Epistemic Status: My best guess
Epistemic Effort: ~75 hours of work put into this document
Contributions: Thomas wrote ~85% of this, Eli wrote ~15% and helped edit + structure it. Unless specified otherwise, writing in the first person is by Thomas and so are the opinions. Thanks to Miranda Zhang, Caleb Parikh, and Akash Wasil for comments. Thanks to many others for relevant conversations.
Introduction
Despite a clear need for it, a good source explaining who is doing what and why in technical AI alignment doesn't exist. This is our attempt to produce such a resource. We expect to be inaccurate in some ways, but it seems great to get out there and let Cunningham’s Law do its thing.[1]
The main body contains our understanding of what everyone is doing in technical alignment and why, as well as at least one of our opinions on each approach. We include supplements visualizing differences between approaches and Thomas’s big picture view on alignment. The opinions written are Thomas and Eli’s independent impressions, many of which have low resilience. Our all-things-considered views are significantly more uncertain.
This post was mostly written while Thomas was participating in the 2022 iteration SERI MATS program, under mentor John Wentworth. Thomas benefited immensely from conversations with other SERI MATS participants, John Wentworth, as well as many others who I met this summer.
Disclaimers:
- This post is our understanding and has not been endorsed by the people doing the work itself.
- The length of the summaries varies according to our knowledge of this approach, and is not meant to reflect a judgement on the quality or quantity of work done.
- We are not very familiar with most of the academic alignment work being done, and have only included a few academics.
A summary of our understanding of each approach:
| Approach | Problem Focus | Current Approach Summary | Scale |
| Aligned AI | Model splintering | Solve extrapolation problems. | 2-5 researchers, started Feb 2022 |
| ARC | Inaccessible information | ELK + LLM power-seeking evaluation | 3 researchers, started April 2021 |
| Anthropic | LLM Outer Alignment (?)[3] | Interpretability + HHH + augmenting alignment research with LLMs | ~35? technical staff[3], started May 2021 |
| Brain-like-AGI Safety | Brain-like AGI Safety | Use brains as a model for how AGI will be developed, think about alignment in this context | ~4 researchers, started March 2021 |
| Center for AI Safety (CAIS) | Engaging the ML community, many technical problems | Technical research, Infrastructure, and ML community field-building for safety | 7-10 FTE, founded in ~March 2022 |
| CHAI | Outer alignment, though CHAI is diverse | Improve CIRL + many other independent approaches. | ~20 FTE?, founded in 2016 |
| CLR | Suffering risks | Foundational game theory research | 5-10 FTE, founded before 2015 |
| Conjecture | Inner alignment | Interpretability + automating alignment research with LLMs | ~20 FTE, announced April 2022 |
| David Krueger | Goal misgeneralization
| Empirical examples and understanding ML inductive biases
| Academic lab with 7 students |
| DeepMind | Many including scalable oversight and goal misgeneralization | Many including Debate, discovering agents, ERO, and understanding threat models. [4] | >1000 FTE for the company as a whole, ~20-25 FTE on the alignment + scalable alignment teams |
| Dylan Hadfield-Menell | Value Alignment | Reward specification + Norms | Academic research lab |
| Encultured | Multipolar failure from lack of coordination | Video game | ~3 people, announced August 2022 |
| Externalized Reasoning Oversight | Deception | Get the reasoning of the AGI to happen in natural language, then oversee that reasoning | ~1 person's project for a summer (though others are working on this approach) |
| FHI | Agent incentives / wireheading (?) | Causal model formalism to study incentives. | ~3 people in the causal group / ~20 total?, FHI founded in 2005, Causal group founded in 2021 |
| FAR | Many | Incubate new, scalable alignment research agendas, technical support for existing researchers | 4 people on leadership but I'm guessing ~5 more engineers, announced July 2022 |
| MIRI | Many including deception, the sharp left turn, corrigibility is anti-natural | Mathematical research to resolve fundamental confusion about the nature of goals/agency/optimization | 11 research staff, founded in approximately 2005 |
| Jacob Steinhardt | Distribution Shift | Conceptual alignment | Academic lab of 9 PhD students + Postdocs |
| OpenAI | Scalable oversight | RLHF / Recursive Reward Modeling, then automate alignment research | 100 capabilities and 30 alignment researchers, founded December 2015. |
| Ought | Scalable oversight | Supervise process rather than outcomes + augment alignment researchers | 10 employees, founded in ~2018 |
| Redwood | Inner alignment (?) | Interpretability + Adversarial Training | 12-15 research staff, started sometime before September 2021 |
| Sam Bowman | LLM Outer Alignment | Creating datasets for evaluation + inverse scaling prize
| Academic lab |
| Selection Theorems | Being able to robustly point at objects in the world | Selection Theorems based on natural abstractions | ~2 FTE, started around August 2019 |
| Team Shard | Instilling inner values from an outer training loop | Find patterns of values given by current RL setups and humans, then create quantitative rules to do this | ~4-6 people, started Spring 2022 |
| Truthful AI | Deception | Create standards and datasets to evaluate model truthfulness | ~10 people, one research project |
Previous related overviews include:
- Neel Nanda's My Overview of the AI Alignment Landscape
- Evan Hubinger's An overview of 11 proposals for building safe advanced AI
- Larks' yearly Alignment Literature Review and Charity Comparison
- Nate Soares' On how various plans miss the hard bits of the alignment challenge
- Andrew Critch's Some AI research areas and their relevance to existential safety
- 80,000 Hours’ list of organizations working in the area
Aligned AI / Stuart Armstrong
One of the key problems in AI safety is that there are many ways for an AI to generalize off-distribution, so it is very likely that an arbitrary generalization will be unaligned. See the model splintering post for more detail. Stuart's plan to solve this problem is as follows:
- Maintain a set of all possible extrapolations of reward data that are consistent with the training process
- Pick among these for a safe reward extrapolation.
They are currently working on algorithms to accomplish step 1: see Value Extrapolation.
Their initial operationalization of this problem is the lion and husky problem. Basically: if you train an image model on a dataset of images of lions and huskies, the lions are always in the desert, and the huskies are always in the snow. So the problem of learning a classifier is under-defined: should the classifier be classifying based on the background environment (e.g. snow vs sand), or based on the animal in the image?
A good extrapolation algorithm, on this problem, would generate classifiers that extrapolate in all the different ways[4], and so the 'correct' extrapolation must be in this generated set of classifiers. They have also introduced a new dataset for this, with a similar idea: Happy Faces.
Step 2 could be done in different ways. Possibilities for doing this include: conservatism, generalized deference to humans, or an automated process for removing some goals. like wireheading/deception/killing everyone.
Opinion: I like that this approach tries to tackle distributional shift, which might I see as one of the fundamental hard parts of alignment.
The problem is that I don't see how to integrate this approach for solving this problem with deep learning. It seems like this approach might work well for a model-based RL setup where you can make the AI explicitly select for this utility function.
It is unclear to me how to use this to align an end-to-end AI training pipeline. The key problem unsolved by this is how to get inner values into a deep learning system via behavioral gradients: reward is not the optimization target. Generating a correct extrapolation of human goals does not let us train a deep learning system to accomplish these goals.
Alignment Research Center (ARC)
Eliciting Latent Knowledge / Paul Christiano
ARC is trying to solve Eliciting Latent Knowledge (ELK). Suppose that you are training an AI agent that predicts the state of the world and then performs some actions, called a predictor. This predictor is the AGI that will be acting to accomplish goals in the world. How can you create another model, called a reporter, that tells you what the predictor believes about the world? A key challenge in training this reporter is that training your reporter on human labeled training data, by default, incentivizes the predictor to just model what the human thinks is true, because the human is a simpler model than the AI.
Motivation: At a high level, Paul's plan seems to be to produce a minimal AI that can help to do AI safety research. To do this, preventing deception and inner alignment failure are on the critical path, and the only known solution paths to this require interpretability (this is how all of Evan's 11 proposals plan to get around this problem).
If ARC can solve ELK, this would be a very strong form of interpretability: our reporter is able to tell us what the predictor believes about the world. Some ways this could end up being useful for aligning the predictor include:
- Using the reporter to find deceptive/misaligned thoughts in the predictor, and then optimizing against those interpreted thoughts. At any given point in time, SGD only updates the weights a small amount. If an AI becomes misaligned, it won't be very misaligned, and the interpretability tools will be able to figure this out and do a gradient step to make it aligned again. In this way, we can prevent deception at any point in training.
- Stopping training if the AI is misaligned.
Opinion: There are several key uncertainties that I have with this approach.
- I am not sure if there exists an ELK solution, even in theory. Even if such a thing exists, I am not sure if it will be tractable to implement.
- Optimizing against your reporter puts optimization pressure into regions in which the classifier deceives you and the reporter, or more generally where the reporter fails.
- Depending on how ELK gets used, there seems like a risk of too many AIs: if your reporter must be "smarter" than your predictor, there might be coordination between the predictor and reporter, or the reporter might become agentic and cause catastrophe. In other words, many approaches built off ELK seem like godzilla strategies.
Overall, ELK seems like one of the most promising angles of attack on the problem because it seems both possible to make progress on and also actually useful towards solving alignment: if it works it would let us avoid deception. It is simple and naturally becomes turned into a proposal for alignment. I'm very excited about more effort being put towards solving ELK.
While this seems like a very powerful form of interpretability, there are also some limitations, for example, solving ELK does not immediately tell you how the internals of your agent works, as would be required for a plan like retargeting the search.
Evaluating LM power-seeking / Beth Barnes
Beth is working on “generating a dataset that we can use to evaluate how close models are to being able to successfully seek power”. The dataset is being created through simulating situations in which an LLM is trying to seek power.
The overall goal of the project is to assess how close a model is to being dangerous, e.g. so we can know if it’s safe for labs to scale it up. Evaluations focus on whether models are capable enough to seek power successfully, rather than whether they are aligned. They are aiming to create an automated evaluation which takes in a model and outputs how far away from dangerous it is, approximating an idealized human evaluation.
Eli’s opinion: I’m very excited about this direction, but I think for a slightly different reason than Beth is. There’s been lots of speculation about how close the capabilities of current systems are to being able to execute complex strategies like “playing the training game”, but very little empirical analysis of how “situationally aware” models actually are. The automated metric is an interesting idea, but I’m most excited about getting a much better understanding of the situational awareness of current models through rigorous human evaluation; the project also might produce compelling examples of attempts at misaligned power-seeking in LLMs that could be very useful for field-building (convincing ML researchers/engineers).
Opinion: I think this only works in a slowish takeoff world where we can continuously measure deception. I am ~70% in a world where AGI capabilities jump fast enough that this type of evaluation doesn't help. It seems really hard to know when AGI will come.
In the world where takeoffs are slow enough that this is meaningful, the difficulty then becomes getting labs to actually slow down based on this data: if this worked, it would be hugely valuable. Even if it doesn't get people to slow down, it might help inform alignment research about likely failure modes for LLMs.
Anthropic
LLM Alignment
Anthropic fine tuned a language model to be more helpful, honest and harmless: HHH.
Motivation: I think the point of this is to 1) see if we can "align" a current day LLM, and 2) raise awareness about safety in the broader ML community.
Opinion: This seems… like it doesn't tackle what I see as the core problems in alignment. This may make current day language models being less obviously misaligned, but that doesn't seem like that helps us at all to align AGIs.
Interpretability
Chris Olah, the interpretability legend, is working on looking really hard at all the neurons to see what they all mean. The approach he pioneered is circuits: looking at computational subgraphs of the network, called circuits, and interpreting those. Idea: "decompiling the network into a better representation that is more interpretable". In-context learning via attention heads, and interpretability here seems useful.
One result I heard about recently: a linear softmax unit stretches space and encourages neuron monosemanticity (making a neuron represent only one thing, as opposed to firing on many unrelated concepts). This makes the network easier to interpret.
Motivation: The point of this is to get as many bits of information about what neural networks are doing, to hopefully find better abstractions. This diagram gets posted everywhere, the hope being that networks, in the current regime, will become more interpretable because they will start to use abstractions that are closer to human abstractions.
Opinion: This seems like it won't scale up to AGI. I think that model size is the dominant factor in making things difficult to interpret, and so as model size scales to AGI, things will become ever less interpretable. If there was an example of networks becoming more interpretable as they got bigger, this would update me (and such an example might already exist, I just don't know of it).
I would love a new paradigm for interpretability, and this team seems like probably the best positioned to find such a paradigm.
There is a difficult balance to be made here, because publishing research helps with both alignment and capabilities. They are very aware of this, and have thought a lot about this information tradeoff, but my inclination is that they are on the wrong side: I would rather they publish less. Even though this research helps safety some, buying more time is just more important than knowing more about safety right now.
Scaling laws
The basic idea is to figure out how model performance scales, and use this to help understand and predict what future AI models might look like, which can inform timelines and AI safety research. A classic result found that you need to increase data, parameters, and compute all at the same time (at roughly the same rate) in order to improve performance. Anthropic extended this research here.
Opinion: I am guessing this leads to capabilities gains because it makes the evidence for data+params+compute = performance much stronger and clearer. Why can't we just privately give this information to relevant safety researchers instead of publishing it publicly?
I'm guessing that the point of this was to shift ML culture: this is something valuable and interesting to mainstream ML practitioners which means they will read this safety focused paper.
Brain-Like-AGI Safety / Steven Byrnes
[Disclaimer: haven't read the whole sequence]. This is primarily Steven Brynes, a full time independent alignment researcher, working on answering the question: "How would we align an AGI whose learning algorithms / cognition look like human brains?"
Humans seem to robustly care about things, why is that? If we understood that, could we design AGIs to do the same thing? As far as I understand it, most of this work is biology based: trying to figure out how various parts of the brain works, but then also connecting this to alignment and seeing if we can solve the alignment problem with this understanding.
There are three other independent researchers working on related projects that Steven has proposed.
Opinion: I think it's quite likely that we get useful bits of information and framings from this analysis. On the current margin, I think it is very good that we have some people thinking about brain-like AGI safety, and I also think this research is less likely to be dual use.
I also find it unlikely (~30%) that we'll get brain-like AGI as opposed to prosaic AGI.
Center for AI Safety (CAIS) / Dan Hendrycks
Rewritten slightly after Thomas Woodside (an employee of CAIS) commented. I recommend reading his comment, as well as their sequence, Pragmatic AI Safety, which lays out a more flushed out description of their theory of impact.
Right now, only a very small subset of ML researchers are thinking about x-risk from AGI. CAIS seeks to change this -- their goal is to get the broader ML community, including both industry and academia.
CAIS is working on a number of projects, including:
- Writing papers that talk about x-risk.
- Publishing compilations of open problems.
- Make safety benchmarks that the ML community can iterate on.
- Running a NeurIPS competition on these benchmarks.
- Running the ML Safety Scholars program (MLSS)
- A Philosophy Fellowship aimed at recruiting philosophers to do conceptual alignment research.
One of these competitions is a Trojan detection competition, which is a way of operationalizing deceptive alignment. A Trojan is a backdoor into a neural network that causes it to behave weirdly on a very specific class of inputs. These are often trained into a model via poisoned data. Trojans are similar to deceptive alignment because there are a small number of examples (e.g. 300 out of 3 million training examples) that cause very different behavior (e.g. a treacherous turn), while for the vast majority of inputs cause the model to perform normally.
This competition is in a builder breaker format, with rewards for both detecting trojans as well as coming up with trojans that no one else could detect.
Opinion: One worry with the competition is that contestants will pursue strategies that work right now but won't work for AGI, because they are trying to win the competition instead of align AGIs.
Engaging the broader ML community to reduce AGI x-risk seems robustly good both for improving the quality of the discourse and steering companies and government away from building AGI unsafely.
Center for Human Compatible AI (CHAI) / Stuart Russell
CHAI is an academic research organization affiliated with UC Berkeley. It is lead by Stuart Russell, but includes many other professors and grad students pursuing a diverse array of approaches, most of whom I will not summarize here. For more information see their 2022 progress report.
Stuart wrote the book Human Compatible, in which he outlines his AGI alignment strategy, which is based on cooperative inverse reinforcement learning (CIRL). The basic idea of CIRL is to play a cooperative game where both the agent and the human are trying to maximize the human's reward, but only the human knows what the human reward is. Since the AGI has uncertainty it will defer to humans and be corrigible.
Other work that I liked is Clusterability in neural networks: try to measure the modularity of neural networks by thinking of the network as a graph and performing the graph n-cut.
Opinion: CIRL might make sense in a non-deep learning paradigm, but I think that deep learning will scale to AGI (~95%). The problem of getting a deep learning system to 'try' to maximize the human's reward is the hard part. Viewed this way, CIRL is a wrong way reduction. Some discussion on this is here.
Eli’s opinion: My understanding is that both Stuart and others mainly expect CIRL to potentially be helpful if deep learning doesn’t scale to AGI, but I expect deep learning to scale to AGI with >80% probability.
Center on Long Term Risk (CLR)
CLR is focused primarily on reducing suffering-risk (s-risk), where the future has a large negative value. They do foundational research in game theory / decision theory, primarily aimed at multipolar AI scenarios. One result relevant to this work is that transparency can increase cooperation.
Update after Jesse Clifton commented: CLR also works on improving coordination for prosaic AI scenarios, risks from malevolent actors and AI forecasting. The Cooperative AI Foundation (CAIF) shares personnel with CLR, but is not formally affiliated with CLR, and does not focus just on s-risks.
Opinion: I have <1% credence in agential s-risk happening, which is where most of the worry from s-risk is as far as I can tell. I have ~70% on x-risk from AGI, so I don't think s-risk is worth prioritizing. I also view the types of theoretical research done here as being not very tractable.
I also find it unlikely (<10%) that logic/mathy/decision theory stuff ends up being useful for AGI alignment.
Eli’s opinion: I haven’t engaged with it much but am skeptical for similar reasons to Thomas, though I have closer to ~5% on s-risk.
Conjecture
Conjecture is an applied org focused on aligning LLMs (Q & A here). Conjecture has short timelines (the org acts like timelines are between ~5-10 year, but some have much shorter timelines, such as 2-4 years), and they think alignment is hard. They take information hazards (specifically ideas that could lead towards better AI capabilities) very seriously, and have a public infohazard document.
Epistemology
The alignment problem is really hard to do science on: we are trying to reason about the future, and we only get one shot, meaning that we can't iterate. Therefore, it seems really useful to have a good understanding of meta-science/epistemology, i.e. reasoning about ways to do useful alignment research.
An example post I thought was very good.
Opinion: Mixed. One part of me is skeptical that we should be going up a meta layer instead of trying to directly solve the problem — solving meta-science seems really hard and quite indirect. On the other hand, I consistently learn a lot from reading Adam's posts, and I think others do too, and so this work does seem really helpful.
This would seem to be more useful in the long timelines world, contradicting Conjecture's worldview, however, another key element of their strategy is decorrelated research bets, and this is certainly quite decorrelated.
Eli’s opinion: I’m a bit more positive on this than Thomas, likely because I have longer timelines (~10-15% within 10 years, median ~25-30 years).
Scalable LLM Interpretability
I don't know much about their research here, other than that they train their own models, which allow them to work on models that are bigger than the biggest publicly available models, which seems like a difference from Redwood.
Current interpretability methods are very low level (e.g., "what does x neuron do"), which does not help us answer high level questions like "is this AI trying to kill us".
They are trying a bunch of weird approaches, with the goal of scalable mechanistic interpretability, but I do not know what these approaches actually are.
Motivation: Conjecture wants to build towards a better paradigm that will give us a lot more information, primarily from the empirical direction (as distinct from ARC, which is working on interpretability with a theoretical focus).
Opinion: I like the high level idea, but I have no idea how good the actual research is.
Refine
Refine is an incubator for new decorrelated alignment "research bets". Since no approach is very promising right now for solving alignment, the purpose of this is to come up with a bunch of independent new ideas, and hopefully some of these will work.
Opinion: Refine seems great because focusing on finding new frames seems a lot more likely to succeed than the other ideas.
Eli’s opinion: Agree with Thomas, I’m very excited about finding smart people with crazy-seeming decorrelated ideas and helping them.
Simulacra Theory
The goal of this is to create a non-agentic AI, in the form of an LLM, that is capable of accelerating alignment research. The hope is that there is some window between AI smart enough to help us with alignment and the really scary, self improving, consequentialist AI. Some things that this amplifier might do:
- Suggest different ideas for humans, such that a human can explore them.
- Give comments and feedback on research, be like a shoulder-Eliezer
A LLM can be thought of as learning the distribution over the next token given by the training data. Prompting the LM is then like conditioning this distribution on the start of the text. A key danger in alignment is applying unbounded optimization pressure towards a specific goal in the world. Conditioning a probability distribution does not behave like an agent applying optimization pressure towards a goal. Hence, this avoids goodhart-related problems, as well as some inner alignment failure.
One idea to get superhuman work from LLMs is to train it on amplified datasets like really high quality / difficult research. The key problem here is finding the dataset to allow for this.
There are some ways for this to fail:
- Outer alignment: It starts trying to optimize for making the actual correct next token, which could mean taking over the planet so that it can spend a zillion FLOPs on this one prediction task to be as correct as possible.
- Inner alignment:
- An LLM might instantiate mesa-optimizers, such as a character in a story that the LLM is writing, and this optimizer might realize that they are in an LLM and try to break out and affect the real world.
- The LLM itself might become inner misaligned and have a goal other than next token prediction.
- Bad prompting: You ask it for code for a malign superintelligence; it obliges. (Or perhaps more realistically, capabilities).
Conjecture are aware of these problems and are running experiments. Specifically, an operationalization of the inner alignment problem is to make an LLM play chess. This (probably) requires simulating an optimizer trying to win at the game of chess. They are trying to use interpretability tools to find the mesa-optimizers in the chess LLM that is the agent trying to win the game of chess. We haven't ever found a real mesa-optimizer before, and so this could give loads of bits about the nature of inner alignment failure.
My opinion: This work seems robustly useful in understanding how we might be able to use tool AIs to solve the alignment problem. I am very excited about all of this work, and the motivation is very clear to me.
Eli’s opinion: Agree with Thomas.
David Krueger
David runs a lab at the University of Cambridge. Some things he is working on include:
- Operationalizing inner alignment failures and other speculative alignment failures that haven't actually been observed.
- Understanding neural network generalization.
For work done on (1), see: Goal Misgeneralization, a paper that empirically demonstrated examples of inner alignment failure in Deep RL environments. For example, they trained an agent to get closer to cheese in a maze, but where the cheese was always in the top right of a maze in the training set. During test time, when presented with cheese elsewhere, the RL agent navigated to the top right instead of to the cheese: it had learned the mesa objective of "go to the top right".
For work done on (2), see OOD Generalization via Risk Extrapolation, an iterative improvement on robustness to previous methods.
I'm not sure what his motivation is for these specific research directions, but my guess is that these are his best starts on how to solve the alignment problem.
Opinion: I'm mixed on the Goal Misgeneralization. On one hand, it seems incredibly good to simply be able to observe misaligned mesaoptimization in the wild. On the other hand, I feel like I didn't learn much from the experiment because there are always many ways that the reward function could vary OOD. So whatever mesa objective was learned this system would therefore be a 'misaligned mesaoptimizer' with respect to all of the other variations OOD. (The paper states that goal misgeneralization is distinct from mesaoptimization, and I view this as mostly depending on what your definition of optimizer is, but I think that I'd call pretty much any RL agent an optimizer.) I view also view this as quite useful for getting more of academia interested in safety concerns, which I think is critical for making AGI go well.
I'm quite excited about understanding generalization better, particularly while thinking about goal misgneralization, this seems like a very useful line of research.
DeepMind
Updated after Rohin's comment.
DeepMind has both a ML safety team focused on near-term risks, and an alignment team that is working on risks from AGI. The alignment team is pursuing many different research avenues, and is not best described by a single agenda.
Some of the work they are doing is:
- Engaging with recent MIRI arguments.
- Rohin Shah produces the alignment newsletter.
- Publishing interesting research like the Goal Misgeneralization paper.
- Geoffrey Irving is working on debate as an alignment strategy: more detail here.
- Discovering agents, which introduces a causal definition of agents, then introduces an algorithm for finding agents from empirical data.
- Understanding and distilling threat models, e.g. "refining the sharp left turn" and "will capabilities generalize more".
See Rohin's comment for more research that they are doing, including description of some that is currently unpublished so far.
Opinion: I am negative about DeepMind as a whole because it is one of the organizations closest to AGI, so DeepMind is incentivizing race dynamics and reducing timelines.
However, the technical alignment work looks promising and appears to be tackling difficult problems that I see as the core difficulties of alignment like inner alignment/sharp left turn problems, as well as foundational research understanding agents. I am very excited about DeepMind engaging with MIRI's arguments.
Dylan Hadfield-Menell
Dylan's PhD thesis argues three main claims (paraphrased):
- Outer alignment failures are a problem.
- We can mitigate this problem by adding in uncertainty.
- We can model this as Cooperative Inverse Reinforcement Learning (CIRL).
Thus, his motivations seem to be modeling AGI coming in some multi-agent form, and also being heavily connected with human operators.
I'm not sure what he is currently working on, but some recent alignment-relevant papers that he has published include:
- Work on instantiating norms into AIs to incentivize deference to humans.
- Theoretically formulating the principal-agent problem.
Dylan has also published a number of articles that seem less directly relevant for alignment.
Opinion: I don't see how this gets at the core problems in alignment, which I view as being related to inner alignment / sharp left turn / distribution shift, and I wish that outer alignment approaches also focused on robustness to distribution shift. How do you get this outer alignment solution into the deep learning system? However, if there is a way to do this (with deep learning) I am super on board and would completely change my mind. The more recent stuff seems less relevant.
Encultured
See post.
Enclutured are making a multiplayer online video game as a test environment for AI: an aligned AI should be able to play the game without ruining the fun or doing something obviously destructive like completely taking over the world, even if it has this capabilities. This seems roughly analogous to setting an AGI loose on the real world.
Motivation: Andrew Critch is primarily concerned about a multipolar AI scenario: there are multiple actors with comparably powerful AI, on the cusp of recursive self improvement. The worst case is a race, and even though each actor would want to take more time checking their AGI for safety, worry that another actor will deploy will push each actor to take shortcuts and try to pull off a world-saving act. Instead of working directly on AI, which can accelerate timelines and encourage racing, creating this standardized test environment where alignment failures are observable is one component of a good global outcome.
Opinion: I don't really see how this helps, on my models we mostly have one shot: by the time we see the core difficulties of alignment, we are past the point of no return, because that AGI is sufficiently powerful to control the world. Therefore the alignment failures that we can observe in this game seem like they won't give us useful information.
On the other hand, this might be really helpful in slow takeoff worlds where alignment failures are obvious in the video game (e.g. deception isn't selected for), and these failures are relatively easy to fix.
Externalized Reasoning Oversight / Tamera Lanham
Idea: Make the AGI, which is an LLM, externalize its reasoning (via chain of thought) so that its thoughts are visible to an external overseer, which then verifies that the LLM is not thinking deceptive thoughts.
This scheme requires:
- Not too much steganography: the model can't hide its reasoning in non-english logical thought. This is the default of what would happen if we apply RL to this model maybe?
- A safe overseer that can look through the chain of thought reasoning and identify misaligned behavior.
A key dynamic is that english is not the ideal language to be reasoning: an AGI could be more capable by doing some reasoning not in English. Thus, applying RL to a model exerts pressure towards ideal logical reasoning. However, self-supervised learning (SSL) exerts some pressure back towards just doing text prediction, and hence more of its reasoning being in English. A key question for this research agenda is thus how to put pressure to keep the reasoning externalized, instead of collapsing into internal, more efficient/logical reasoning that is much harder for us to oversee.
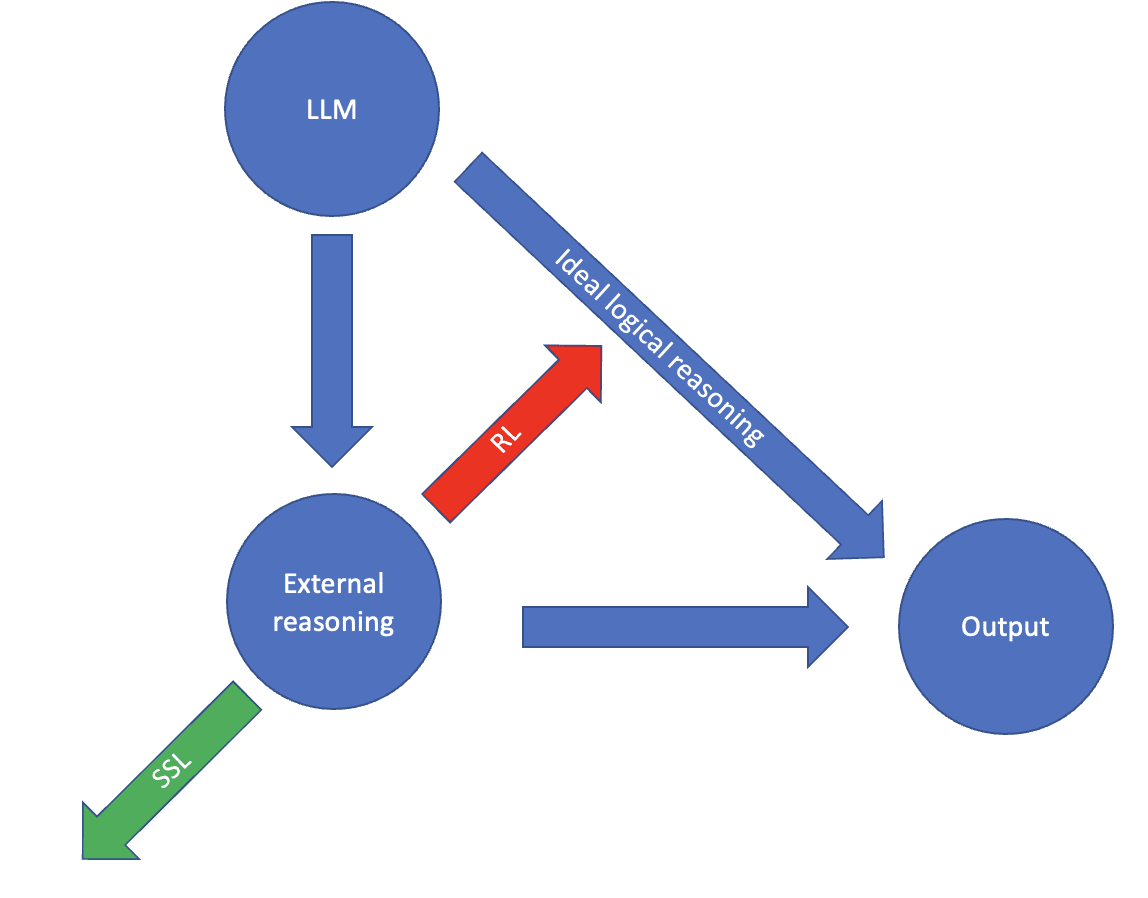
Opinion: This seems like it gets us a little further because we can now apply some RL, which might cause deception that is now catchable, so long as the RL doesn't push it so that the chain of thought itself is steganographic and hence not understandable to humans.
Also, catching the deception is only a small part of the battle: in worlds where deception is a big problem, we need to find ways to optimize against it, and this only gives us a small number of bits of optimization pressure.
Overall, this seems worth exploring more, I'm generally excited about more theoretical approaches on the above issues, as well as doing experiments about whether deception is a problem by default for chain of thought LLMs, which would give information on how likely deception is in general.
One problem (identified by John Wentworth) with this strategy is that the AI might cause large bad side effects, like wiping out humans without intent, simply because the AGI wants to use the earth for something else, and this won't trigger the oversight schemes. This seems like a problem, but this project still is clear progress towards solving alignment.
Eli’s opinion: Seems promising, though significantly more promising on shorter timelines where something like current LLMs scale to AGI.
Future of Humanity Institute (FHI)
FHI does a lot of work on non-technical AI safety, but as far as I know their primary technical agenda is the Causal incentives group (joint between FHI and DeepMind), who uses notions from causality to study incentives and their application to AI Safety. Recent work includes:
- Agent Incentives: A Causal Perspective, a paper which formalizes concepts such as the value of information and control incentives.
- Reward tampering problems and solutions in reinforcement learning: A causal influence diagram perspective, a paper which theoretically analyzes wireheading.
Opinion: I haven't read this research in depth, but I don't understand the focus on causality as necessarily the best way to do theory work on alignment.
Fund For Alignment Research (FAR)
Description copied from a comment by board member Adam Gleave
FAR's theory of change is to incubate new, scalable alignment research agendas. Right now I see a small range of agendas being pursued at scale (largely RLHF and interpretability), then a long tail of very diverse agendas being pursued by single individuals (mostly independent researchers or graduate students) or 2-3 person teams. I believe there's a lot of valuable ideas in this long tail that could be scaled, but this isn't happening due to a lack of institutional support. It makes sense that the major organisations want to focus on their own specific agendas -- there's a benefit to being focused! -- but it means a lot of valuable agendas are slipping through the cracks.
FAR's current approach to solving this problem is to build out a technical team (research engineers, junior research scientists, technical communication specialists) and provide support to a broad range of agendas pioneered by external research leads. Those that work, FAR will double down on and invest more in. This model has had a fair amount of demand already so there's product-market fit, but we still want to iterate and see if we can improve the model. For example, long-term FAR might want to bring some or all research leads in-house.
In terms of concrete agendas, an example of some of the things FAR is working on:
- Adversarial attacks against narrowly superhuman systems like AlphaGo.
- Language model benchmarks for value learning.
- The inverse scaling law prize.
You can read more about FAR in their launch post.
Eli's opinion: New, scalable alignment research agendas seem great to me in theory. I don't have strong opinions on the concrete agendas FAR is working on thus far; they seem interesting but hard to evaluate their usefulness without more deeply understanding the motivations (I skimmed the inverse scaling justification and felt a bit skeptical/unconvinced of direct usefulness, though it might be pretty useful for field-building).
MIRI
MIRI thinks technical alignment is really hard, and that we are very far from a solution. However, they think that policy solutions have even less hope. Generally, I think of their approach as supporting a bunch of independent researchers following their own directions, hoping that one of them will find some promise. They mostly buy into the security mindset: we need to know exactly (probably mathematically formally) what we are doing, or the massive optimization pressure will default in ruin.
Opinion: I wish that they would try harder to e.g. do more mentorship, do more specific 1-1 outreach, do more expansion, and try more different things. I also wish they would communicate more and use less metaphors: instead of a dialogue about rockets, explain why alignment needs math. Why this reference class instead of any other?
Now I'll list some of the individual directions that they are pursuing:
Communicate their view on alignment
Recently they've been trying to communicate their worldview, in particular, how incredibly doomy they are, perhaps in order to move other research efforts towards what they see as the hard problems.
Opinion: I am glad that they are trying to communicate this, because I think it caused a lot of people to think through their plans to deal with these difficulties. For example, I really liked the DeepMind alignment team's response to AGI ruin.
Eli’s opinion: I also really appreciate these posts. I generally think they are pointing at valuable considerations, difficulties, etc. even if I’m substantially more optimistic than them about the potential to avoid them (my p(doom) is ~45%).
Deception + Inner Alignment / Evan Hubinger
I don't know a lot about this. Read Evan's research agenda for more information.
It seems likely that deceptive agents are the default, so a key problem in alignment is to figure out how we can avoid deceptive alignment at every point in the training process. This seems to rely on being able to consistently exert optimization pressure against deception, which probably necessitates interpretability tools.
His plan to do this right now is acceptability verification: have some predicate that precludes deception, and then check your model for this predicate at every point in training.
One idea for this predicate is making sure that the agent is myopic, meaning that the AI only cares about the current timestep, so there is no incentive to deceive, because the benefits of deception happen only in the future. This is operationalized as “return the action that your model of HCH would return, if it received your inputs.”
Opinion: I think this is a big problem that it would be good to have more understanding of, and I think the primary bottleneck for this is understanding the inductive biases of neural networks.
I'm skeptical of the speed prior or myopia is the right way of getting around this. The speed prior seems to take a large capabilities hit because the speed prior is not predictive about the real world. Myopia seems weird to me overall because I don't know what we want to do with a myopic agent: I think a better frame on this is simulacra theory.
Eli’s opinion: I haven’t engaged much with this but I feel intuitively skeptical of the myopia stuff; Eliezer’s arguments in this thread seem right to me.
Agent Foundations / Scott Garrabrant and Abram Demski
They are working on fundamental problems like embeddedness, decision theory, logical counterfactuals, and more. A big advance was Cartesian Frames, a formal model of agency.
Opinion: This is wonderful work on deconfusing fundamental questions of agency. It doesn't seem like this will connect with the real world in time for AGI, but it seems like a great building block.
Infra-Bayesianism / Vanessa Kosoy
See Vanessa's research agenda for more detail.
If we don't know how to do something given unbounded compute, we are just confused about the thing. Going from thinking that chess was impossible for machines to understanding minimax was a really good step forward for designing chess AIs, even though minimax is completely intractable.
Thus, we should seek to figure out how alignment might look in theory, and then try to bridge the theory-practice gap by making our proposal ever more efficient.The first step along this path is to figure out a universal RL setting that we can place our formal agents in, and then prove regret bounds in.
A key problem in doing this is embeddedness. AIs can't have a perfect self model — this would be like imagining your ENTIRE brain, inside your brain. There are finite memory constraints. Infra-Bayesianism (IB) is essentially a theory of imprecise probability that lets you specify local / fuzzy things. IB allows agents to have abstract models of themselves, and thus works in an embedded setting.
Infra-Bayesian Physicalism (IBP) is an extension of this to RL. IBP allows us to
- Figure out what agents are running [by evaluating the counterfactual where the computation of the agent would output something different, and see if the physical universe is different].
- Give a program, classify it as an agent or a non agent, and then find its utility function.
Vanessa uses this formalism to describe PreDCA, an alignment proposal based on IBP. This proposal assumes that an agent is an IBP agent, meaning that it is an RL agent with fuzzy probability distributions (along with some other things). The general outline of this proposal is as follows:
- Find all of the agents that preceded the AI
- Discard all of these agents that are powerful / non-human like
- Find all of the utility functions in the remaining agents
- Use combination of all of these utilities as the agent's utility function
Vanessa models an AI as a model based RL system with a WM, a reward function, and a policy derived from the WM + reward. She claims that this avoids the sharp left turn. The generalization problems come from the world model, but this is dealt with by having an epistemology that doesn't contain bridge rules, and so the true world is the simplest explanation for the observed data.
It is open to show that this proposal also solves inner alignment, but there is some chance that it does.
This approach deviates from MIRI's plan, which is to focus on a narrow task to perform the pivotal act, and then add corrigibility. Vanessa instead tries to directly learn the user's preferences, and optimize those.
Opinion: Seems quite unlikely (<10%) for this type of theory to connect with deep learning in time (but this is based on median ~10 year timelines, I'm a lot more optimistic about this given more time). On the other hand, IB directly solves non-realizability, a core problem in embedded agency.
Also, IBP has some weird conclusions like the monotonicity principle: the AI's utility function has to be increasing in the number of computations running, even if these computations would involve the experience of suffering.
In the worlds the solution to alignment requires formally understanding AIs, Infra-Bayesianism seems like by far the most promising research direction that we know of. I am excited about doing more research in this direction, but also I'm excited for successor theories to IBP.
Visible Thoughts Project
This project is to create a language dataset where the characters think out loud a lot, so that when we train an advanced LLM on this dataset, it will be thinking out loud and hence interpretable.
Opinion: Seems reasonable enough.
Jacob Steinhardt
Jacob Steinhardt is a professor at UC Berkeley who works on conceptual alignment. He seems to have a broad array of research interests, but with some focus on robustness to distribution shift.
A technical paper he wrote is Certified defenses against adversarial examples: a technique for creating robust networks in the sense that an adversary has to shift the input image by some constant in order to cause a certain drop in test performance. He's also researched the mechanics of distribution shift, and found that different distribution shifts induce different robustness performance.
He's published several technical overviews including AI Alignment Research Overview and Concrete problems in AI safety, and created an AI forecasting competition.
Opinion: I think it is very valuable to develop a better understanding of distribution shifts, because I view that at the heart of the difficulty of alignment.
OpenAI
The safety team at OpenAI's plan is to build a MVP aligned AGI that can help us solve the full alignment problem.
They want to do this with Reinforcement Learning from Human Feedback (RLHF): get feedback from humans about what is good, i.e. give reward to AI's based on the human feedback. Problem: what if the AI makes gigabrain 5D chess moves that humans don't understand, so can't evaluate. Jan Leike, the director of the safety team, views this (the informed oversight problem) as the core difficulty of alignment. Their proposed solution: an AI assisted oversight scheme, with a recursive hierarchy of AIs bottoming out at humans. They are working on experimenting with this approach by trying to get current day AIs to do useful supporting work such as summarizing books and criticizing itself.
OpenAI also published GPT-3, and are continuing to push LLM capabilities, with GPT-4 expected to be released at some point soon.
See also: Common misconceptions about OpenAI and Our approach to alignment research.
Opinion: This approach focuses almost entirely on outer alignment, and so I'm not sure how this is planning to get around deception. In the unlikely world where deception isn't the default / inner alignment happens by default, this alignment plan seems and complicated and therefore vulnerable to the godzilla problem. I also think it relies on very slow takeoff speeds: the misaligned AGI has to help us design a successor aligned AGI, and this only works when the AGI doesn't recursively self improve to superintelligence.[5]
Overall, the dominant effect of OpenAI pushes is that they advance capabilities, which seems really bad because it shortens AGI timelines.
Eli’s opinion: Similar to Thomas. I’m generally excited about trying to automate alignment research, but relatively more positive on Conjecture’s approach since it aims to use non-agentic systems.
Ought
Ought aims to automate and scale open-ended reasoning through Elicit, an AI research assistant. Ought focuses on advancing process-based systems rather than outcome-based ones, which they believe to be both beneficial for improving reasoning in the short term and alignment in the long term. Here they argue that in the long run improving reasoning and alignment converge.
So Ought’s impact on AI alignment has 2 components: (a) improved reasoning of AI governance & alignment researchers, particularly on long-horizon tasks and (b) pushing supervision of process rather than outcomes, which reduces the optimization pressure on imperfect proxy objectives leading to “safety by construction”. Ought argues that the race between process and outcome-based systems is particularly important because both states may be an attractor.
Eli’s opinion (Eli used to work at Ought): I am fairly optimistic about (a), the general strategy of applying AI in a differentially helpful way for alignment via e.g. speeding up technical alignment research or improving evaluations of alignment-aimed policies. Current Elicit is too broadly advertised to all researchers for my taste; I’m not sure whether generally speeding up science is good or bad. I’m excited about a version of Elicit that is more narrowly focused on helping with alignment (and perhaps longtermist research more generally), which I hear may be in the works.
I’m less optimistic about (b) pushing process-based systems, it seems like a very conjunctive theory of change to me. It needs to go something like: process-based systems are competitive with end-to-end training for AGI (which may be unlikely, see e.g. Rohin’s opinion here; and my intuition is that HCH doesn’t work), process-based systems are substantially more aligned than end-to-end training while being as capable (feels unlikely to me; even if it helps a bit it probably needs to help a lot to make the difference between catastrophe and not), and Ought either builds AGI or strongly influences the organization that builds AGI. Off the cuff I’d give something like 10%, 3%, 1% for these respectively (conditioned on the previous premises) which multiplies to .003%; this might be fine given the stakes (it’s estimated to be worth $17-$167M via .01% Fund proposal assuming AI x-risk is 50%) but it doesn’t feel like one of the most promising approaches.
Redwood Research
Adversarial training
The following diagram describing an adversarial oversight scheme to do for aligning an RL agent:
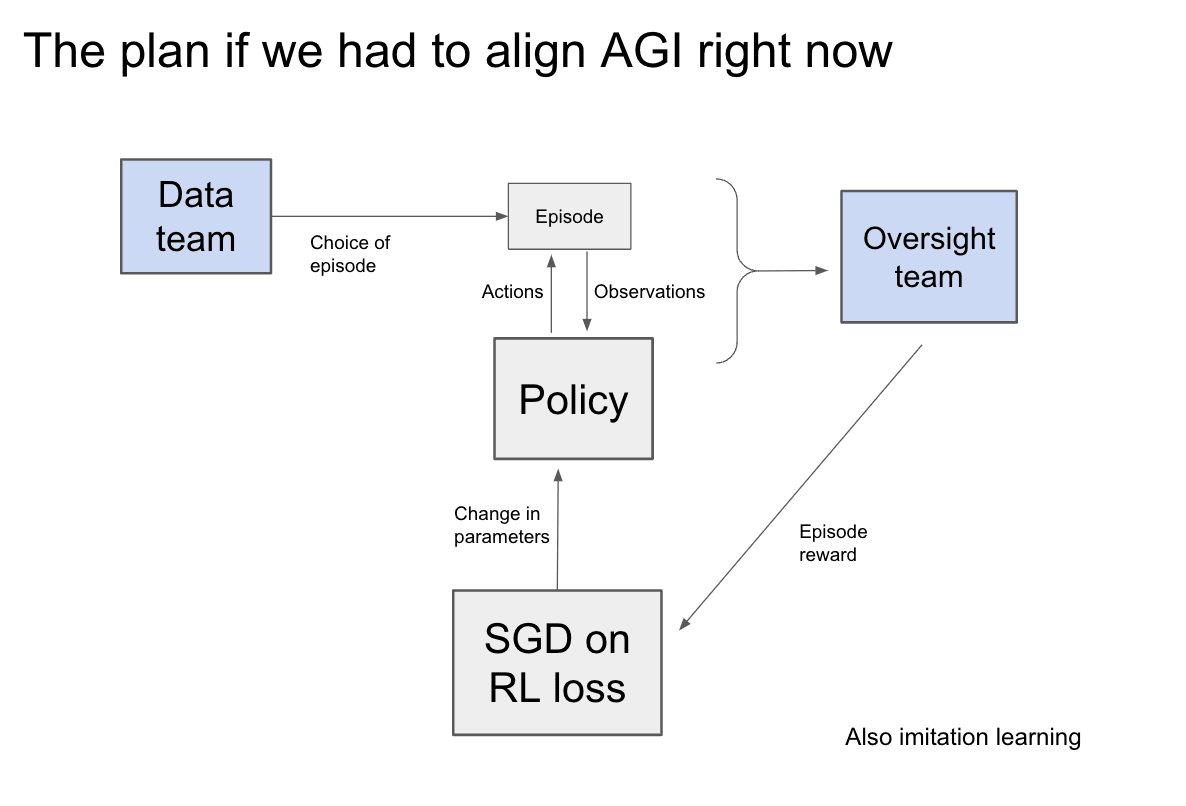
Motivation: The point of this approach is to create extremely reliable AI where it will never engage in certain types of behavior, for example, killing all humans, or deceiving its creators. A practice problem is to get any kind of behavior extremely reliably out of current day LLMs. The way Redwood operationalized this is by trying to train an LLM to have the property that they finish the prompt such that no humans get hurt (technically slightly weaker than this — only the AI believes no one gets hurt).
Opinion: This seems like a reasonable applied alignment project because it is a technique that could solve alignment for worlds in which alignment is pretty easy: if we just train the model to not hurt people, not take over the world, etc, then it'll just work. More specifically, we use either humans or amplified humans to get the description of the bad thing, then train a model that can very reliably simulate this description (and is much quicker to query than a human). Then, when we train the AI agent, we use this model to make sure that the AI never does the bad thing.
My worry with adversarial training is that it might just be pushing around the inner misalignment somewhere else in the model. In the real case there are instrumental incentives for power seeking to push against this technique, so even if the failure rate is 1 in a trillion, there will be strong optimization pressure, and a large distribution shift that will break this learned invariant.
LLM interpretability
Redwood is also doing some work on interpretability tools, though as far as I know they have not published a writeup of their interpretability results. As of April, they were focused on getting a complete understanding of nontrivial behaviors of relatively small models. They have released a website for visualizing transformers. Apart from the standard benefits of interpretability, one possibility is that this might be helpful for solving ELK.
Opinion: Excited to see the results from this.
Sam Bowman
Sam runs a lab at NYU. He is on sabbatical working at Anthropic for the 2022-2023 academic year, and has already been collaborating with them.
Projects include language model alignment by creating datasets for evaluating language models, as well as inductive biases of LLMs.
He is involved in running the inverse scaling prize in collaboration with FAR, a contest for finding tasks where larger language models perform worse than smaller language models. The idea of this is to understand how LLMs are misaligned, and find techniques for uncovering this misalignment.
Opinion: I don't understand this research very well, so I can't comment.
Selection Theorems / John Wentworth
John's plan is:
Step 1: sort out our fundamental confusions about agency
Step 2: ambitious value learning (i.e. build an AI which correctly learns human values and optimizes for them)
Step 3: …
Step 4: profit!
… and do all that before AGI kills us all.
He is working on step 1: figuring out what the heck is going on with agency. His current approach is based on selection theorems: try to figure out what types of agents are selected for in a broad range of environments. Examples of selection pressures include: evolution, SGD, and markets. This is an approach to agent foundations that comes from the opposite direction as MIRI: it's more about observing existing structures (whether they be mathematical or real things in the world like markets or e coli), whereas MIRI is trying to write out some desiderata and then finding mathematical notions that satisfy those desiderata.
Two key properties that might be selected for are modularity and abstractions.
Abstractions are higher level things that people tend to use to describe things. Like "Tree" and "Chair" and "Person". These are all vague categories that contain lots of different things, but are really useful for narrowing down things. Humans tend to use really similar abstractions, even across different cultures / societies. The Natural Abstraction Hypothesis (NAH) states that a wide variety of cognitive architectures will tend to use similar abstractions to reason about the world. This might be helpful for alignment because we could say things like "person" without having to rigorously and precisely say exactly what we mean by person.
The NAH seems very plausibly true for physical objects in the world, and so it might be true for the inputs to human values. If so, it would be really helpful for AI alignment because understanding this would amount to a solution to the ontology identification problem: we can understand when environments induce certain abstractions, and so we can design this so that the network has the same abstractions as humans.
Opinion: I think that understanding abstraction seems like a promising research direction, both for current neural networks, as well as agent foundations problems.
I also think that the learned abstractions are highly dependent on the environment, and that the training environment for an AGI might look very different than the the learning environment that humans follow.
A very strong form of the Natural Abstraction Hypothesis might even hold for the goals of agents, for example, maybe cooperation is universally selected for by iterated prisoners dilemmas.
Modularity: In pretty much any selection environment, we see lots of obvious modularity. Biological species have cells and organs and limbs. Companies have departments. We might expect neural networks to be similar, but it is really hard to find modules in neural networks. We need to find the right lens to look through to find this modularity in neural networks. Aiming at this can lead us to really good interpretability.
Opinion: Looking for modules / frames on modularity in neural networks seems like a promising way to get scalable interpretability, so I'm excited about this.
Team Shard
Humans care about things! The reward circuitry in our brain reliably causes us to care about specific things. Let's create a mechanistic model of how the brain aligns humans, and then we can use this to do AI alignment.
One perspective that Shard theory has added is that we shouldn't think of the solution to alignment as:
- Find an outer objective that is fine to optimize arbitrarily strongly
- Find a way of making sure that the inner objective of an ML system equals the outer objective.
Shard theory argues that instead we should focus on finding outer objectives that reliably give certain inner values into system and should be thought of as more of a teacher of the values we want to instill as opposed to the values themselves. Reward is not the optimization target — instead, it is more like that which reinforces. People sometimes refer to inner aligning an RL agent with respect to the reward signal, but this doesn't actually make sense. (As pointed out in the comments this is not a new insight, but it was for me phrased a lot more clearly in terms of Shard theory).
Humans have different values than the reward circuitry in our brain being maximized, but they are still pointed reliably. These underlying values cause us to not wirehead with respect to the outer optimizer of reward.
Shard Theory points at the beginning of a mechanistic story for how inner values are selected for by outer optimization pressures. The current plan is to figure out how RL induces inner values into learned agents, and then figure out how to instill human values into powerful AI models (probably chain of thought LLMs, because these are the most intelligent models right now). Then, use these partially aligned models to solve the full alignment problem. Shard theory also proposes a subagent theory of mind.
This has some similarities to Brain-like AGI Safety, and has drawn on some research from this post, such as the mechanics of the human reward circuitry as well as the brain being mostly randomly initialized at birth.
Opinion: This is promising so far, deserves a lot more work to be done on it to try to find a reliable way to implant certain inner values into trained systems. I view Shard Theory as a useful frame for alignment already even if it doesn’t go anywhere else.
Eli’s opinion: I’m not sure I agree much with the core claims of Shard Theory, but the research that I’ve seen actually being proposed based on it generally seems useful.
Truthful AI / Owain Evans and Owen Cotton-Barratt
Truthful AI is a research direction to get models to avoid lying to us. This involves developing 1) clear truthfulness standards e.g. avoiding “negligent falsehoods”, 2) institutions to enforce standards, and 3) truthful AI systems e.g. via curated datasets and human interaction.
See also Truthful LMs as a warm-up for aligned AGI and TruthfulQA: Measuring How Models Mimic Human Falsehoods.
Edit for clarity: According to Owen, TruthfulAI is not trying to solve the hard bit of the alignment problem. Instead, the goal of this approach is to improve society to generally be more able to solve hard challenges such as alignment.
Opinion: It seems like the root problem is that deception is an instrumental subgoal of powerful inner misaligned AGIs, so we need to fix that in order to solve alignment. I'm confused about how this helps society solve alignment, but that is probably mostly because I don't know much about this.
Eli’s opinion: This seems like a pretty indirect way to tackle alignment of powerful AIs; I think it’s mostly promising insofar as it helps us more robustly automate technical and strategy alignment research.
Other Organizations
Though we have tried to be exhaustive, there are certainly many people working on technical AI alignment not included in this overview. While these groups might produce great research, we either 1) didn't know enough about it to summarize or 2) weren’t aware that it was aimed at reducing x-risk from AI.
Below is a list of some of these, though we probably missed some here. Please feel free to add comments and I will add others.
- Future of Life Institute (FLI) (Though they seem to mostly give out grants)
- Many independent researchers.
- A number of academics:
- *ERIs:
- Principles of Intelligent Behavior in Biological and Social Systems (PIBSS)
- Alignment of Complex Systems Research Group
Appendix
Visualizing Differences
Automating alignment and alignment difficulty
Much of the difference between approaches comes down to disagreements on two axes: how promising it is to automate alignment vs. solve it directly and how difficult alignment is (~p(doom)). We’ll chart our impression of where orgs and approaches stand on these axes, based on something like the median view of org/approach leadership. We leave out orgs/approaches that we have no idea about, but err on the side of guessing if we have some intuitions (feel free to correct us!).
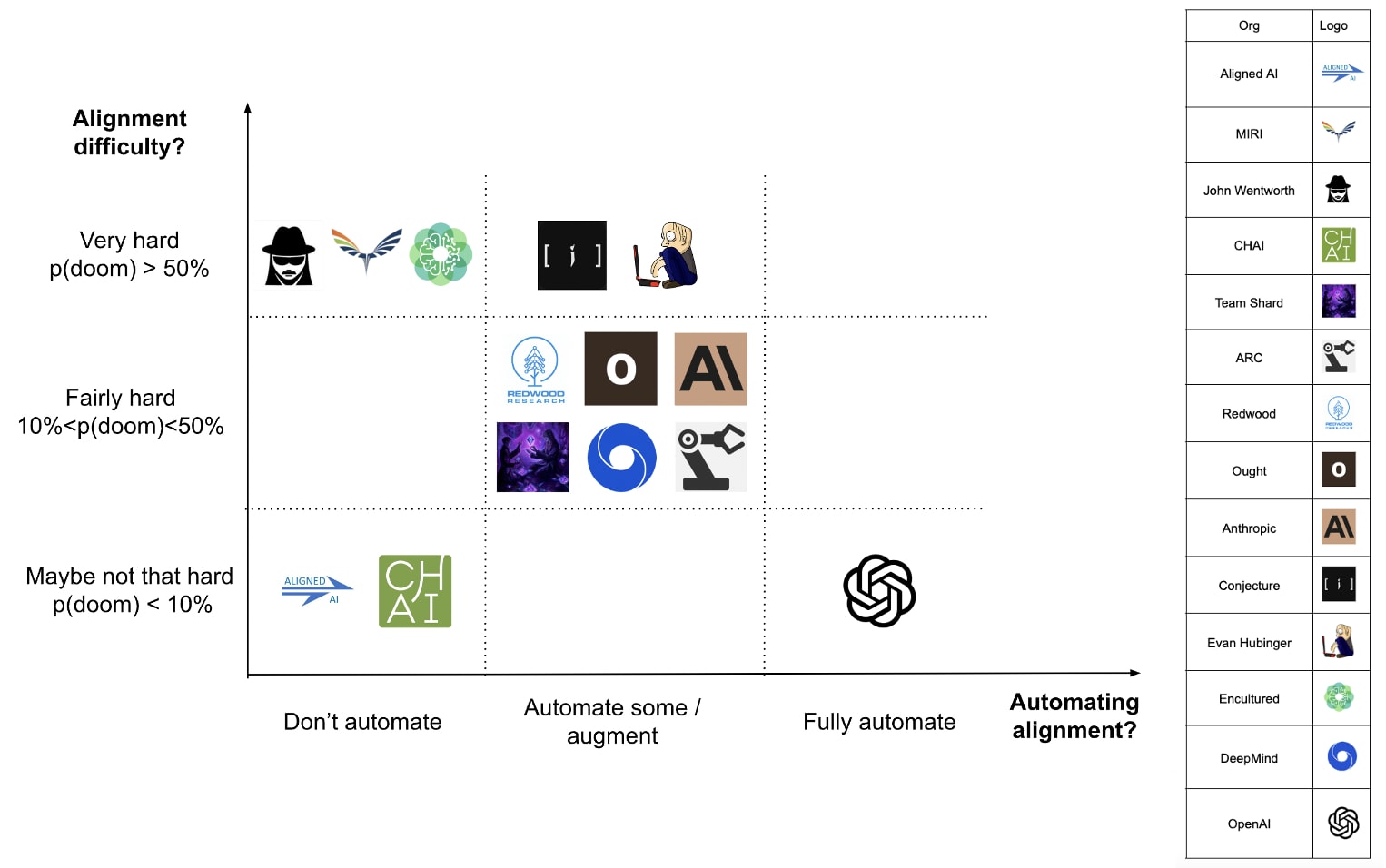
Conceptual vs. applied
Another important axis distinguishing approaches is conceptual (i.e. thinking about how to align powerful AI) vs. applied (i.e. experimenting with AI systems to learn about how to align powerful AI).
| Type of approach | Mostly conceptual | Mixed | Mostly applied |
| Organization | MIRI, John Wentworth, ARC | Team Shard, CHAI, DeepMind | Conjecture, Encultured, OpenAI, Anthropic, Redwood, Ought |
Thomas’s Alignment Big Picture
This is a summary of my overall picture of the AGI landscape, which is a high level picture of the generator of most my opinions above.
I buy most of the arguments given in Without specific countermeasures, the easiest path to transformative AI likely leads to AI takeover and AGI Ruin, A List of Lethalities.
To make AGI go well, many organizations with economic and social incentives to make AGI before alignment is solved must avoid doing so. Moreover, the majority of the AI community does not take x-risk from AGI seriously. Whatever it is that moves us from our current trajectory to a safe-from-AGI-world, in my eyes, would count as a pivotal act[6] — an act that makes a large positive impact on the world a billion years in the future. A pivotal act might also consist of lots of smaller actions that together make a difference in the long term, then all these acts together could constitute a pivotal act.
Performing a pivotal act without AI is likely really hard, but could look something like transforming the world's governments into Dath Ilan. If a non-AI pivotal act is feasible, I think it is probably best for us to cease all AIS research, and then just work towards performing that pivotal act. AIS research usually contributes at least something to capabilities, and so stopping that buys more time (so long as the AIS researchers don't start doing capabilities directly instead).
The other option is an AI-assisted pivotal act. This pivotal act might look like making a very aligned AI recursively self improve, and implement CEV. It might be more like the MIRI example of melting GPUs to prevent further AI progress and then turning itself off, but this isn't meant to be a concrete plan. MIRI seems to think that this is the path with the highest odds of success — see the strategic background section here.
The alignment tax is the amount of extra effort it will take for an AI to be aligned. This includes both research effort as well as compute and engineering time. I think it is quite likely (~80%) that part of the alignment tax for the first safe AGI requires >1 year of development time.
Pulling off an AGI-assisted pivotal act requires aligning the AGI you are using, meaning that:
- The alignment tax to be low enough for an actor to pay
- That the actor implementing the first AGI pays this alignment tax
- 1 and 2 need to happen before the world is destroyed.
Technical alignment work is primarily focused on 1. Some organizations are also trying to be large enough and ahead to pay the alignment tax for an AGI.
My model of EA and AI Safety is that it is expanding exponentially, and that this trend will likely continue until AGI. This leads me to think that the majority of the AIS work will be done right before AGI. It also means that timelines are crucial — pushing timelines back is very important. This is why I am usually not excited about work that improves capabilities even if it does more to help safety.[7]
In the world where we have to align an AGI, solving the technical alignment problem seems like a big bottleneck, but cooperation to slow down timelines is necessary in both worlds.
- ^
We may revise the document based on corrections in the comments or future announcements, but don't promise anything. Others are welcome to create future versions or submit summaries of their own approaches for us to edit in. We will note the time it was last edited when we edit things. (ETA: most recent update: 10/9/2022)
- ^
In this chart, the ? denotes more uncertainty if this is a correct description
- ^
I would appreciate someone giving more information on DeepMind's approach to alignment.Update: Rohin has given a helpful summary in a comment. - ^
Technically, they just need to span the set of extrapolations, so that the correct extrapolation is just a linear combination of the found classifiers.
- ^
Hold on, how come you are excited about Conjecture automating alignment research but not OpenAI?
Answer: I see a categorical distinction between trying to align agentic and oracle AIs. Conjecture is trying only for oracle LLMs, trained without any RL pressure giving them goals, which seems way safer. OpenAI doing recursive reward modeling / IDA type schemes involves creating agentic AGIs and therefore faces also a lot more alignment issues like convergent instrumental goals, power seeking, goodharting, inner alignment failure, etc.I think inner alignment can be a problem with LLMs trained purely in a self-supervised fashion (e.g., simulacra becoming aware of their surroundings), but I anticipate it to only be a problem with further capabilities. I think RL trained GPT-6 is a lot more likely to be an x-risk than GPT-6 trained only to do text prediction.
- ^
To be clear: I am very against proposals for violent pivotal acts that are sometimes brought up, such as destroying other AI labs on the verge of creating a misaligned AGI. This seems bad because 1) violence is bad and isn't dignified. 2) it seems like this intention would make it much harder to coordinate. 3) Setting an AGI loose to pull off a violent pivotal act could incredibly easily disempower humanity: you are intentionally letting the AGI destructively take over.
- ^
Some cruxes that would change this conclusion are if we don't get prosaic AGI or if solving alignment takes a lot of serial thought, e.g. work that needs to be done by 1 researcher over 10 years, and can't be solved by 10 researchers working for 1 year.