking about it if you are starting from Pearl. I'm not sure anything in the framework is really properly analogous to the DAG in a causal model.
3
My thoughts on naming this finite factored sets: I agree with Paul's observation that
| Factorization seems analogous to describing a world as a set of variables
By calling this 'finite factored sets', you are emphasizing the process of coming up with individual random variables, the variables that end up being the (names of the) nodes in a causal graph. With s∈S representing the entire observable 4D history of a world (like a computation starting from a single game of life board state), a factorisation B={b1,b2,⋯bn} splits such s into a tuple of separate, more basic observables (bb1,bb2,⋯,bbn). where bb1∈b1, etc. In the normal narrative that explains Pearl causal graphs, this splitting of the world into smaller observables is not emphasized. Also, the splitting does not necessarily need to be a bijection. It may loose descriptive information with respect to s.
So I see the naming finite factored sets as a way to draw attention to this splitting step, it draws attention to the fact that if you split things differently, you may end up with very different causal graphs. This leaves open the question of course is if really want to name your framework in a way that draws attention to this part of the process. Definitely you spend a lot of time on creating an equivalent to the arrows between the nodes too.
Planned summary for the Alignment Newsletter. I'd be particularly keen for someone to check that I didn't screw up in the section "Orthogonality in Finite Factored Sets":
...This newsletter is a combined summary + opinion for the [Finite Factored Sets sequence](https://www.alignmentforum.org/s/kxs3eeEti9ouwWFzr) by Scott Garrabrant. I (Rohin) have taken a lot more liberty than I usually do with the interpretation of the results; Scott may or may not agree with these interpretations.
## Motivation
One view on the importance of deep learning is that it allows you to automatically _learn_ the features that are relevant for some task of interest. Instead of having to handcraft features using domain knowledge, we simply point a neural net at an appropriate dataset, and it figures out the right features. Arguably this is the _majority_ of what makes up intelligent cognition; in humans it seems very analogous to [System 1](https://en.wikipedia.org/wiki/Thinking,_Fast_and_Slow), which we use for most decisions and actions. We are also able to infer causal relations between the resulting features.
Unfortunately, [existing models](https://en.wikipedia.org/wiki/The_Book_of_Why) of causal inference d
Are there any interesting pure combinatorics problems about finite factored sets that you're interested in?
5
1. Given a finite set Ω of cardinality n, find a computable upper bound on the largest finite factored set model that is combinatorially different from all smaller finite factored set models. (We say that two FFS models are combinatorially different if they say the same thing about the emptiness of all boolean combinations of histories and conditional histories of partitions of Ω.) (Such an upper bound must exist because there are only finitely many combinatorially distinct FFS models, but a computable upper bound, would tell us that temporal inference is computable.)
2. Prove the fundamental theorem for finite dimensional factored sets. (Seems likely combinatorial-ish, but I am not sure.)
3. Figure out how to write a program to do efficient temporal inference on small examples. (I suspect this requires a bunch of combinatorial insights. By default this is very intractable, but we might be able to use math to make it easier.)
4. Axiomatize complete consistent orthogonality databases (consistent means consistent with some model, complete means has an opinion on every possible conditional orthogonality) (To start, is it the case that compositional semigraphoid axioms already work?)
If by "pure" you mean "not related to history/orthogonality/time," then no, the structure is simple, and I don't have much to ask about it.
I've thought a good amount about Finite Factored Sets in the past year or two, but I do sure keep going back to thinking about the world primarily in the form of Pearlian causal influence diagrams, and I am not really sure why.
I do think this one line by Scott at the top gave me at least one pointer towards what was happening:
but I'm trained as a combinatorialist, so I'm giving a combinatorics talk upfront.
In the space of mathematical affinities, combinatorics is among the branches of math I feel most averse to, and I think that explains a good...
2
This underrated post is pretty good at explaining how to translate between FFSs and DAGs.
I was thinking of some terminology that might make it easier to thinking about factoring and histories and whatnot.
A partition can be thought of as a (multiple-choice) question. Like for a set of words, you could have the partition corresponding to the question "Which letter does the word start with?" and then the partition groups together elements with the same answer.
Then a factoring is set of questions, where the set of answers will uniquely identify an element. The word that comes to mind for me is "signature", where an element's signature is the set o...
3
Yep, this all seems like a good way of thinking about it.
Let , where and
[...] The second rule says that is orthogonal to itself
Should that be "is not orthogonal to itself"? I thought the meant non-orthogonal, so would think means that is not orthogonal to itself.
(The transcript accurately reflects what was said in the talk, but I'm asking whether Scott misspoke.)
4
Yeah, you are right. I will change it. Thanks.
You said that you thought that this could be done in a categorical way. I attempted something which appears to describe the same thing when applied to the category FinSet , but I'm not sure it's the sort of thing you meant by when you suggested that the combinatorial part could potentially be done in a categorical way instead, and I'm not sure that it is fully categorical.
Let S be an object.
For i from 1 to k, let be an object, (which is not anything isomorphic to the product of itself with itself, or at least is not the terminal object) .
Let&n...
5
I have not thought much about applying to things other than finite sets. (I looked at infinite sets enough to know there is nontrivial work to be done.) I do think it is good that you are thinking about it, but I don't have any promises that it will work out.
What I meant when I think that this can be done in a categorical way is that I think I can define a nice symmetric monodical category of finite factored sets such that things like orthogonality can be given nice categorical definitions. (I see why this was a confusing thing to say.)
Some general comments:
Overcoming blindness
You mention above that Pearl's ontology 'has blinded us to the obvious next question'. I am very sympathetic to research programmes that try to overcome such blindness, this is the kind or research I have been doing myself recently. The main type of blindness that I have been trying to combat is blindness to complex types of self-referencing and indirect representation that can be present inside online machine learning agents, specifically in my recent work I have added a less blind viewpoint by modifying and...
I was thinking about the difficulty of finite factored sets not understanding the uniform distribution over 4 elements, and it makes me feel like something fundamental needs to be recast. An analogy came to mind about eigenvectors vs. eigenspaces.
What we might like to be true about the unit eigenvectors of a matrix is that they are the unique unit vectors for which the linear transformation preserves direction. But if two eigenvectors have the same eigenvalue, the choice of eigenvectors is not unique--we could choose any pair on that plane. So really, it s...
3
Hmm, I doubt the last paragraph about sets of partitions is going to be valuable, bet the eigenspace thinking might be useful.
Note that I gave my thoughts about how to deal with the uniform distribution over 4 elements in the thread responding to cousin_it.
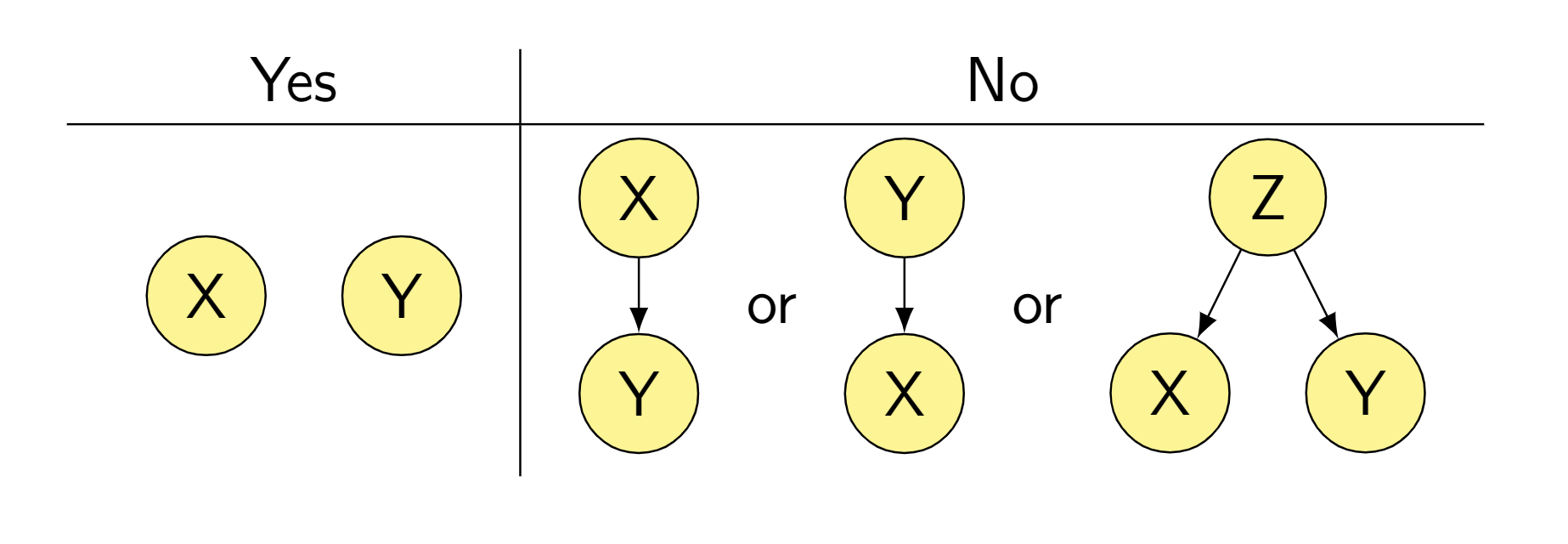
And if X is independent of X XOR Y, we’re actually going to be able to conclude that X is before Y!
It's interesting to translate that to the language of probabilities. For example, your condition holds for any X,Y (possibly dependent) such that P(X)=P(Y)=1/2, but it doesn't make sense to say that X is before Y in every such pair. For a real world example, take X = "person has above median height" and Y = "person has above median age".
4
So you should probably not work with probabilities equal to 1/2 in this framework, unless you are doing so for a specific reason. Just like in Pearlian causality, we are mostly talking about probabilities in general position. I have some ideas about how to deal with probability 1/2 (Have a FFS, together with a group of symmetry constraints, which could swap factors, or swap parts within a factor), but that is outside of the scope of what I am doing here.
To give more detail, the uniform distribution on four elements does not satisfy the compositional semigraphoid axioms, since if we take X, Y, Z to be the three partitions into two parts of size two, X is independent with Y and X is independent with Z, but X is not independent with the common refinement of Y and Z. Thus, if we take the orthogonality database generated by this probability distribution, you will find that it is not satisfied by any models.
3
The swapping within a factor allows for considering rational probabilities to be in general position, and the swapping factors allows IID samples to be considered in general position. I think this is an awesome research direction to go in, but it will make the story more complicated, since will not be able to depend on the fundamental theorem, since we are allowing for a new source of independence that is not orthogonality. (I want to keep calling the independence that comes from disjoint factors orthogonality, and not use "orthogonality" to describe the new independences that come from the principle of indifference.)
3
Yeah, that's what I thought, the method works as long as certain "conspiracies" among probabilities don't happen. (1/2 is not the only problem case, it's easy to find others, but you're right that they have measure zero.)
But there's still something I don't understand. In the general position, if X is before Y, it's not always true that X is independent of X XOR Y. For example, if X = "person has a car on Monday" and Y = "person has a car on Tuesday", and it's more likely that a car-less person gets a car than the other way round, the independence doesn't hold. It requires a conspiracy too. What's the intuitive difference between "ok" and "not ok" conspiracies?
3
I don't understand what conspiracy is required here.
X being orthogonal to X XOR Y implies X is before Y, we don't get the converse.
Well, imagine we have three boolean random variables. In "general position" there are no independence relations between them, so we can't say much. Constrain them so two of the variables are independent, that's a bit less "general", and we still can't say much. Constrain some more so the xor of all three variables is always 1, that's even less "general", now we can use your method to figure out that the third variable is downstream of the first two. Constrain some more so that some of the probabilities are 1/2, and the method stops working. What I'd like to understand is the intuition, which real world cases have the particular "general position" where the method works.
3
Ok, makes sense. I think you are just pointing out that when I am saying "general position," that is relative to a given structure, like FFS or DAG or symmetric FFS.
If you have a probability distribution, it might be well modeled by a DAG, or a weaker condition is that it is well modeled by a FFS, or an even weaker condition is that it is well modeled by a SFFS (symmetric finite factored set).
We have a version of the fundamental theorem for DAGs and d-seperation, we have a version of the fundamental theorem for FFS and conditional orthogonality, and we might get a version of the fundamental theorem for SFFS and whatever corresponds to conditional independence in that world.
However, I claim that even if we can extend to a fundamental theorem for SFFS, I still want to think of the independences in a SFFS as having different sources. There are the independences coming from orthogonality, and there are there the independences coming from symmetry (or symmetry together with orthogonality.
In this world, orthogonality won't be as inferable because it will only be a subset of independence, but it will still be an important concept. This is similar to what I think will happen when we go to the infinite dimensional factored sets case.
2
Can you give some more examples to motivate your method? Like the smoking/tar/cancer example for Pearl's causality, or Newcomb's problem and counterfactual mugging for UDT.
Hmm, first I want to point out that the talk here sort of has natural boundaries around inference, but I also want to work in a larger frame that uses FFS for stuff other than inference.
If I focus on the inference question, one of the natural questions that I answer is where I talk about grue/bleen in the talk.
I think for inference, it makes the most sense to think about FFS relative to Pearl. We have this problem with looking at smoking/tar/cancer, which is what if we carved into variables the wrong way. What if instead of tar/cancer, we had a variable for "How much bad stuff is in your body?" and "What is the ratio of tar to cancer?" The point is that our choice of variables both matters for the Pearlian framework, and is not empirically observable. I am trying to do all the good stuff in Pearl without the dependence on the variables
Indeed, I think the largest crux between FFS and Pearl is something about variable realism. To FFS, there is no realism to a variable beyond its information content, so it doesn't make sense to have two variables X, X' with the same information, but different temporal properties. Pearl's ontology, on the other hand, has these graphs with variabl...
2
Here is a more concrete example of me using FFS the way I intend them to be used outside of the inference problem. (This is one specific application, but maybe it shows how I intend the concepts to be manipulated).
I can give an example of embedded observation maybe, but it will have to come after a more formal definition of observation (This is observation of a variable, rather than the observation of an event above):
Definition: Given a FFS F=(S,B), and A, W, X, which are partitions of S, where X={x1,…,xn}, we say A observes X relative to W if:
1) A⊥X,
2) A can be expressed in the form A=A0∨S⋯∨SAn, and
3) Ai⊥W|(S∖xi).
(This should all be interpreted combinatorially, not probabilistically.)
The intuition of what is going on here is that to observe an event, you are being promised that you 1) do not change whether the event holds, and 3) do not change anything that matters in the case where that event does not hold. Then, to observe a variable, you can basically 2) split yourself up into different fragments of your policy, where each policy fragment observes a different value of that variable. (This whole thing is very updateless.)
Example 1: (non-observation)
An agent A={L,R} does not observe a coinflip X={H,T}, and chooses to raise either his left or right hand. Our FFS F=(S,B) is given by S=A×X, and B={A,X}. (I am abusing notation here slightly by conflating A with the partition you get on A×X by projecting onto the A coordinate.) Then W is the discrete partition on A×X.
In this example, we do not have observation. Proof: A only has two parts, so if we express A as a common refinement of 2 partitions, at least one of these two partitions must be equal to A. However, A is not orthogonal to W given H and A is not orthogonal to W given T. (hF(A|H)=hF(W|H)=hF(A|T)=hF(W|T)={A}). Thus we must violate condition 3.
Example 2: (observation)
An agent A={LL,LR,RL,RR} does observe a coinflip X={H,T}, and chooses to raise either his left or right hand. We can thin
3[comment deleted]
0
I’m confused what necessary work the Factorisation is doing in these temporal examples - in your example A and B are independent and C is related to both - the only assignment of “upstream/downstream” relations that makes sense is that C is downstream of both.
Is the idea that factorisation is what carves your massive set of possible worlds up into these variables in the first place? Feel like I’m in a weird position where the math makes sense but I’m missing the motivational intuition for why we want to switch to this framework in the first place
3
I are note sure what you are asking (indeed I am not sure if you are responding to me or cousin_it.)
One thing that I think is going on is that I use "factorization" in two places. Once when I say Pearl is using factorization data, and once where I say we are inferring a FFS. I think this is a coincidence. "Factorization" is just a really general and useful concept.
So the carving into A and B and C is a factorization of the world into variables, but it is not the kind of factorization that shows up in the FFS, because disjoint factors should be independent in the FFS.
As for why to switch to this framework, the main reason (to me) is that it has many of the advantages of Pearl with also being able to talk about some variables being coarse abstract versions of other variables. This is largely because I am interested in embedded agency applications.
Another reason is that we can't tell a compelling story about where the variables came from in the Pearlian story. Another reason is that sometimes we can infer time where Pearl cannot.
1
What would such a distribution look like? The version where X XOR Y is independent of both X and Y makes sense but I’m struggling to envisage a case where it’s independent of only 1 variable.
3
It looks like X and V are independent binary variables with different probabilities in general position, and Y is defined to be X XOR V. (and thus V=X XOR Y).
"Well, what if I take the variables that I'm given in a Pearlian problem and I just forget that structure? I can just take the product of all of these variables that I'm given, and consider the space of all partitions on that product of variables that I'm given; and each one of those partitions will be its own variable.
How can a partition be a variable? Should it be "part" instead?
2
Partitions (of some underlying set) can be thought of as variables like this:
* The number of values the variable can take on is the number of parts in the partition.
* Every element of the underlying set has some value for the variable, namely, the part that that element is in.
Another way of looking at it: say we're thinking of a variable v:S→D as a function from the underlying set S to v's domain D. Then we can equivalently think of v as the partition {{s∈S∣v(s)=d}∣d∈D}∖∅ of S with (up to) |D| parts.
In what you quoted, we construct the underlying set by taking all possible combinations of values for the "original" variables. Then we take all partitions of that to produce all "possible" variables on that set, which will include the original ones and many more.
2
Makes perfect sense, thanks!
Definition paraphrasing attempt / question:
Can we say "a factorization B of a set S is a set of nontrivial partitions of S such that " (cardinality not taken)? I.e., union(intersect(t in tuple) for tuple in cartesian_product(b in B)) = S. I.e., can we drop the intermediate requirement that each intersection has a unique single element, and only require the union of the intersections is equal to S?
3
If I understand correctly, that definition is not the same. In particular, it would say that you can get nontrivial factorizations of a 5 element set: {{{0,1},{2,3,4}},{{0,2,4},{1,3}}}.
1
That misses element 4 right?
>>> from itertools import product
>>> B = [[{0, 1}, {2, 3, 4}], [{0, 2, 3}, {1, 3}]]
>>> list(product(*B))
[({0, 1}, {0, 2, 3}),
({0, 1}, {1, 3}),
({2, 3, 4}, {0, 2, 3}),
({2, 3, 4}, {1, 3})]
>>> [set.intersection(*tup) for tup in product(*B)]
[{0}, {1}, {2, 3}, {3}]
>>> set.union(*[set.intersection(*tup) for tup in product(*B)])
{0, 1, 2, 3}
2
Looks like you copied it wrong. Your B only has one 4.
Curated. This is a fascinating framework that (to the best of my understanding) makes substantive improvements on the Pearlian paradigm. It's also really exciting that you found a new simple sequence.
Re: the writeup, it's explained very clearly, the Q&A interspersed is a very nice touch. I like that the talk factorizes.
I really appreciate the research exploration you do around ideas of agency and am very happy to celebrate the writeups like this when you produce them.
I'm confused by the definition of conditional history, because it doesn't seem to be a generalisation of history. I would expect , but both of the conditions in the definition of are vacuously true if . This is independent of what is, so . Am I missing something?
3
E is the event you are conditioning on, so the thing you should expect is that hF(X|S)=hF(X), which does indeed hold.
1
Thanks, that makes sense! Could you say a little about why the weak union axiom holds? I've been struggling to prove that from your definitions. I was hoping that hF(X|z,w)⊆hF(X|z) would hold, but I don't think that hF(X|z) satisfies the second condition in the definition of conditional history for hF(X|z,w).
3
When I prove it, I prove and use (a slight notational variation on) these two lemmas.
1. If hF(X|E)∩hF(Y|E)={}, then hF(X|E)=hF(X|(y∩E)) for all y∈Y.
2. hF((X∨SY)|E)=hF(X|E)∪⋃x∈XhF(Y|x∩E).
(These are also the two lemmas that I have said elsewhere in the comments look suspiciously like entropy.)
These are not trivial to prove, but they might help.
I don't understand the motivation behind the fundamental theorem, and I'm wondering if you could say a bit more about it. In particular, it suggests that if I want to propose a family of probability distributions that "represent" observations somehow ("represents" maybe means in the sense of Bayesian predictions or in the sense of frequentist limits), I want to also consider this family to arise from some underlying mutually independent family along with some function. I'm not sure why I would want to propose an underlying family and a function at all, and...
Hmm, I am not sure what to say about the fundamental theorem, because I am not really understanding the confusion. Is there something less motivating about the fundamental theorem, than the analogous theorem about d-seperation being equivalent to conditional independence in all distributions comparable with the DAG?
Maybe this helps? (probably not): I am mostly imagining interacting with only a single distributions in the class, and the claim about independence in all probability distributions comparable with the structure can be replaced with instead independence in a general position probability distribution comparable with the structure.
I am not thinking of it as related to a maximum entropy argument.
The point about SEMs having more structure that I am ignoring is correct. I think that the largest philosophical difference between my framework and Pearlian one is that I am denying realism of anything beyond the "apparently identical." Another way to think about it is that I am denying realism about there being anything about the variables beyond their information. All of my definitions are only based on the information content of the variables, and so, for example, if you have two...
I'm using some of the terminology I suggested here.
A factoring is a set of questions such that each signature of possible answers identifies a unique element. In 20 questions, you can tailor the questions depending on the answers to previous questions, and ultimately each element will have a bitstring signature depending on the history of yesses and nos. I guess you can define the question to include xors with previous questions, so that it effectively changes depending on the answers to others. But it's sometimes useful that the bitstrings are allowed to ...
6
I think that the answers to both the concern about 7 elements, and the desire to have questions depend of previous questions come out of thinking about FFS models, rather than FFS.
If you want to have 7 elements in Ω, that just means you will probably have more than 7 elements in S.
If I want to model a situation where some questions I ask depend on other questions, I can just make a big FFS that asks all the questions, and have the model hide some of the answers.
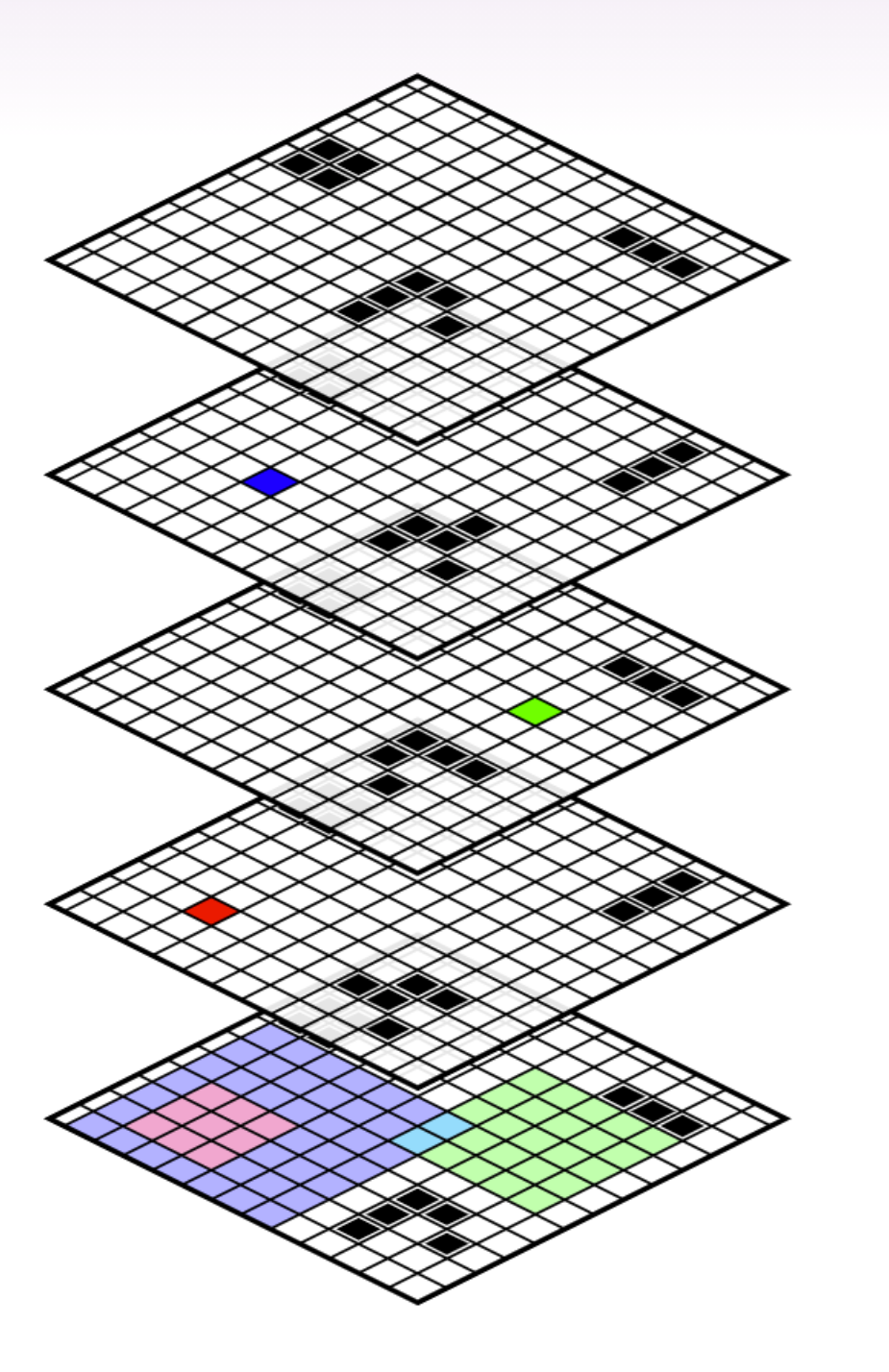
For example, Let's say I flip a biased coin, and then if heads I roll a biased 6 sided die, and if tails I roll a biased 10 sided die. There are 16 outcomes in Ω.
I can build a 3 dimensional factored set 2x6x10, which I will imagine as sitting on my table with height 2. heads is on the bottom, and tails is on the top. f:S→Ω will then merge together the rows on the bottom, and the columns on the top, so it will look a little like the game Jenga.
In this way, I am imagining there is some hidden data about each world in which I get heads and roll the 6 sided die, which is the answer to the question "what would have happened if I rolled the 10 sided die. Adding in all this counterfactual data gives a latent structure of 120 possible worlds, even though we can only distinguish 16 possible worlds.
4
If you look at the draft edits for this sequence that is still awaiting approval on OEIS, you'll find some formulas.
Curated and popular this week