This is cool! I wonder if it can be fixed. I imagine it could be improved some amount by nudging the prefix distribution, but it doesn't seem like that will solve it properly. Curious if this is a large issue in real LMs. It's frustrating that there aren't ground-truth features we have access to in language models.
I think how large of a problem this is can probably be inferred from a description of the feature distribution. It'd be nice to have a better sense of what that distribution is (assuming the paradigm is correct enough).
To generate the trees in sparselatents.com/tree_view, I use a variant of Masked Cosine Similarity (MCS), a metric introduced in Towards Monosemanticity. The original MCS is calculated like this: For any two latents A and B, first compute the cosine similarity between their activations, but only considering tokens where latent A is active. Then compute the same similarity, but only for tokens where latent B is active. The final MCS value is the larger of these two similarities.
Instead of taking the max, I do a directed MCS where I just consider the cosine similarity between A and B's activations on tokens where B is active. Then, I multiply this directed MCS score by max(B activations)/max(A activations) to ignore latents that don't fire very much. I'm not sure that this multiplication step is necessary.
I also use a higher threshold of 0.6.
Starting from a parent latent, say S/1/12, I find all latents in a larger-width SAE (say S/2) that pass the directed MCS threshold. Then, I re-apply the method to those S/2 latents to find children in S/3.
The result is often a non-tree DAG as some of the identified latents in S/3 have more than one parent in S/2. To simplify rendering, I assign these latents to the parent they have the highest score with. This obscures the true structure, but I wasn't sure of a clean way to automatically render these DAGs.
The trees should be thought of not as fully displaying the structure of the model, but instead of surfacing small sets of latents that I expect demonstrate feature absorption when viewed together.
The Matryoshka SAE trained on the toy model learn the true features on most runs, not all of them. Sometimes a small number of latents, modally one, seem to get stuck in a bad state.
I thought I had some informal evidence that permuting the latents was good and after double checking some evidence I don't feel confident that it is good.
Training without permutation seems to attain slightly better FVU/L0, has reasonable looking features at a quick glance, seems to solve the toy model at comparable rates to permuted, and is simpler to code.
This is great work! I like that you tested on large models and your very comprehensive benchmarking. I also like the BatchTopK architecture.
It's interesting to me that MSE has a smaller hit than cross-entropy.
Here are some notes I made:
We suspect that using a fixed group size leads to more stable training and faster convergence.
This seems plausible to me!
Should the smallest sub-SAE get gradients from all losses, or should the losses from larger sub-SAEs be stopped?
When I tried stopping the gradient from flowing from large sub-SAE losses to small it made later latents much less interpretable. I tried an approach where early latents got less gradient from larger sub-SAE losses and it seemed to also have less interpretable late latents. I don't know what's going on with this.
What is the effect of latent sorting that Noa uses on the benchmarks?
I tried not ordering the latents and it did comparably on FVU/L0. I vaguely recall that for mean-max correlation, permuting did worse on early latents and better on the medium latents. At a quick glance I weakly preferred the permuted SAE latents but it was very preliminary and I'm not confident in this.
I'd love to chat more with the authors, I think it'd be fun to explore our beliefs and process over the course of making the papers and compare notes and ideas.
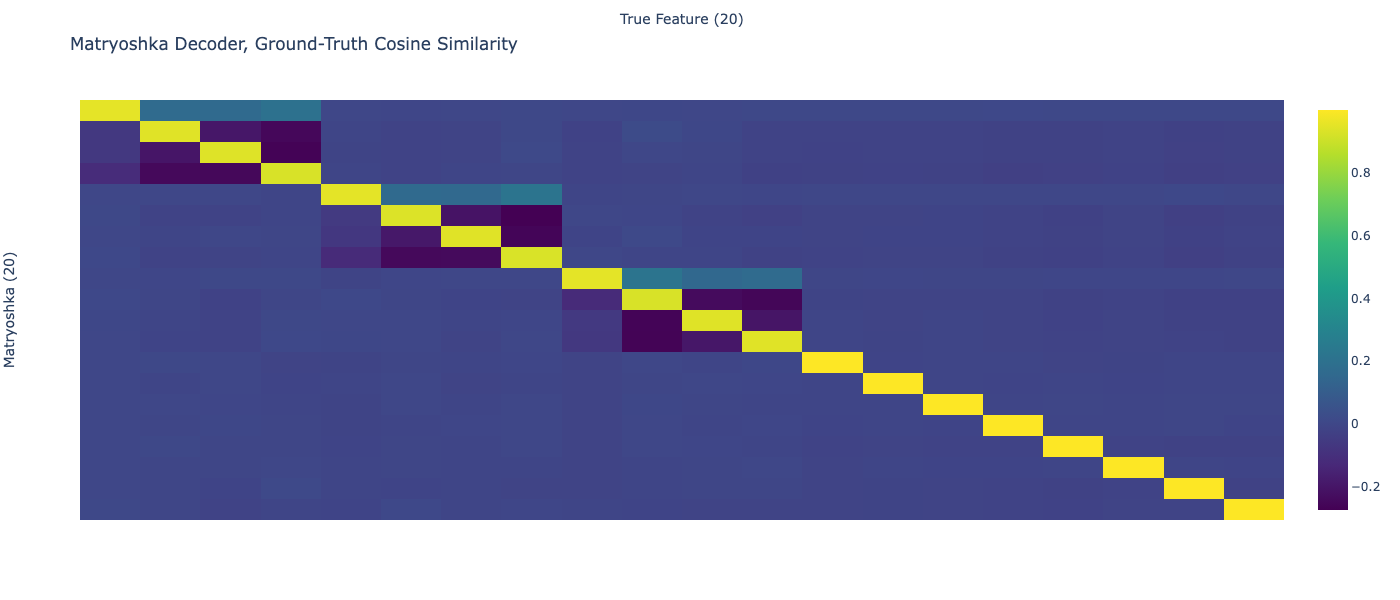
Even with all possible prefixes included in every batch the toy model learns the same small mixing between parent and children (this was best out of 2, for the first run the matryoshka didn't represent one of the features): https://sparselatents.com/matryoshka_toy_all_prefixes.png
Here's a hypothesis that could explain most of this mixing. If the hypothesis is true, then even if every possible prefix is included in every batch, there will still be mixing.
Hypothesis:
Regardless of the number of prefixes, there will be some prefix loss terms where
1. a parent and child feature are active
2. the parent latent is included in the prefix
3. the child latent isn't included in the prefix.
The MSE loss in these prefix loss terms is pretty large because the child feature isn't represented at all. This nudges the parent to slightly represent all of its children a bit.
To compensate for this, if a child feature is active and the child latent is included the prefix, it undoes the parent decoder vector's contribution to the features of the parent's other children.
This could explain these weird properties of the heatmap:
- Parent decoder vector has small positive cosine similarity with child features
- Child decoder vectors have small negative cosine similarity with other child features
Still unexplained by this hypothesis:
- Child decoder vectors have very small negative cosine similarity with the parent feature.
That's very cool, I'm looking forward to seeing those results! The Top-K extension is particularly interesting, as that was something I wasn't sure how to approach.
I imagine you've explored important directions I haven't touched like better benchmarking, top-k implementation, and testing on larger models. Having multiple independent validations of an approach also seems valuable.
I'd be interested in continuing this line of research, especially circuits with Matryoshka SAEs. I'd love to hear about what directions you're thinking of. Would you want to have a call sometime about collaboration or coordination? (I'll DM you!)
Really looking forward to reading your post!
Yes, follow up work with bigger LMs seems good!
I use number of prefix-losses per batch = 10 here; I tried 100 prefixes per batch and the learned latents looked similar at a quick glance, so I wonder if naively training with block size = 1 might not be qualitatively different. I'm not that sure and training faster with kernels on its own seems good also!
Maybe if you had a kernel for training with block size = 1 it would create surface area for figuring out how to work on absorption when latents are right next to each other in the matryoshka latent ordering.
I wonder if multiple heads having the same activation pattern in a context is related to the limited rank per head; once the VO subspace of each head is saturated with meaningful directions/features maybe the model uses multiple heads to write out features that can't be placed in the subspace of any one head.
{kind=link}
You know I was thinking ab this-- say that there are two children and they're orthogonal to the parent and each have probability 0.4 given the parent. If you imagine the space it looks like three clusters, two with probability 0.4, norm 1.4 and one with probability 0.2 and norm 1. They all have high cosine similarity with each other. From this frame, having the parent 'include' the children directions a bit doesn't seem that inappropriate. One SAE latent setup that seems pretty reasonable is to actually have one parent latent that's like "one of these three clusters is active" and three child latents pointing to each of the three clusters. The parent latent decoder in that setup would also include a bit of the child feature directions.
This is all sketchy though. It doesn't feel like we have a good answer to the question "How exactly do we want the SAEs to behave in various scenarios?"