
Biology-Inspired AGI Timelines: The Trick That Never Works
56CarlShulman
6Vanessa Kosoy
5CarlShulman
12Vanessa Kosoy
11Mark Xu
3Vanessa Kosoy
5gwern
4Vanessa Kosoy
0Eliezer Yudkowsky
7paulfchristiano
7Daniel Kokotajlo
1Mark Xu
2Vanessa Kosoy
2Daniel Kokotajlo
2Vanessa Kosoy
2Daniel Kokotajlo
5Charlie Steiner
1CarlShulman
5Charlie Steiner
7paulfchristiano
1Charlie Steiner
2adamShimi
31Aryeh Englander
30Zvi
1[comment deleted]
27TurnTrout
14Kaj_Sotala
8Rob Bensinger
11Aryeh Englander
4Matthew Barnett
5Rafael Harth
5Rob Bensinger
26Grant Demaree
2Sammy Martin
25davidad
38Rob Bensinger
3adamShimi
21Richard_Ngo
15davidad
13paulfchristiano
6habryka
6paulfchristiano
11So8res
9davidad
1ESRogs
8Daniel Kokotajlo
4Ajeya Cotra
3Daniel Kokotajlo
7Ben Pace
7Daniel Kokotajlo
5adamShimi
2Daniel Kokotajlo
2adamShimi
4Daniel Kokotajlo
2adamShimi
7Adele Lopez
5Rob Bensinger
5Rob Bensinger
13Eliezer Yudkowsky
4Ruby
4Rafael Harth
4TurnTrout
3Daniel Kokotajlo
11Matthew Barnett
5Charlie Steiner
4adamShimi
5Daniel Kokotajlo
4adamShimi
2adamShimi
2Ben Pace
2Ben Pace
2Lukas Finnveden
2romeostevensit
1Lukas Finnveden
1jacob_cannell
16Adele Lopez
9Eliezer Yudkowsky
2Charlie Steiner
New Comment
Progress in AI has largely been a function of increasing compute, human software research efforts, and serial time/steps. Throwing more compute at researchers has improved performance both directly and indirectly (e.g. by enabling more experiments, refining evaluation functions in chess, training neural networks, or making algorithms that work best with large compute more attractive).
Historically compute has grown by many orders of magnitude, while human labor applied to AI and supporting software by only a few. And on plausible decompositions of progress (allowing for adjustment of software to current hardware and vice versa), hardware growth accounts for more of the progress over time than human labor input growth.
So if you're going to use an AI production function for tech forecasting based on inputs (which do relatively OK by the standards tech forecasting), it's best to use all of compute, labor, and time, but it makes sense for compute to have pride of place and take in more modeling effort and attention, since it's the biggest source of change (particularly when including software gains downstream of hardware technology and expenditures).
Thinking about hardware h...
Historically compute has grown by many orders of magnitude, while human labor applied to AI and supporting software by only a few. And on plausible decompositions of progress (allowing for adjustment of software to current hardware and vice versa), hardware growth accounts for more of the progress over time than human labor input growth.
So if you're going to use an AI production function for tech forecasting based on inputs (which do relatively OK by the standards tech forecasting), it's best to use all of compute, labor, and time, but it makes sense for compute to have pride of place and take in more modeling effort and attention, since it's the biggest source of change (particularly when including software gains downstream of hardware technology and expenditures).
I don't understand the logical leap from "human labor applied to AI didn't grow much" to "we can ignore human labor". The amount of labor invested in AI research is related to the the time derivative of progress on the algorithms axis. Labor held constant is not the same as algorithms held constant. So, we are still talking about the problem of predicting when AI-capability(algorithms(t),compute(t)) reaches human...
5
A perfectly correlated time series of compute and labor would not let us say which had the larger marginal contribution, but we have resources to get at that, which I was referring to with 'plausible decompositions.' This includes experiments with old and new software and hardware, like the chess ones Paul recently commissioned, and studies by AI Impacts, OpenAI, and Neil Thompson. There are AI scaling experiments, and observations of the results of shocks like the end of Dennard scaling, the availability of GPGPU computing, and Besiroglu's data on the relative predictive power of computer and labor in individual papers and subfields.
In different ways those tend to put hardware as driving more log improvement than software (with both contributing), particularly if we consider software innovations downstream of hardware changes.
I will have to look at these studies in detail in order to understand, but I'm confused how can this pass some obvious tests. For example, do you claim that alpha-beta pruning can match AlphaGo given some not-crazy advantage in compute? Do you claim that SVMs can do SOTA image classification with not-crazy advantage in compute (or with any amount of compute with the same training data)? Can Eliza-style chatbots compete with GPT3 however we scale them up?
My model is something like:
- For any given algorithm, e.g. SVMs, AlphaGo, alpha-beta pruning, convnets, etc., there is an "effective compute regime" where dumping more compute makes them better. If you go above this regime, you get steep diminishing marginal returns.
- In the (relatively small) regimes of old algorithms, new algorithms and old algorithms perform similarly. E.g. with small amounts of compute, using AlphaGo instead of alpha-beta pruning doesn't get you that much better performance than like an OOM of compute (I have no idea if this is true, example is more because it conveys the general gist).
- One of the main way that modern algorithms are better is that they have much large effective compute regimes. The other main way is enabling more effective conversion of compute to performance.
- Therefore, one of primary impact of new algorithms is to enable performance to continue scaling with compute the same way it did when you had smaller amounts.
In this model, it makes sense to think of the "contribution" of new algorithms as the factor they enable more efficient conversion of compute to performance and count the increased performance because the new algorithms can absorb m...
3
Hmm... Interesting. So, this model says that algorithmic innovation is so fast that it is not much of a bottleneck: we always manage to find the best algorithm for given compute relatively quickly after this compute becomes available. Moreover, there is some smooth relation between compute and performance assuming the best algorithm for this level of compute. [EDIT: The latter part seems really suspicious though, why would this relation persist across very different algorithms?] Or at least this is true is "best algorithm" is interpreted to mean "best algorithm out of some wide class of algorithms s.t. we never or almost never managed to discover any algorithm outside of this class".
This can justify biological anchors as upper bounds[1]: if biology is operating using the best algorithm then we will match its performance when we reach the same level of compute, whereas if biology is operating using a suboptimal algorithm then we will match its performance earlier. However, how do we define the compute used by biology? Moravec's estimate is already in the past and there's still no human-level AI. Then there is the "lifetime" anchor from Cotra's report which predicts a very short timeline. Finally, there is the "evolution" anchor which predicts a relatively long timeline.
However, in Cotra's report most of the weight is assigned to the "neural net" anchors which talk about the compute for training an ANN of brain size using modern algorithms (plus there is the "genome" anchor in which the ANN is genome-sized). This is something that I don't see how to justify using Mark's model. On Mark's model, modern algorithms might very well hit diminishing returns soon, in which case we will switch to different algorithms which might have a completely different compute(parameter count) function.
----------------------------------------
1. Assuming evolution also cannot discover algorithms outside our class of discoverable algorithms. ↩︎
What Moravec says is merely that $1k human-level compute will become available in the '2020s', and offers several different trendline extrapolations: only the most aggressive puts us at cheap human-level compute in 2020/2021 (note the units on his graph are in decades). On the other extrapolations, we don't hit cheap human-compute until the end of the decade. He also doesn't commit to how long it takes to turn compute into powerful systems, it's more of a pre-requisite: only once the compute is available can R&D really start, same way that DL didn't start instantly in 2010 when various levels of compute/$ were hit. Seeds take time to sprout, to use his metaphor.
4
We already know how much compute we have, so we don't need Moravec's projections for this? If Yudkowsky described Moravec's analysis correctly, then Moravec's threshold was crossed in 2008. Or, by "other extrapolations" you mean other estimates of human brain compute? Cotra's analysis is much more recent and IIUC she puts the "lifetime anchor" (a more conservative approach than Moravec's) at about one order of magnitude above the biggest models currently used.
Now, the seeds take time to sprout, but according to Mark's model this time is quite short. So, it seems like this line of reasoning produces a timeline significantly shorter than the Plattian 30 years.
0
As much as Moravec-1988 and Moravec-1998 sound like they should be basically the same people, a decade passed between them, and I'd like to note that Moravec may legit have been making an updated version of his wrong argument in 1998 compared to 1988 after he had a chance to watch 10 more years pass and make his earlier prediction look less likely.
I think this is uncharitable and most likely based on a misreading of Moravec. (And generally with gwern on this one.)
As far as I can tell, the source for your attribution of this "prediction" is:
If this rate of improvement were to continue into the next century, the 10 teraops required for a humanlike computer would be available in a $10 million supercomputer before 2010 and in a $1,000 personal computer by 2030."
As far as I could tell it sounds from the surrounding text like his "prediction" for transformative impacts from AI was something like "between 2010 and 2030" with broad error bars.
Adding to what Paul said: jacob_cannell points to this comment which claims that in Mind Children Moravec predicted human-level AGI in 2028.
Moravec, "Mind Children", page 68: "Human equivalence in 40 years". There he is actually talking about human-level intelligent machines arriving by 2028 - not just the hardware you would theoretically require to build one if you had the ten million dollars to spend on it.
I just went and skimmed Mind Children. He's predicting human-equivalent computational power on a personal computer in 40 years. He seems to say that humans will within 50 years be surpassed in every important way by machines (page 70, below), but I haven't found a more precise or short-term statement yet.
The robot who will work alongside us in half a century will have some interesting properties. Its reasoning abilities should be astonishingly better than a human's—even today's puny systems are much better in some areas. But its perceptual and motor abilities will probably be comparable to ours. Most interestingly, this artificial person will be highly changeable, both as an individual and from one of its generations to the next. But solitary, toiling robots, however compet...
1
The way that you would think about NN anchors in my model (caveat that this isn't my whole model):
* You have some distribution over 2020-FLOPS-equivalent that TAI needs.
* Algorithmic progress means that 20XX-FLOPS convert to 2020-FLOPS-equivalent at some 1:N ratio.
* The function from 20XX to the 1:N ratio is relatively predictable, e.g. a "smooth" exponential with respect to time.
* Therefore, even though current algorithms will hit DMR, the transition to the next algorithm that has less DMR is also predictably going to be some constant ratio better at converting current-FLOPS to 2020-FLOPS-equivalent.
E.g. in (some smallish) parts of my view, you take observations like "AGI will use compute more efficiently than human brains" and can ask questions like "but how much is the efficiency of compute->cognition increasing over time?" and draw that graph and try to extrapolate. Of course, the main trouble is in trying to estimate the original distribution of 2020-FLOPS-equivalent needed for TAI, which might go astray in the way a 1950-watt-equivalent needed for TAI will go astray.
2
I don't understand this.
* What is the meaning of "2020-FLOPS-equivalent that TAI needs"? Plausibly you can't build TAI with 2020 algorithms without some truly astronomical amount of FLOPs.
* What is the meaning of "20XX-FLOPS convert to 2020-FLOPS-equivalent"? If 2020 algorithms hit DMR, you can't match a 20XX algorithm with a 2020 algorithm without some truly astronomical amount of FLOPs.
Maybe you're talking about extrapolating the compute-performance curve, assuming that it stays stable across algorithmic paradigms (although, why would it??) However, in this case, how do you quantify the performance required for TAI? Do we have "real life elo" for modern algorithms that we can compare to human "real life elo"? Even if we did, this is not what Cotra is doing with her "neural anchor".
2
I think 10^35 would probably be enough. This post gives some intuition as to why, and also goes into more detail about what 2020-flops-equivalent-that-TAI-needs means. If you want even more detail + rigor, see Ajeya's report. If you think it's very unlikely that 10^35 would be enough, I'd love to hear more about why -- what are the blockers? Why would OmegaStar, SkunkWorks, etc. described in the post (and all the easily-accessible variants thereof) fail to be transformative? (Also, same questions for APS-AI or AI-PONR instead of TAI, since I don't really care about TAI)
2
I didn't ask how much, I asked what does it even mean. I think I understand the principles of Cotra's report. What I don't understand is why should we believe the "neural anchor" when (i) modern algorithms applied to a brain-sized ANN might not produce brain-performance and (ii) the compute cost of future algorithms might behave completely differently. (i.e. I don't understand how Carl's and Mark's arguments in this thread protect the neural anchor from Yudkowsky's criticism.)
2
These are three separate things:
(a) What is the meaning of "2020-FLOPS-equivalent that TAI needs?"
(b) Can you build TAI with 2020 algorithms without some truly astronomical amount of FLOPs?
(c) Why should we believe the "neural anchor?"
(a) is answered roughly in my linked post and in much more detail and rigor in Ajeya's doc.
(b) depends on what you mean by truly astronomical; I think it would probably be doable for 10^35, Ajeya thinks 50% chance.
For (c), I actually don't think we should put that much weight on the "neural anchor," and I don't think Ajeya's framework requires that we do (although, it's true, most of her anchors do center on this human-brain-sized ANN scenario which indeed I think we shouldn't put so much weight on.) That said, I think it's a reasonable anchor to use, even if it's not where all of our weight should go. This post gives some of my intuitions about this. Of course Ajeya's report says a lot more.
5
The chess link maybe should go to hippke's work. What you can see there is that a fixed chess algorithm takes an exponentially growing amount of compute and transforms it into logarithmically-growing Elo. Similar behavior features in recent pessimistic predictions of deep learning's future trajectory.
If general navigation of the real world suffers from this same logarithmic-or-worse penalty when translating hardware into performance metrics, then (perhaps surprisingly) we can't conclude that hardware is the dominant driver of progress by noticing that the cost of compute is dropping rapidly.
1
But new algorithms also don't work well on old hardware. That's evidence in favor of Paul's view that much software work is adapting to exploit new hardware scales.
5
Which examples are you thinking of? Modern Stockfish outperformed historical chess engines even when using the same resources, until far enough in the past that computers didn't have enough RAM to load it.
I definitely agree with your original-comment points about the general informativeness of hardware, and absolutely software is adapting to fit our current hardware. But this can all be true even if advances in software can make more than 20 orders of magnitude difference in what hardware is needed for AGI, and are much less predictable than advances in hardware rather than being adaptations in lockstep with it.
Here are the graphs from Hippke (he or I should publish summary at some point, sorry).
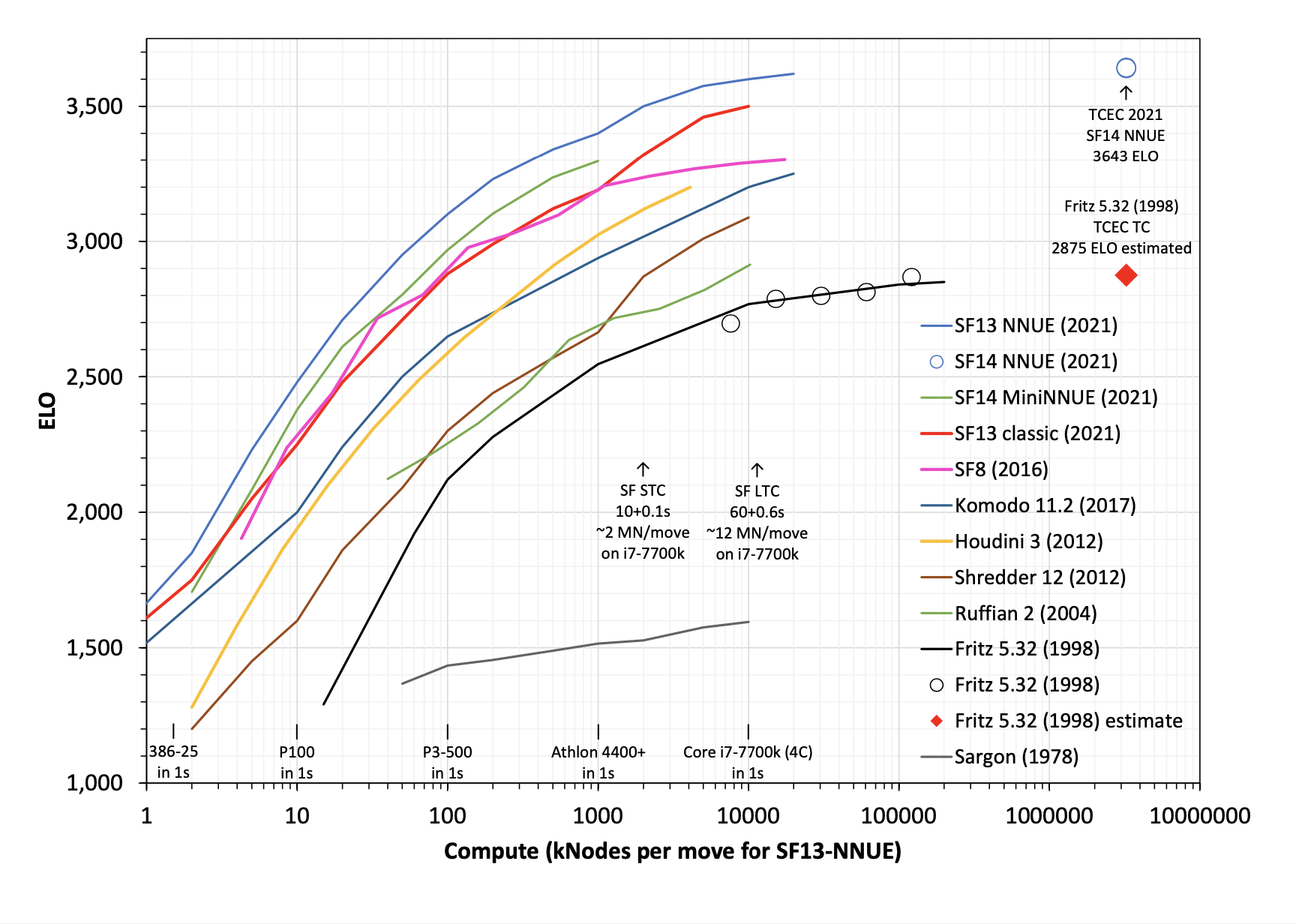
I wanted to compare Fritz (which won WCCC in 1995) to a modern engine to understand the effects of hardware and software performance. I think the time controls for that tournament are similar to SF STC I think. I wanted to compare to SF8 rather than one of the NNUE engines to isolate out the effect of compute at development time and just look at test-time compute.
So having modern algorithms would have let you win WCCC while spending about 50x less on compute than the winner. Having modern computer hardware would have let you win WCCC spending way more than 1000x less on compute than the winner. Measured this way software progress seems to be several times less important than hardware progress despite much faster scale-up of investment in software.
But instead of asking "how well does hardware/software progress help you get to 1995 performance?" you could ask "how well does hardware/software progress get you to 2015 performance?" and on that metric it looks like software progress is way more important because you basically just can't scale old algorithms up to modern performance.
The relevant measure...
1
Yeah, the nonlinearity means it's hard to know what question to ask.
If we just eyeball the graph and say that the Elo is log(log(compute)) + time (I'm totally ignoring constants here), and we assume that compute = et so that conveniently log(compute)=t, thenddtElo=1t+1 . The first term is from compute and the second from software. And so our history is totally not scale-free! There's some natural timescale set by t=1, before which chess progress was dominated by compute and after which chess progress will be (was?) dominated by software.
Though maybe I shouldn't spend so much time guessing at the phenomenology of chess, and different problems will have different scaling behavior :P I think this is the case for text models and things like the Winograd schema challenges.
2
(I'm trying to answer and clarify some of the points in the comments based on my interpretation of Yudkowsky in this post. So take the interpretations with a grain of salt, not as "exactly what Yudkowsky meant")
My summary of what you're defending here: because hardware progress is (according to you) the major driver of AI innovation, then we should invest a lot of our forecasting resources into forecasting it, and we should leverage it as the strongest source of evidence available for thinking about AGI timelines.
I feel like this is not in contradiction with what Yudkowsky wrote in this post? I doubt he agrees that just additional compute is the main driver of progress (after all, the Bitter Lesson mostly tells you that insights and innovations leveraging more compute will beat hardcorded ones), but insofar as he expect us to have next to no knowledge of how to build AGI until around 2 years before it is done (and then only for those with the Thelian secret), then compute is indeed the next best thing that we have to estimate timelines.
Yet Yudkowsky's point is that being the next best thing doesn't mean it's any good.
Evolution being an upper bound makes sense, and I think Yudkowsky agrees. But it's an upper bound on the whole human optimization process, and the search space of the human optimization is tricky to think about. I see much of Yudkowsky's criticisms of biological estimates here as saying "this biological anchor doesn't express the cost of evolution's optimization in terms of human optimization, but instead goes for a proxy which doesn't tell you anything".
So if someone captured both evolution and human optimization in the same search space, and found an upper bound on the cost (in terms of optimization power) that evolution spent to find humans, then I expect Yudkowsky would agree that this is an upper bound for the optimization power that human will use. But he might still retort that translating optimization power into compute is not obvious.
Meta-comment:
I noticed that I found it very difficult to read through this post, even though I felt the content was important, because of the (deliberately) condescending style. I also noticed that I'm finding it difficult to take the ideas as seriously as I think I should, again due to the style. I did manage to read through it in the end, because I do think it's important, and I think I am mostly able to avoid letting the style influence my judgments. But I find it fascinating to watch my own reaction to the post, and I'm wondering if others have any (constructive) insights on this.
In general I I've noticed that I have a very hard time reading things that are written in a polemical, condescending, insulting, or ridiculing manner. This is particularly true of course if the target is a group / person / idea that I happen to like. But even if it's written by someone on "my side" I find I have a hard time getting myself to read it. There have been several times when I've been told I should really go read a certain book, blog, article, etc., and that it has important content I should know about, but I couldn't get myself to read the whole thing due to the polemical or insulting way in...
Things I instinctively observed slash that my model believes that I got while reading that seem relevant, not attempting to justify them at this time:
- There is a core thing that Eliezer is trying to communicate. It's not actually about timeline estimates, that's an output of the thing. Its core message length is short, but all attempts to find short ways of expressing it, so far, have failed.
- Mostly so have very long attempts to communicate it and its prerequisites, which to some extent at least includes the Sequences. Partial success in some cases, full success in almost none.
- This post, and this whole series of posts, feels like its primary function is training data to use to produce an Inner Eliezer that has access to the core thing, or even better to know the core thing in a fully integrated way. And maybe a lot of Eliezer's other communications is kind of also trying to be similar training data, no matter the superficial domain it is in or how deliberate that is.
- The condescension is important information to help a reader figure out what is producing the outputs, and hiding it would make the task of 'extract the key insights' harder.
- Similarly, the repetition of the sam
1[comment deleted]
I find it concerning that you felt the need to write "This is not at all a criticism of the way this post was written. I am simply curious about my own reaction to it" (and still got downvoted?).
For my part, I both believe that this post contains valuable content and good arguments, and that it was annoying / rude / bothersome in certain sections.
I had a pretty strong negative reaction to it. I got the feeling that the post derives much of its rhetorical force from setting up an intentionally stupid character who can be condescended to, and that this is used to sneak in a conclusion that would seem much weaker without that device.
When I try to mentally simulate negative reader-reactions to the dialogue, I usually get a complicated feeling that's some combination of:
- Some amount of conflict aversion: Harsh language feels conflict-y, which is inherently unpleasant.
- Empathy for, or identification with, the people or views Eliezer was criticizing. It feels bad to be criticized, and it feels doubly bad to be told 'you are making basic mistakes'.
- Something status-regulation-y: My reader-model here finds the implied threat to the status hierarchy salient (whether or not Eliezer is just trying to honestly state his beliefs), and has some version of an 'anti-cheater' or 'anti-rising-above-your-station' impulse.
How right/wrong do you think this is, as a model of what makes the dialogue harder or less pleasant to read from your perspective?
(I feel a little wary of stating my model above, since (a) maybe it's totally off, and (b) it can be rude to guess at other people's mental states. But so far this conversation has felt very abstract to me, so maybe this can at least serve as a prompt to go more concrete. E.g., 'I find it hard to read condescending things' is very vague about which parts of the dialogue we're talking about, about what makes them feel condescending, and about how the feeling-of-condescension affects the sentence-parsing-and-evaluating experience.)
I think part of what I was reacting to is a kind of half-formed argument that goes something like:
- My prior credence is very low that all these really smart, carefully thought-through people are making the kinds of stupid or biased mistakes they are being accused of.
- In fact, my prior for the above is sufficiently low that I suspect it's more likely that the author is the one making the mistake(s) here, at least in the sense of straw-manning his opponents.
- But if that's the case then I shouldn't trust the other things he says as much, because it looks like he's making reasoning mistakes himself or else he's biased.
- Therefore I shouldn't take his arguments so seriously.
Again, this isn't actually an argument I would make. It's just me trying to articulate my initial negative reactions to the post.
I had mixed feelings about the dialogue personally. I enjoy the writing style and think Eliezer is a great writer with a lot of good opinions and arguments, which made it enjoyable.
But at the same time, it felt like he was taking down a strawman. Maybe you’d label it part of “conflict aversion”, but I tend to get a negative reaction to take-downs of straw-people who agree with me.
To give an unfair and exaggerated comparison, it would be a bit like reading a take-down of a straw-rationalist in which the straw-rationalist occasionally insists such things as “we should not be emotional” or “we should always use Bayes’ Theorem in every problem we encounter.” It should hopefully be easy to see why a rationalist might react negatively to reading that sort of dialogue.
5
1: To me, it made it more entertaining and thus easier to read. (No idea about non-anecdotal data, would also be interested.)
3: Also no data; I strongly suspect the metric is generally good because... actually I think it's just because the people I find worth listening to are overwhelmingly not condescending. This post seems highly usual in several ways.
I've gotten one private message expressing more or less the same thing about this post, so I don't think this is a super unusual reaction.
Short summary: Biological anchors are a bad way to predict AGI. It’s a case of “argument from comparable resource consumption.” Analogy: human brains use 20 Watts. Therefore, when we have computers with 20 Watts, we’ll have AGI! The 2020 OpenPhil estimate of 2050 is based on a biological anchor, so we should ignore it.
Longer summary:
Lots of folks made bad AGI predictions by asking:
- How much compute is needed for AGI?
- When that compute will be available?
To find (1), they use a “biological anchor,” like the computing power of the human brain, or the total compute used to evolve human brains.
Hans Moravec, 1988: the human brain uses 10^13 ops/s, and computers with this power will be available in 2010.
Eliezer objects that:
- “We’ll have computers as fast as human brains in 2010” doesn’t imply “we’ll have strong AI in 2010.”
- The compute needed depends on how well we understand cognition and computer science. It might be done with a hypercomputer but very little knowledge, or a modest computer but lots of knowledge.
- An AGI wouldn’t actually need 10^13 ops/s, because human brains are inefficient. One example, they do lots of operations in parallel, which could be replaced with fewer o
2
Holden also mentions something a bit like Eliezer's criticism in his own write-up,
When Holden talks about 'ingenuity' methods that seems consistent with Eliezer's
I.e. if you wanted to fold this consideration into OpenAI's estimate you'd have to do it by having a giant incredibly uncertain free-floating variable for 'speedup factor' because you'd be nonsensically trying to estimate the 'speed-up' to brain processing applied from using some completely non-Deep Learning or non-brainlike algorithm for intelligence. All your uncertainty just gets moved into that one factor, and you're back where you started.
It's possible that Eliezer is confident in this objection partly because of his 'core of generality' model of intelligence - i.e. he's implicitly imagining enormous numbers of varied paths to improvement that end up practically in the same place, while 'stack more layers in a brainlike DL model' is just one of those paths (and one that probably won't even work), so he naturally thinks estimating the difficulty of this one path we definitely won't take (and which probably wouldn't work even if we did try it) out of the huge numbers of varied paths to generality is useless.
However, if you don't have this model, then perhaps you can be more confident that what we're likely to build will look at least somewhat like a compute-limited DL system and that these other paths will have to share some properties of this path. Relatedly, it's an implication of the model that there's some imaginable (and not e.g. galaxy sized) model we could build right now that would be an AGI, which I think Eliezer disputes?
Heartened by a strong-upvote for my attempt at condensing Eliezer's object-level claim about timeline estimates, I shall now attempt condensing Eliezer's meta-level "core thing".
- Certain epistemic approaches to arrive at object-level knowledge consistently look like a good source of grounding in reality, especially to people who are trying to be careful about epistemics, and yet such approaches' grounding in reality is consistently illusory.
- Specific examples mentioned in the post are "the outside view", "reference class forecasting", "maximum entropy", "the median of what I remember credible people saying", and, most importantly for the object-level but least importantly for the Core Thing, "Drake-equation-style approaches that cleanly represent the unknown of interest as a deterministic function of simpler-seeming variables".
- Specific non-examples are concrete experimental observations (falling objects, celestial motion). These have grounding in reality, but they don't tend to feel like they're "objective" in the same way, like a nexus that my beliefs are epistemically obligated to move toward—they just feel like a part of my map that isn't confused. (If experiments do start to feel
Making a map of your map is another one of those techniques that seem to provide more grounding but do not actually.
Sounds to me like one of the things Eliezer is pointing at in Hero Licensing:
Look, thinking things like that is just not how the inside of my head is organized. There’s just the book I have in my head and the question of whether I can translate that image into reality. My mental world is about the book, not about me.
You do want to train your brain, and you want to understand your strengths and weaknesses. But dwelling on your biases at the expense of the object level isn't actually usually the best way to give your brain training data and tweak its performance.
I think there's a lesson here that, e.g., Scott Alexander hadn't fully internalized as of his 2017 Inadequate Equilibria review. There's a temptation to "go meta" and find some cleaner, more principled, more objective-sounding algorithm to follow than just "learn lots and lots of object-level facts so you can keep refining your model, learn some facts about your brain too so you can know how much to trust it in different domains, and just keep doing that".
But in fact there's no a priori reason to expect there to...
3
(My comment is quite critical, but I want to make it clear that I think doing this exercise is great and important, despite my disagreement with the result of the exercise ;) )
So, for having done the same exercise, I feel that you go far too meta here. And that by doing so, you're losing most of the actual valuable meta insights of the post. I'm not necessarily saying that your interpretation doesn't fit what Yudkowsky says, but if the goal is to distill where Yudkowsky is coming from in this specific post, I feel like this comment fails.
AFAIU, Yudkowsky is not at all arguing against searching for grounding in reality, he's arguing for a very specific grounding in reality that I've been calling deep knowledge in my post interpreting him on the topic. He's arguing that there are ways to go beyond the agnosticism of Science (which is very similar to the agnosticism of the outside view and reference class forecasting) between hypotheses that haven't been falsified yet, and let you move towards the true answer despite the search space being far too large to tractably explore. (See that section in particular of my post, where I go into a lot of details about Yudkowsky's writing on that in the Sequences).
I also feel like your interpretation conflates the errors that Humbali makes and the ones Simulated-OpenPhil makes, but they're different in my understanding:
* Humbali keeps on criticising Yudkowsky's confidence, and is the representative of the bad uses of the outside view and reference class forecasting. Which is why a lot of the answers to Humbali focus on deep knowledge (which Yudkowsky refer to here with the extended metaphor of the rails), where it comes from, and why it lets you discard some hypotheses (which is the whole point)
* Simulated-OpenPhil mostly defend their own approach and the fact that you can use biological anchors to reason about timelines if you do it carefully. The answer Yudkowsky gives is IMO that they don't have/give a way of linking
The two extracts from this post that I found most interesting/helpful:
...The problem is that the resource gets consumed differently, so base-rate arguments from resource consumption end up utterly unhelpful in real life. The human brain consumes around 20 watts of power. Can we thereby conclude that an AGI should consume around 20 watts of power, and that, when technology advances to the point of being able to supply around 20 watts of power to computers, we'll get AGI?
I'm saying that Moravec's "argument from comparable resource consumption" must be in general invalid, because it Proves Too Much. If it's in general valid to reason about comparable resource consumption, then it should be equally valid to reason from energy consumed as from computation consumed, and pick energy consumption instead to call the basis of your median estimate.
You say that AIs consume energy in a very different way from brains? Well, they'll also consume computations in a very different way from brains! The only difference between these two cases is that you know something about how humans eat food and break it down in their stomachs and convert it into ATP that gets consumed by
I wrote a lengthy exegesis of Humbali's confusion around “maximum entropy”, which I decided ended up somewhere between a comment and a post in terms of quality, so I put it here in "Shortform". I'm new to contributing content on AF, so meta-level feedback about how best to use the different channels (commenting, shortform, posting) is welcome.
This is a long post that I have only skimmed.
It seems like the ante, in support of any claim like "X forecasting method doesn't work [historically]," is to compare it to some other forecasting method on offer---whatever is being claimed as the default to be used in X's absence. (edited to add "historically")
It looks to me like historical forecasts that look like biological anchors have fared relatively well compared to the alternatives, but I could easily be moved by someone giving some evidence about what kind of methodology would have worked well or poorly, or what kinds of forecasts were actually being made at the time.
The methodological points in this post may be sound even if it's totally ungrounded in track record, but at that point the title is mostly misleading clickbait.
(My main complaint in this comment is "what's the alternative you are comparing to?" That said, the particular claims about Moravec's views also look fairly uncharitable to me, as Carl has pointed out and I've raised to Eliezer. It does not seem to me from reading Moravec's writing in 1988 like he expects TAI in 2010 rather than 2030. Maybe Eliezer is better at understanding what people are saying. But he often describes the views of people in 2020, who I can talk to and confirm, and does not in fact do a good job.)
6
The post feels like it's trying pretty hard to point towards an alternative forecasting method, though I also agree it's not fully succeeding at getting there.
I feel like de-facto the forecasting methodology of people who are actually good at forecasting don't usually strike me as low-inferential distance, such that it is obvious how to communicate the full methodology. My sense from talking to a number of superforecasters over the years is that they do pretty complicated things, and I don't feel like the critique of "A critique is only really valid if it provides a whole countermethodology" is a very productive way of engaging with their takes. I feel like I've had lots of conversations of the type "X methodology doesn't work" without someone being able to explain all the details of what they do instead, that were still valuable and helped me model the world, and said meaningful things. Usually the best they can do is something like "well, instead pay attention and build a model of these different factors", which feels like a bar Eliezer is definitely clearing in this post.
I think it's fine to say that you think something else is better without being able to precisely say what it is. I just think "the trick that never works" is an overstatement if you aren't providing evidence about whether it has worked, and that it's hard to provide such evidence without saying something about what you are comparing to.
(Like I said though, I just skimmed the post and it's possible it contains evidence or argument that I didn't catch.)
It's possible the action is in disagreements about Moravec's view rather than the lack of an alternative, but it's hard to say because it's unclear how good Eliezer thinks the alternative is. I think that looking at Moravec's view in hindsight it doesn't seem crazy at all, and e.g. I think it's more reasonable than Eliezer's views from 10 years later.
My take on the exercise:
Is Humbali right that generic uncertainty about maybe being wrong, without other extra premises, should increase the entropy of one's probability distribution over AGI, thereby moving out its median further away in time?
Short version: Nah. For example, if you were wrong by dint of failing to consider the right hypothesis, you can correct for it by considering predictable properties of the hypotheses you missed (even if you don't think you can correctly imagine the true research pathway or w/e in advance). And if you were wrong in your calculations of the quantities you did consider, correction will regress you towards your priors, which are simplicity-based rather than maxent.
Long version: Let's set aside for the moment the question of what the "correct" maxent distribution on AGI timelines is (which, as others have noted, depends a bit on how you dice up the space of possible years). I don't think this is where the action is, anyway.
Let's suppose that we're an aspiring Bayesian considering that we may have made some mistakes in our calculations. Where might those mistakes have been? Perhaps:
- We were mistaken about what we saw (and erroneously updated
In my view, the biological anchors and the Very Serious estimates derived therefrom are really useful for the following very narrow yet plausibly impactful purpose: persuading people, whose intuitive sense of biological anchors as lower bounds leads their AGI timeline to stretch out to 2100 or beyond, that they should really have shorter timelines. This is almost touched on in the dialogue where the OpenPhil character says “isn’t this at least a soft upper bound?” but Eliezer dismisses it as neither an upper nor a lower bound. I don’t disagree with Eliezer’s actual claim there, but I think he may be missing the value of putting well-researched soft upper bounds on a bunch of variables that generally well-read people often perceive as lower bounds on AGI’s arrival time—and guess to be much further away than they are. Even if those variables provide almost no relevant evidence to someone who has the appropriate kind of uncertainty about AGI’s compute requirements as a function of humanity’s knowledge about AI.
From this perspective, aggregating all the biological anchors with mixture weights tuned to produce a distribution whose median matches the psychological plausibility of Platt’s Law is a way to make the report as a whole Overton-window-compatible, while enabling readers to widen their distribution enough to put substantial probability mass on sooner years than the Overton window would have permitted, or even to decide for themselves to down-weight the larger biological anchors and shift their entire distribution sooner.
In my view, the biological anchors and the Very Serious estimates derived therefrom are really useful for the following very narrow yet plausibly impactful purpose
I don't understand why it's not just useful directly. Saying that the numbers are not true upper or lower bounds seems like it's expecting way too much!
They're not even labeled as bounds (at least in the headline). They're supposed to be "anchors".
Suppose you'd never done the analysis to know how much compute a human brain uses, or how much compute all of evolution had used. Wouldn't this report be super useful to you?
Sure, it doesn't directly tell you when TAI is going to come, because there's a separate thing you don't know, which is how compute-efficient our systems are going to be compared to the human brain. And also that translation factor is changing with time. But surely that's another quantity we can have a distribution over.
If there's some quantity that we don't know the value of, but we have at least one way to estimate it using some other uncertain quantities, why is it not useful to reduce our uncertainty about some of those other quantities?
This seems like exactly the kind of thing superforecasters are suppo...
I'm especially keen to hear responses to this point:
Eliezer: Backtesting this viewpoint on the previous history of computer science, it seems to me to assert that it should be possible to:
Train a pre-Transformer RNN/CNN-based model, not using any other techniques invented after 2017, to GPT-2 levels of performance, using only around 2x as much compute as GPT-2;
Play pro-level Go using 8-16 times as much computing power as AlphaGo, but only 2006 levels of technology.
...
Your model apparently suggests that we have gotten around 50 times more efficient at turning computation into intelligence since that time; so, we should be able to replicate any modern feat of deep learning performed in 2021, using techniques from before deep learning and around fifty times as much computing power.
OpenPhil: No, that's totally not what our viewpoint says when you backfit it to past reality. Our model does a great job of retrodicting past reality.
My guess is that Ajeya / OpenPhil would say "The halving-in-costs every 2.5 years is on average, not for everything. Of course there are going to be plenty of things for which algorithmic progress has been much faster. There are also things f...
4
The definition of "year Y compute requirements" is complicated in a kind of crucial way here, to attempt to a) account for the fact that you can't take any amount of compute and turn it into a solution for some task literally instantly, while b) capturing that there still seems to be a meaningful notion of "the compute you need to do some task is decreasing over time." I go into it in this section of part 1.
First we start with the "year Y technical difficulty of task T:"
* In year Y, imagine a largeish team of good researchers (e.g. the size of AlphaGo's team) is embarking on a dedicated project to solve task T.
* They get an amount of $ D dumped on them, which could be more $ than exists in the whole world, like 10 quadrillion or whatever.
* With a few years of dedicated effort (e.g. 2-5), plus whatever fungible resources they could buy with D dollars (e.g. terms of compute and data and low-skilled human labor), can that team of researchers produce a program that solves task T? Here we assume that the fungible resources are infinitely available if you pay, so e.g. if you pay a quadrillion dollars you can get an amount of compute that is (FLOP/$ in year Y) * (1 quadrillion), even though we obviously don't have that many computers.
And the "technical difficulty of task T in year Y" is how big D is for the best plan that the researchers can come up with in that time. What I wrote in the doc was:
And then you have "year Y compute requirements," which is whatever amount of compute they'd buy with whatever portion of D dollars they spend on compute.
This definition is convoluted, which isn't ideal, but after thinking about it for ~10 hours it was the best I could do to balance a) and b) above.
With all that said, I actually do think that the team of good researchers could have gotten GPT-level perf with somewhat more compute a couple years ago, and AlphaGo-level perf with significantly more compute several years ago. I'm not sure exactly what ratio would be, bu
3
Nice, thanks!
For reference, here is a 2004 post by Moravec, that’s helpfully short, containing his account of his own predictions: https://www.frc.ri.cmu.edu/~hpm/project.archive/robot.papers/2004/Predictions.html
I think this does not do justice to Ajeya's bio anchors model. Carl already said the important bits, but here are some more points:
But, if you insist on the error of anchoring on biology, you could perhaps do better by seeing a spectrum between two bad anchors. This lets you notice a changing reality, at all, which is why I regard it as a helpful thing to say to you and not a pure persuasive superweapon of unsound argument. Instead of just fixating on one bad anchor, the hybrid of biological anchoring with whatever knowledge you currently have about optimization, you can notice how reality seems to be shifting between two biological bad anchors over time, and so have an eye on the changing reality at all. Your new estimate in terms of gradient descent is stepping away from evolutionary computation and toward the individual-brain estimate by ten orders of magnitude, using the fact that you now know a little more about optimization than natural selection knew; and now that you can see the change in reality over time, in terms of the two anchors, you can wonder if there are more shifts ahead.
This is exactly what the bio anchors framework is already doing? It has the ...
5
I don't think this is what Yudkowsky is saying at all in the post. Actually, I think he is saying the exact opposite: that 2.5 years estimate is too fast as an estimate that is supposed to always work. If I understand correctly, his point is that you have significantly less than that most of the time, except during the initial growth after paradigms shifts where you're pushing as much compute as you can on your new paradigm. (That being said, Yudkowsky seems to agree with you that this should make us directionally update towards AGI arriving in less time)
My interpretation seems backed by this quote (and the fact that he's presenting these points as if they're clearly wrong):
I don't understand how Yudkowsky can be changing the subject when his subject has never been about "probability distribution over date-of-AGI-creation"? His point IMO is that this is a bad question to ask, not because you wouldn't want the true answer if you could magically get it, but because we don't have and won't have even close to the amount of evidence needed to do this non-trivially until 2 years before AGI (and maybe not even then, because you need to know the Thielian secrets). As such, to reach an answer that fit that type, you must contort the evidence and extract more bits of information that the analogies actually contain, which means that this is a recipe for saying nonsense.
(Note that I'm not arguing Yudkowsky is right, just that I think this is his point, and that your comment is missing it — might be wrong about all of those ^^)
Here too this sounds like missing Yudkowsky's point, which is made in the paragraph just after your original quote:
My interpretation is that he's saying that:
* The model, and the whole approach, is a fundamentally bad and misguided way of thinking about these questions, which falls in the many ways he's arguing for before in the dialogue
* If he stops talking about whether the model is bad, and just looks at its output, then he thinks t
2
Thanks for this comment (and the other comment below also).
I think we don't really disagree that much here. I may have just poorly communicated, slash maybe I'm objecting to the way Yudkowsky said things because I read it as implying things I disagree with.
That's what I think too--normal incremental progress is probably slower than 2.5-year doubling, but there's also occasional breakthrough progress which is much faster, and it all balances out to a faster-than-2.5-year-doubling, but in such a way that makes it really hard to predict, because so much hangs on whether and when breakthroughs happen. I think I just miscommunicated.
Here I think I share your interpretation of Yudkowsky; I just disagree with Yudkowsky. I agree on the second part; the model overestimates median TAI arrival time. But I disagree on the first part -- I think that having a probability distribution over when to expect TAI / AGI / AI-PONR etc. is pretty important/decision-relevant, e.g. for advising people on whether to go to grad school, or for deciding what sort of research project to undertake. (Perhaps Yudkowsky agrees with this much.) And I think that Ajeya's framework is the best framework I know of for getting that distribution. I think any reasonable distribution should be formed by Ajeya's framework, or some more complicated model that builds off of it (adding more bells and whistles such as e.g. a data-availability constraint or a probability-of-paradigm-shift mechanic.). Insofar as Yudkowsky was arguing against this, and saying that we need to throw out the whole model and start from scratch with a different model, I was not convinced. (Though maybe I need to reread the post and/or your steelman summary)
2
Hum, I would say Yudkowsky seems to agree with the value of a probability distribution for timelines.
(Quoting The Weak Inside View (2008) from the AI FOOM Debate)
On the other hand, my interpretation of Yudkowsky strongly disagree with the second part of your paragraph:
So my interpretation of the text is that Yudkowsky says that you need to know how compute will be transformed into AGI to estimate the timelines (then you can plug your estimates for the compute), and that the default of any approach which relies on biological analogies for that part will be sprouting nonsense, because evolution and biology optimize in fundamentally different ways than human researchers do.
For each of the three examples, he goes into more detail about the way this is instantiated. My understanding of his criticism of Ajeya's model is that he disagrees that just current deep learning algorithms are actually a recipe for turning compute into AGI, and so saying "we keep to current deep learning and estimated the required compute" doesn't make sense and doesn't solve the question of how to turn compute into AGI. (Note that his might be the place where you or someone defending Ajeya's model want to disagree with Yudkowsky. I'm just pointing that this is a more productive place to debate him because that might actually make him change his mind — or change your mind if he convinces you)
The more general argument (the reason why "the trick" doesn't work) is that if you actually have a way of transforming compute into AGI, that means you know how to build AGI. And if you do, you're very, very close to the end of the timeline.
4
I guess I would say: Ajeya's framework/model can incorporate this objection; this isn't a "get rid of the whole framework" objection but rather a "tweak the model in the following way" objection.
Like, I agree that it would be bad if everyone who used Ajeya's model had to put 100% of their probability mass into the six bio anchors she chose. That's super misleading/biasing/ignores loads of other possible ways AGI might happen. But I don't think of this as a necessary part of Ajeya's model; when I use it, I throw out the six bio anchors and just directly input my probability distribution over OOMs of compute. My distribution is informed by the bio anchors, of course, but that's not the only thing that informs it.
2
First, I want to clarify that I feel we're going into a more interesting place, where there's a better chance that you might find a point that invalidates Yudkowsky's argument, and can thus convince him of the value of the model.
But it's also important to realize that IMO, Yudkowsky is not just saying that biological anchors are bad. The more general problem (which is also developed in this post) is that predicting the Future is really hard. In his own model of AGI timelines, the factor that is basically impossible to predict until you can make AGI is the "how much resources are needed to build AGI".
So saying "let's just throw away the biological anchors" doesn't evade the general counterargument that to predict timelines at all, you need to find information on "how much resources are needed to build AGI", and that is incredibly hard. If you or Ajeya can argue for actual evidence in that last question, then yeah, I expect Yudkowsky would possibly update on the validity of the timeline estimates.
But at the moment, in this thread, I see no argument like that.
Going to try answering this one:
Humbali: I feel surprised that I should have to explain this to somebody who supposedly knows probability theory. If you put higher probabilities on AGI arriving in the years before 2050, then, on average, you're concentrating more probability into each year that AGI might possibly arrive, than OpenPhil does. Your probability distribution has lower entropy. We can literally just calculate out that part, if you don't believe me. So to the extent that you're wrong, it should shift your probability distributions in the direction of maximum entropy.
[Is Humbali right that generic uncertainty about maybe being wrong, without other extra premises, should increase the entropy of one's probability distribution over AGI, thereby moving out its median further away in time?]
The uncertainty must already be "priced in" your probability distribution. So your distribution and hence your median shouldn't shift at all, unless you actually observe new relevant evidence of course.
(This post was partly written as a follow-up to Eliezer's conversations with Paul and Ajeya, so I've inserted it into the conversations sequence.)
It does fit well there, but I think it was more inspired by the person I met who thought I was being way too arrogant by not updating in the direction of OpenPhil's timeline estimates to the extent I was uncertain.
Curated. Many times over the years I've seen analogies from biology used to produce estimates about AI timelines. This is the most thoroughly-argued case I've seen against them. While I believe some find the format uncomfortable, I'm personally glad to see Eliezer expressing his beliefs as he feels them, and think this is worth reading for anyone interested in predicting how AI will play out in coming years.
For those short on time, I recommend this summary by Grant Demaree.
Is Humbali right that generic uncertainty about maybe being wrong, without other extra premises, should increase the entropy of one's probability distribution over AGI, thereby moving out its median further away in time?
My answer to this is that
First, no update whatsoever should take place because a probability distribution already expresses uncertainty, and there's no mechanism by which the uncertainty increased. Adele Lopez independently (and earlier) came up with the same answer.
Second, if there were an update -- say EY learned "one of the steps used in my model was wrong" -- this should indeed change the distribution. However, it should change it toward the prior distribution. It's completely unclear what the prior distribution is, but there is no rule whatsoever that says "more entropy = more prior-y" as shown by the fact that a uniform distribution over the next years has extremely high entropy yet makes a ludicrously confident prediction.
See also Information Charts (second chapter). Being under-confident/losing confidence does not have to shift your probability toward the 50% mark; it shifts it toward the prior from whoever it was before, and the prior can be lite
OK, I'll bite on EY's exercise for the reader, on refuting this "what-if":
...Humbali: Then here's one way that the minimum computational requirements for general intelligence could be higher than Moravec's argument for the human brain. Since, after, all, we only have one existence proof that general intelligence is possible at all, namely the human brain. Perhaps there's no way to get general intelligence in a computer except by simulating the brain neurotransmitter-by-neurotransmitter. In that case you'd need a lot more computing oper
I feel like a big crux is whether Platt's Law is true:
Eliezer: I mean, in fact, part of my actual sense of indignation at this whole affair, is the way that Platt's law of strong AI forecasts - which was in the 1980s generalizing "thirty years" as the time that ends up sounding "reasonable" to would-be forecasters - is still exactly in effect for what ends up sounding "reasonable" to would-be futurists, in fricking 2020 while the air is filling up with AI smoke in the silence of nonexistent fire alarms.
Didn't AI Impacts look into this a while back? See e.g. this dataset. Below is one of the graphs:
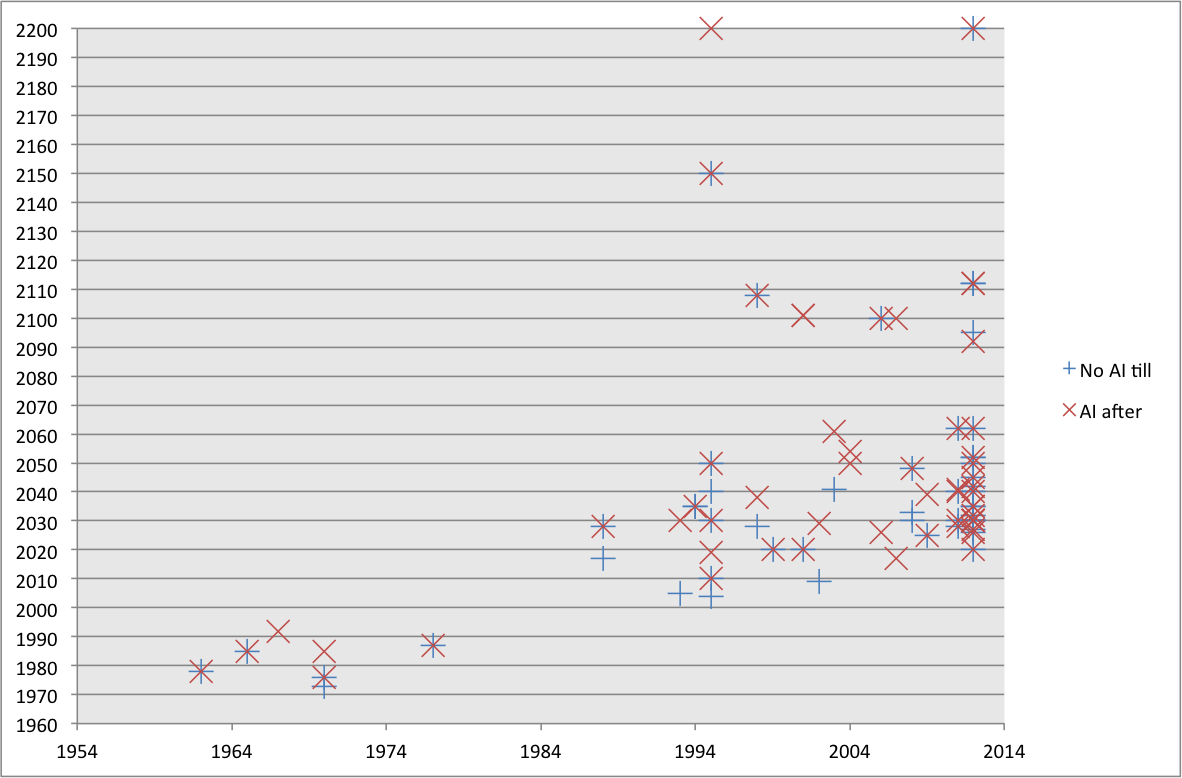
It may help to visualize this graph with the line for Platt's Law drawn in.
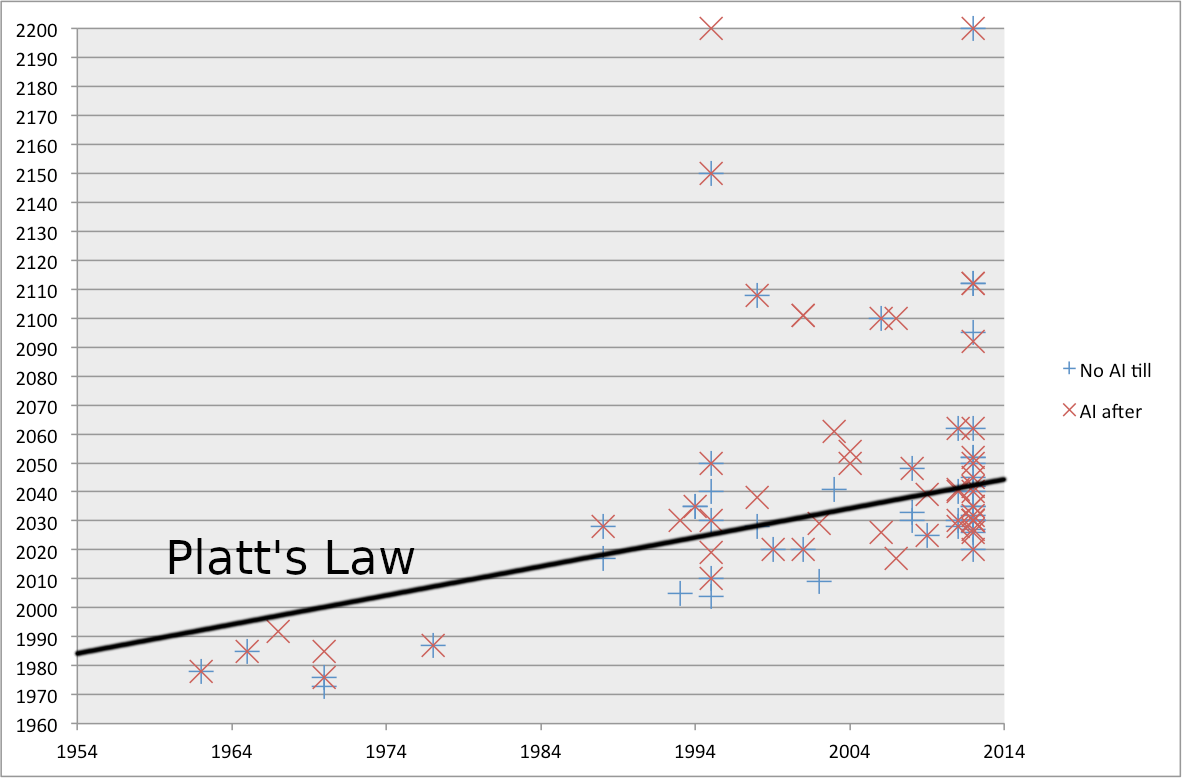
Overall I find the law to be pretty much empirically validated, at least by the standards I'd expect from a half in jest Law of Prediction.
5
Wow, I'd forgotten about that prediction dataset! It seems like there's only even semi-decent data since 1994, but since then there does seem to be a plausible ~35-year median in the recorded points (even though, or perhaps because, the sampled distribution has been changing over time).
4
Strongly disagree with this, to the extent that I think this is probably the least cruxy topic discussed in this post, and thus the comment is as wrong as is physically possible.
Remove Platt's law, and none of the actual arguments and meta-discussions changes. It's clearly a case of Yudkowsky going for the snappy "hey, see like even your new-and-smarter report makes exactly the same estimation predicted by a random psychological law" + his own frustration with the law still applying despite expected progress.
But once again, if Platt's law was so wrong that there was never in the history of the universe a single instance of people predicting strong AI and/or AGI in 30 years, this would have no influence whatsoever on the arguments in this post IMO.
5
Hahaha ok, interesting! If you are right I'll take some pride in having achieved that distinction. ;)
I interpreted Yudkowsky as claiming that Ajeya's model had enough free parameters that it could be made to predict a wide range of things, and that what was actually driving the 30-year prediction was a bunch of implicit biases rather than reality. Platt's Law is evidence for this claim. If it were false and e.g. the typical timelines forecast was only 10 years out, or 60, then we would have less reason to think that implicit biases were driving Ajeya's choice of parameters. Of course, Yudkowsky also made other arguments besides this one... but this one seemed to be there, and it seemed fairly important to me.
It's entirely possible I am misconstruing Yudkowsky's argument... you did recently do a reconstruction, so you probably understand it better than me. Care to elaborate?
4
I do think you are misconstruing Yudkowsky's argument. I'm going to give evidence (all of which are relatively strong IMO) in order of "ease of checkability". So I'll start with something anyone can check in a couple of minutes, and close by the more general interpretation that requires rereading the post in details.
Evidence 1: Yudkowsky flags Simulated-Eliezer as talking smack in the part you're mentioning
If I follow you correctly, your interpretation mostly comes from this part:
Note that this is one of the two times in this dialogue where Simulated-OpenPhil calls out Simulated-Eliezer. But remember that this whole dialogue was written by Yudkowsky! So he is flagging himself that this particular answer is a quip. Simulated-Eliezer doesn't reexplain it as he does most of his insulting points to Humbali; instead Simulated-Eliezer goes for a completely different explanation in the next answer.
Evidence 2: Platt's law is barely mentioned in the whole dialogue
"Platt" is used 6-times in the 20k words piece. "30 years" is used 8 times (basically at the same place where "Platt" is used").
Evidence 3: Humbali spends far more time discussing and justifying the "30 years" time than Simulated-OpenPhil. And Humbali is the strawman character, whereas Simulated-OpenPhil actually tries to discuss and to understand what Simulated Eliezer is saying.
Evidence 4: There is an alternative interpretation that takes into account the full text and doesn't use Platt's law at all: see this comment on your other thread for my current best version of that explanation.
Evidence 5: Yudkowsky's whole criticism relying on a purely empirical and superficial similarity goes contrary to everything that I extracted from his writing in my recent post, and also to all the time he spends here discussing deep knowledge and the need for an underlying model.
So my opinion is that Platt's law is completely superfluous here, and is present here only because it gives a way of pointing to the ri
In many ways, this post is frustrating to read. It isn't straigthforward, it needlessly insults people, and it mixes irrelevant details with the key ideas.
And yet, as with many of Eliezer's post, its key points are right.
What this post does is uncover the main epistemological mistakes made by almost everyone trying their hands at figuring out timelines. Among others, there is:
- Taking arbitrary guesses within a set of options that you don't have enough evidence to separate
- Piling on arbitrary assumption on arbitraty assumption, leading to completely uninforma
For indeed in a case like this, one first backs up and asks oneself "Is Humbali right or not?" and not "How can I prove Humbali wrong?"
Gonna write up some of my thoughts here without reading on, and post them (also without reading on).
I don’t get why Humbali’s objection has not already been ‘priced in’. Eliezer has a bunch of models and info and his gut puts the timeline at before 2050. I don’t think “what if you’re mistaken about everything” isn’t an argument Eliezer already considered, so I think it’s already priced into the prediction. You’re not allowe
2
Hmm, alas, stopped reading too soon.
It's very easy to construct probability distributions that have earlier timelines, that look more intuitively unconfident, and that have higher entropy than the bio-anchors forecast. You can just take some of the probability mass from the peak around 2050 and redistribute it among earlier years, especially years that are very close to the present, where bioanchors are reasonably confident that AGI is unlikely.
Spoiler tags are borked the way I'm using them.
anyway, another place to try your hand at calibration:
Humbali: No. You're expressing absolute certainty in your underlying epistemology and your entire probability distribution
no he isn't, why?
Humbali is asking for Eliezer to double count evidence. Consilience is hard if you don't do your homework on provenance of heuristic and not just naively counting up outputs who themselves also didn't do their homework.
Or in other words: "Do not cite the deep evidence to me, I was there when it was written"
And another ...
but even if I've made two errors in the same direction, that only shifts the estimate by 7 years or so.
Where does he say this? On page 60, I can see Moravec say:
Nevertheless, my estimates can be useful even if they are only remotely correct. Later we will see that a thousandfold error in the ratio of neurons to computations shifts the predicted arrival time of fully intelligent machines a mere 20 years.
Which seems much more reasonable than claiming 7-year precision.
Which brings me to the second line of very obvious-seeming reasoning that converges upon the same conclusion - that it is in principle possible to build an AGI much more computationally efficient than a human brain - namely that biology is simply not that efficient, and especially when it comes to huge complicated things that it has started doing relatively recently.
Biological cells are computers which must copy bits to copy DNA. So we can ask biology - how much energy do cells use to copy each base pair? Seems they use just 4 ATP per base pair, or 1 ATP/bit, and thus within an OOM of the 'Landauer bound'. Which is more impressive if you consider that the typically quoted 'Landauer bound' of kT ln 2 is overly optimistic as it only applies when the error probability is 50% or the computation takes infinity. Useful computation requires at least somewhat higher speed than inf and reliability higher than none.
...Brains have to pump thousands of ions in and out of each stretch of axon and dendrite, in order to restore their ability to fire another fast neural spike. The result is that the brain's computation is something like half a million times less ef
You're missing the point!
Your arguments apply mostly toward arguing that brains are optimized for energy efficiency, but the important quantity in question is computational efficiency! You even admit that neurons are "optimizing hard for energy efficiency at the expense of speed", but don't seem to have noticed that this fact makes almost everything else you said completely irrelevant!
Imprecisely multiplying two analog numbers should not require 10^5 times the minimum bit energy in a well-designed computer.
A well-designed computer would also use, say, optical interconnects that worked by pushing one or two photons around at the speed of light. So if neurons are in some sense being relatively efficient at the given task of pumping thousands upon thousands of ions in and out of a depolarizing membrane in order to transmit signals at 100m/sec -- every ion of which necessarily uses at least the Landauer minimum energy -- they are being vastly far from optimally efficient.
The moment you see ions going in and out of a depolarizing membrane, and contrast that to the possibility of firing a photon down a fiber, you ought to be done asking whether or not biology has built an optimally efficient computer. It actually isn't any more complicated than that. You are driving yourself further from sanity if you then try to do very complicated reasoning about how it must be close to the limit of efficiency to pump thousands of ions in and out of a membrane instead.
2
This was super interesting.
I don't think you can directly compare brain voltage to Landauer limit, because brains operate chemically, so we also care about differences in chemical potential (e.g. of sodium vs potassium, which are importantly segregated across cell membranes even though both have the same charge). To really illustrate this, we might imagine information-processing biology that uses no electrical charges, only signalling via gradients of electrically-neutral chemicals. I think this raises the total potential relative to Landauer and cuts down the amount of molecules we should estimate as transported per signal.
Curated and popular this week