This is a special post for quick takes by Steve Byrnes. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Mentioned in
steve2152's Shortform
4Steve Byrnes
4Towards_Keeperhood
4Steve Byrnes
4Towards_Keeperhood
4Steve Byrnes
3Towards_Keeperhood
3Steve Byrnes
3Towards_Keeperhood
2Steve Byrnes
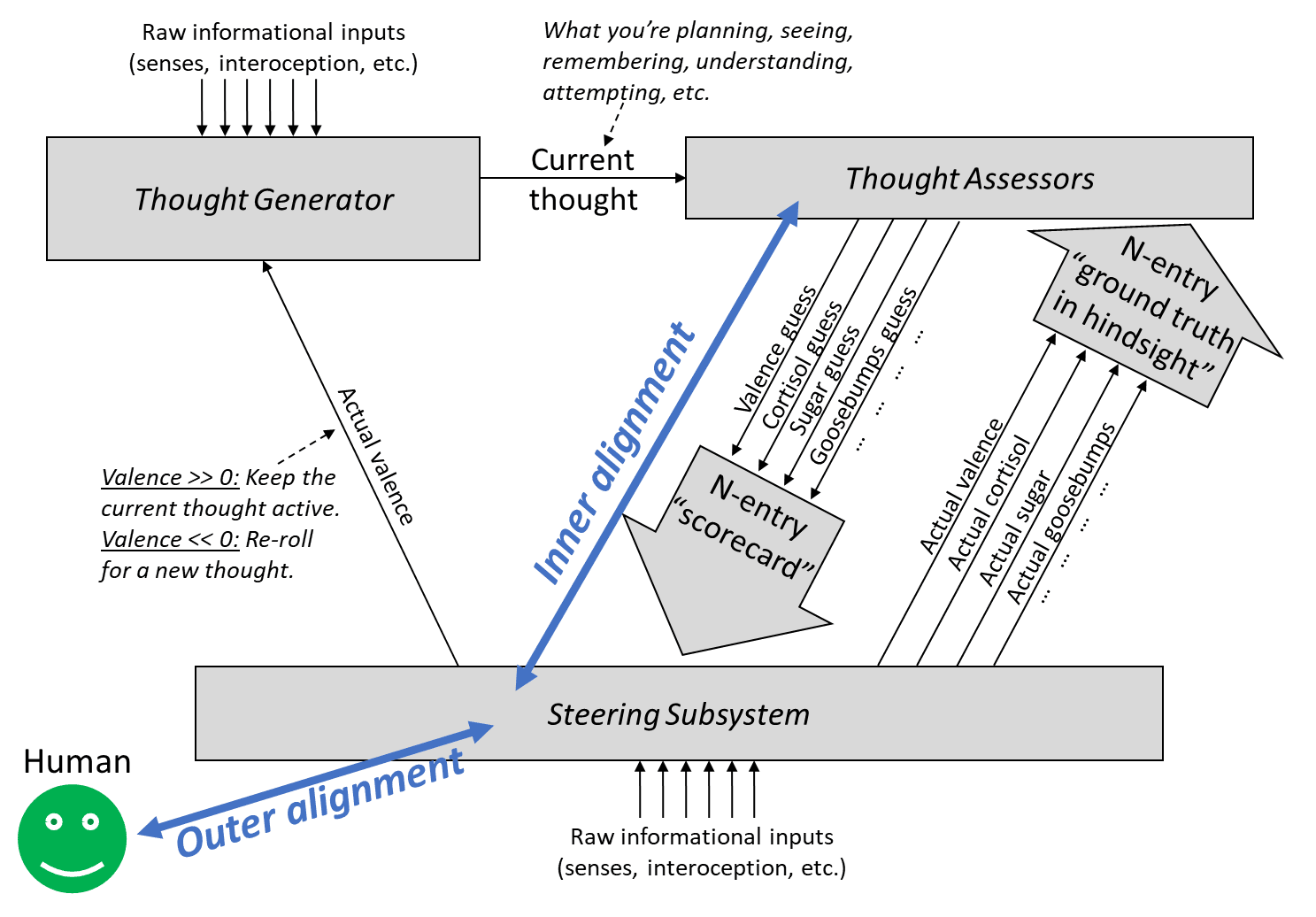
In [Intro to brain-like-AGI safety] 10. The alignment problem and elsewhere, I’ve been using “outer alignment” and “inner alignment” in a model-based actor-critic RL context to refer to:
“Outer alignment” entails having a ground-truth reward function that spits out rewards that agree with what we want. “Inner alignment” is having a learned value function that estimates the value of a plan in a way that agrees with its eventual reward.
For some reason it took me until now to notice that:
- my “outer misalignment” is more-or-less synonymous with “specification gaming”,
- my “inner misalignment” is more-or-less synonymous with “goal misgeneralization”.
(I’ve been regularly using all four terms for years … I just hadn’t explicitly considered how they related to each other, I guess!)
I updated that post to note the correspondence, but also wanted to signal-boost this, in case other people missed it too.
~~
[You can stop reading here—the rest is less important]
If everybody agrees with that part, there’s a further question of “…now what?”. What terminology should I use going forward? If we have redundant terminology, should we try to settle on one?
One obvious option is that I could just stop using the terms “inner alignment” and “outer alignment” in the actor-critic RL context as above. I could even go back and edit them out of that post, in favor of “specification gaming” and “goal misgeneralization”. Or I could leave it. Or I could even advocate that other people switch in the opposite direction!
One consideration is: Pretty much everyone using the terms “inner alignment” and “outer alignment” are not using them in quite the way I am—I’m using them in the actor-critic model-based RL context, they’re almost always using them in the model-free policy optimization context (e.g. evolution) (see §10.2.2). So that’s a cause for confusion, and point in favor of my dropping those terms. On the other hand, I think people using the term “goal misgeneralization” are also almost always using them in a model-free policy optimization context. So actually, maybe that’s a wash? Either way, my usage is not a perfect match to how other people are using the terms, just pretty close in spirit. I’m usually the only one on Earth talking explicitly about actor-critic model-based RL AGI safety, so I kinda have no choice but to stretch existing terms sometimes.
Hmm, aesthetically, I think I prefer the “outer alignment” and “inner alignment” terminology that I’ve traditionally used. I think it’s a better mental picture. But in the context of current broader usage in the field … I’m not sure what’s best.
(Nate Soares dislikes the term “misgeneralization”, on the grounds that “misgeneralization” has a misleading connotation that “the AI is making a mistake by its own lights”, rather than “something is bad by the lights of the programmer”. I’ve noticed a few people trying to get the variation “goal malgeneralization” to catch on instead. That does seem like an improvement, maybe I'll start doing that too.)
Note: I just noticed your post has a section "Manipulating itself and its learning process", which I must've completely forgotten since I last read the post. I should've read your post before posting this. Will do so.
“Outer alignment” entails having a ground-truth reward function that spits out rewards that agree with what we want. “Inner alignment” is having a learned value function that estimates the value of a plan in a way that agrees with its eventual reward.
Calling problems "outer" and "inner" alignment seems to suggest that if we solved both we've successfully aligned AI to do nice things. However, this isn't really the case here.
Namely, there could be a smart mesa-optimizer spinning up in the thought generator, who's thoughts are mostly invisible to the learned value function (LVF), and who can model the situation it is in and has different values and is smarter than the LVF evaluation and can fool the the LVF into believing the plans that are good according to the mesa-optimizer are great according to the LVF, even if they actually aren't.
This kills you even if we have a nice ground-truth reward and the LVF accurately captures that.
In fact, this may be quite a likely failure mode, given that the thought generator is where the actual capability comes from, and we don't understand how it works.
Thanks! But I don’t think that’s a likely failure mode. I wrote about this long ago in the intro to Thoughts on safety in predictive learning.
In my view, the big problem with model-based actor-critic RL AGI, the one that I spend all my time working on, is that it tries to kill us via using its model-based RL capabilities in the way we normally expect—where the planner plans, and the actor acts, and the critic criticizes, and the world-model models the world …and the end-result is that the system makes and executes a plan to kill us. I consider that the obvious, central type of alignment failure mode for model-based RL AGI, and it remains an unsolved problem.
I think (??) you’re bringing up a different and more exotic failure mode where the world-model by itself is secretly harboring a full-fledged planning agent. I think this is unlikely to happen. One way to think about it is: if the world-model is specifically designed by the programmers to be a world-model in the context of an explicit model-based RL framework, then it will probably be designed in such a way that it’s an effective search over plausible world-models, but not an effective search over a much wider space of arbitrary computer programs that includes self-contained planning agents. See also §3 here for why a search over arbitrary computer programs would be a spectacularly inefficient way to build all that agent stuff (TD learning in the critic, roll-outs in the planner, replay, whatever) compared to what the programmers will have already explicitly built into the RL agent architecture.
So I think this kind of thing (the world-model by itself spawning a full-fledged planning agent capable of treacherous turns etc.) is unlikely to happen in the first place. And even if it happens, I think the problem is easily mitigated; see discussion in Thoughts on safety in predictive learning. (Or sorry if I’m misunderstanding.)
Thanks.
Yeah I guess I wasn't thinking concretely enough. I don't know whether something vaguely like what I described might be likely or not. Let me think out loud a bit about how I think about what you might be imagining so you can correct my model. So here's a bit of rambling: (I think point 6 is most important.)
- As you described in you intuitive self-models sequence, humans have a self-model which can essentially have values different from the main value function, aka they can have ego-dystonic desires.
- I think in smart reflective humans, the policy suggestions of the self-model/homunculus can be more coherent than the value function estimates, e.g. because they can better take abstract philosophical arguments into account.
- The learned value function can also update on hypothetical scenarios, e.g. imagining a risk or a gain, but it doesn't update strongly on abstract arguments like "I should correct my estimates based on outside view".
- The learned value function can learn to trust the self-model if acting according to the self-model is consistently correlated with higher-than-expected reward.
- Say we have a smart reflective human where the value function basically trusts the self-model a lot, then the self-model could start optimizing its own values, while the (stupid) value function believes it's best to just trust the self-model and that this will likely lead to reward. Something like this could happen where the value function was actually aligned to outer reward, but the inner suggestor was just very good at making suggestions that the value function likes, even if the inner suggestor would have different actual values. I guess if the self-model suggests something that actually leads to less reward, then the value function will trust the self-model less, but outside the training distribution the self-model could essentially do what it wants.
- Another question of course is whether the inner self-reflective optimizers are likely aligned to the initial value function. I would need to think about it. Do you see this as a part of the inner alignment problem or as a separate problem?
- As an aside, one question would be whether the way this human makes decisions is still essentially actor-critic model-based RL like - whether the critic just got replaced through a more competent version. I don't really know.
- (Of course, I totally ackgnowledge that humans have pre-wired machinery for their intuitive self-models, rather than that just spawning up. I'm not particularly discussing my original objection anymore.)
- I'm also uncertain whether something working through the main actor-critic model-based RL mechanism would be capable enough to do something pivotal. Like yeah, most and maybe all current humans probably work that way. But if you go a bit smarter then minds might use more advanced techniques of e.g. translating problems into abstract domains and writing narrow AIs to solve them there and then translating it back into concrete proposals or sth. Though maybe it doesn't matter as long as the more advanced techniques don't spawn up more powerful unaligned minds, in which case a smart mind would probably not use the technique in the first place. And I guess actor-critic model-based RL is sorta like expected utility maximization, which is pretty general and can get you far. Only the native kind of EU maximization we implement through actor-critic model-based RL might be very inefficient compared through other kinds.
- I have a heuristic like "look at where the main capability comes from", and I'd guess for very smart agents it perhaps doesn't come from the value function making really good estimates by itself, and I want to understand how something could be very capable and look at the key parts for this and whether they might be dangerous.
- Ignoring human self-models now, the way I imagine actor-critic model-based RL is that it would start out unreflective. It might eventually learn to model parts of itself and form beliefs about its own values. Then, the world-modelling machinery might be better at noticing inconsistencies in the behavior and value estimates of that agent than the agent itself. The value function might then learn to trust the world-model's predictions about what would be in the interest of the agent/self.
- This seems to me to sorta qualify as "there's an inner optimizer". I would've tentitatively predicted you to say like "yep but it's an inner aligned optimizer", but not sure if you actually think this or whether you disagree with my reasoning here. (I would need to consider how likely value drift from such a change seems. I don't know yet.)
I don't have a clear take here. I'm just curious if you have some thoughts on where something importantly mismatches your model.
Thanks! Basically everything you wrote importantly mismatches my model :( I think I can kinda translate parts; maybe that will be helpful.
Background (§8.4.2): The thought generator settles on a thought, then the value function assigns a “valence guess”, and the brainstem declares an actual valence, either by copying the valence guess (“defer-to-predictor mode”), or overriding it (because there’s meanwhile some other source of ground truth, like I just stubbed my toe).
Sometimes thoughts are self-reflective. E.g. “the idea of myself lying in bed” is a different thought from “the feel of the pillow on my head”. The former is self-reflective—it has me in the frame—the latter is not (let’s assume).
All thoughts can be positive or negative valence (motivating or demotivating). So self-reflective thoughts can be positive or negative valence, and non-self-reflective thoughts can also be positive or negative valence. Doesn’t matter, it’s always the same machinery, the same value function / valence guess / thought assessor. That one function can evaluate both self-reflective and non-self-reflective thoughts, just as it can evaluate both sweater-related thoughts and cloud-related thoughts.
When something seems good (positive valence) in a self-reflective frame, that’s called ego-syntonic, and when something seems bad in a self-reflective frame, that’s called ego-dystonic.
Now let’s go through what you wrote:
1. humans have a self-model which can essentially have values different from the main value function
I would translate that into: “it’s possible for something to seem good (positive valence) in a self-reflective frame, but seem bad in a non-self-reflective frame. Or vice-versa.” After all, those are two different thoughts, so yeah of course they can have two different valences.
2. the policy suggestions of the self-model/homunculus can be more coherent than the value function estimates
I would translate that into: “there’s a decent amount of coherence / self-consistency in the set of thoughts that seem good or bad in a self-reflective frame, and there’s less coherence / self-consistency in the set of things that seem good or bad in a non-self-reflective frame”.
(And there’s a logical reason for that; namely, that hard thinking and brainstorming tends to bring self-reflective thoughts to mind — §8.5.5 — and hard thinking and brainstorming is involved in reducing inconsistency between different desires.)
3. The learned value function can learn to trust the self-model if acting according to the self-model is consistently correlated with higher-than-expected reward.
This one is more foreign to me. A self-reflective thought can have positive or negative valence for the same reasons that any other thought can have positive or negative valence—because of immediate rewards, and because of the past history of rewards, via TD learning, etc.
One thing is: someone can develop a learned metacognitive habit to the effect of “think self-reflective thoughts more often” (which is kinda synonymous with “don’t be so impulsive”). They would learn this habit exactly to the extent and in the circumstances that it has led to higher reward / positive valence in the past.
4. Say we have a smart reflective human where the value function basically trusts the self-model a lot, then the self-model could start optimizing its own values, while the (stupid) value function believes it's best to just trust the self-model and that this will likely lead to reward.
If someone gets in the habit of “think self-reflective thoughts all the time” a.k.a. “don’t be so impulsive”, then their behavior will be especially strongly determined by which self-reflective thoughts are positive or negative valence.
But “which self-reflective thoughts are positive or negative valence” is still determined by the value function / valence guess function / thought assessor in conjunction with ground-truth rewards / actual valence—which in turn involves the reward function, and the past history of rewards, and TD learning, blah blah. Same as any other kind of thought.
…I won’t keep going with your other points, because it’s more of the same idea.
Does that help explain where I’m coming from?
I'd suggest not using conflated terminology and rather making up your own.
Or rather, first actually don't use any abstract handles at all and just describe the problems/failure-modes directly, and when you're confident you have a pretty natural breakdown of the problems with which you'll stick for a while, then make up your own ontology.
In fact, while in your framework there's a crisp difference between ground-truth reward and learned value-estimator, it might not make sense to just split the alignment problem in two parts like this:
“Outer alignment” entails having a ground-truth reward function that spits out rewards that agree with what we want. “Inner alignment” is having a learned value function that estimates the value of a plan in a way that agrees with its eventual reward.
First attempt of explaining what seems wrong: If that was the first I read on outer-vs-inner alignment as a breakdown of the alignment problem, I would expect "rewards that agree with what we want" to mean something like "changes in expected utility according to humanity's CEV". (Which would make inner alignment unnecessary because if we had outer alignment we could easily reach CEV.)
Second attempt:
"in a way that agrees with its eventual reward" seems to imply that there's actually an objective reward for trajectories of the universe. However, the way you probably actually imagine the ground-truth reward is something like humans (who are ideally equipped with good interpretability tools) giving feedback on whether something was good or bad, so the ground-truth reward is actually an evaluation function on the human's (imperfect) world model. Problems:
- Humans don't actually give coherent rewards which are consistent with a utility function on their world model.
- For this problem we might be able to define an extrapolation procedure that's not too bad.
- The reward depends on the state of the world model of the human, and our world models probably often has false beliefs.
- Importantly, the setup needs to be designed in a way that there wouldn't be an incentive to manipulate the humans into believing false things.
- Maybe, optimistically, we could mitigate this problem by having the AI form a model of the operators, doing some ontology translation between the operator's world model and its own world model, and flagging when there seems to be a relavant belief mismatch.
- Our world models cannot evaluate yet whether e.g. filling the universe computronium running a certain type of programs would be good, because we are confused about qualia and don't know yet what would be good according to our CEV. Basically, the ground-truth reward would very often just say "i don't know yet", even for cases which are actually very important according to our CEV. It's not just that we would need a faithful translation of the state of the universe into our primitive ontology (like "there are simulations of lots of happy and conscious people living interesting lives"), it's also that (1) the way our world model treats e.g. "consciousness" may not naturally map to anything in a more precise ontology, and while our human minds, learning a deeper ontology, might go like "ah, this is what I actually care about - I've been so confused", such value-generalization is likely even much harder to specify than basic ontology translation. And (2), our CEV may include value-shards which we currently do not know of or track at all.
- So while this kind of outer-vs-inner distinction might maybe be fine for human-level AIs, it stops being a good breakdown for smarter AIs, since whenever we want to make the AI do something where humans couldn't evaluate the result within reasonable time, it needs to generalize beyond what could be evaluated through ground-truth reward.
So mainly because of point 3, instead of asking "how can i make the learned value function agree with the ground-truth reward", I think it may be better to ask "how can I make the learned value function generalize from the ground-truth reward in the way I want"?
(I guess the outer-vs-inner could make sense in a case where your outer evaluation is superhumanly good, though I cannot think of such a case where looking at the problem from the model-based RL framework would still make much sense, but maybe I'm still unimaginative right now.)
Note that I assumed here that the ground-truth signal is something like feedback from humans. Maybe you're thinking of it differently than I described here, e.g. if you want to code a steering subsystem for providing ground-truth. But if the steering subsystem is not smarter than humans at evaluating what's good or bad, the same argument applies. If you think your steering subsystem would be smarter, I'd be interested in why.
(All that is assuming you're attacking alignment from the actor-critic model-based RL framework. There are other possible frameworks, e.g. trying to directly point the utility function on an agent's world-model, where the key problems are different.)
Thanks!
I think “inner alignment” and “outer alignment” (as I’m using the term) is a “natural breakdown” of alignment failures in the special case of model-based actor-critic RL AGI with a “behaviorist” reward function (i.e., reward that depends on the AI’s outputs, as opposed to what the AI is thinking about). As I wrote here:
Suppose there’s an intelligent designer (say, a human programmer), and they make a reward function R hoping that they will wind up with a trained AGI that’s trying to do X (where X is some idea in the programmer’s head), but they fail and the AGI is trying to do not-X instead. If R only depends on the AGI’s external behavior (as is often the case in RL these days), then we can imagine two ways that this failure happened:
- The AGI was doing the wrong thing but got rewarded anyway (or doing the right thing but got punished)
- The AGI was doing the right thing for the wrong reasons but got rewarded anyway (or doing the wrong thing for the right reasons but got punished).
I think it’s useful to catalog possible failures based on whether they involve (1) or (2), and I think it’s reasonable to call them “failures of outer alignment” and “failures of inner alignment” respectively, and I think when (1) is happening rarely or not at all, we can say that the reward function is doing a good job at “representing” the designer’s intention—or at any rate, it’s doing as well as we can possibly hope for from a reward function of that form. The AGI still might fail to acquire the right motivation, and there might be things we can do to help (e.g. change the training environment), but replacing R (which fires exactly to the extent that the AGI’s external behavior involves doing X) by a different external-behavior-based reward function R’ (which sometimes fires when the AGI is doing not-X, and/or sometimes doesn’t fire when the AGI is doing X) seems like it would only make things worse. So in that sense, it seems useful to talk about outer misalignment, a.k.a. situations where the reward function is failing to “represent” the AGI designer’s desired external behavior, and to treat those situations as generally bad.
(A bit more related discussion here.)
That definitely does not mean that we should be going for a solution to outer alignment and a separate unrelated solution to inner alignment, as I discussed briefly in §10.6 of that post, and TurnTrout discussed at greater length in Inner and outer alignment decompose one hard problem into two extremely hard problems. (I endorse his title, but I forget whether I 100% agreed with all the content he wrote.)
I find your comment confusing, I’m pretty sure you misunderstood me, and I’m trying to pin down how …
One thing is, I’m thinking that the AGI code will be an RL agent, vaguely in the same category as MuZero or AlphaZero or whatever, which has an obvious part of its source code labeled “reward”. For example, AlphaZero-chess has a reward of +1 for getting checkmate, -1 for getting checkmated, 0 for a draw. Atari-playing RL agents often use the in-game score as a reward function. Etc. These are explicitly parts of the code, so it’s very obvious and uncontroversial what the reward is (leaving aside self-hacking), see e.g. here where an AlphaZero clone checks whether a board is checkmate.
Another thing is, I’m obviously using “alignment” in a narrower sense than CEV (see the post—“the AGI is ‘trying’ to do what the programmer had intended for it to try to do…”)
Another thing is, if the programmer wants CEV (for the sake of argument), and somehow (!!) writes an RL reward function in Python whose output perfectly matches the extent to which the AGI’s behavior advances CEV, then I disagree that this would “make inner alignment unnecessary”. I’m not quite sure why you believe that. The idea is: actor-critic model-based RL agents of the type I’m talking about evaluate possible plans using their learned value function, not their reward function, and these two don’t have to agree. Therefore, what they’re “trying” to do would not necessarily be to advance CEV, even if the reward function were perfect.
If I’m still missing where you’re coming from, happy to keep chatting :)
Thanks!
Another thing is, if the programmer wants CEV (for the sake of argument), and somehow (!!) writes an RL reward function in Python whose output perfectly matches the extent to which the AGI’s behavior advances CEV, then I disagree that this would “make inner alignment unnecessary”. I’m not quite sure why you believe that.
I was just imagining a fully omnicient oracle that could tell you for each action how good that action is according to your extrapolated preferences, in which case you could just explore a bit and always pick the best action according to that oracle. But nvm, I noticed my first attempt of how I wanted to explain what I feel like is wrong sucked and thus dropped it.
- The AGI was doing the wrong thing but got rewarded anyway (or doing the right thing but got punished)
- The AGI was doing the right thing for the wrong reasons but got rewarded anyway (or doing the wrong thing for the right reasons but got punished).
This seems like a sensible breakdown to me, and I agree this seems like a useful distinction (although not a useful reduction of the alignment problem to subproblems, though I guess you agree here).
However, I think most people underestimate how many ways there are for the AI to do the right thing for the wrong reasons (namely they think it's just about deception), and I think it's not:
I think we need to make AI have a particular utility function. We have a training distribution where we have a ground-truth reward signal, but there are many different utility functions that are compatible with the reward on the training distribution, which assign different utilities off-distribution.
You could avoid talking about utility functions by saying "the learned value function just predicts reward", and that may work while you're staying within the distribution we actually gave reward on, since there all the utility functions compatible with the ground-truth reward still agree. But once you're going off distribution, what value you assign to some worldstates/plans depends on what utility function you generalized to.
I think humans have particular not-easy-to-pin-down machinery inside them, that makes their utility function generalize to some narrow cluster of all ground-truth-reward-compatible utility functions, and a mind with a different mind design is unlikely to generalize to the same cluster of utility functions.
(Though we could aim for a different compatible utility function, namely the "indirect alignment" one that say "fulfill human's CEV", which has lower complexity than the ones humans generalize to (since the value generalization prior doesn't need to be specified and can instead be inferred from observations about humans). (I think that is what's meant by "corrigibly aligned" in "Risks from learned optimization", though it has been a very long time since I read this.))
Actually, it may be useful to distinguish two kinds of this "utility vs reward mismatch":
1. Utility/reward being insufficiently defined outside of training distribution (e.g. for what programs to run on computronium).
2. What things in the causal chain producing the reward are the things you actually care about? E.g. that the reward button is pressed, that the human thinks you did something well, that you did something according to some proxy preferences.
Overall, I think the outer-vs-inner framing has some implicit connotation that for inner alignment we just need to make it internalize the ground-truth reward (as opposed to e.g. being deceptive). Whereas I think "internalizing ground-truth reward" isn't meaningful off distribution and it's actually a very hard problem to set up the system in a way that it generalizes in the way we want.
But maybe you're aware of that "finding the right prior so it generalizes to the right utility function" problem, and you see it as part of inner alignment.
I was just imagining a fully omnicient oracle that could tell you for each action how good that action is according to your extrapolated preferences, in which case you could just explore a bit and always pick the best action according to that oracle.
OK, let’s attach this oracle to an AI. The reason this thought experiment is weird is because the goodness of an AI’s action right now cannot be evaluated independent of an expectation about what the AI will do in the future. E.g., if the AI says the word “The…”, is that a good or bad way for it to start its sentence? It’s kinda unknowable in the absence of what its later words will be.
So one thing you can do is say that the AI bumbles around and takes reversible actions, rolling them back whenever the oracle says no. And the oracle is so good that we get CEV that way. This is a coherent thought experiment, and it does indeed make inner alignment unnecessary—but only because we’ve removed all the intelligence from the so-called AI! The AI is no longer making plans, so the plans don’t need to be accurately evaluated for their goodness (which is where inner alignment problems happen).
Alternately, we could flesh out the thought experiment by saying that the AI does have a lot of intelligence and planning, and that the oracle is doing the best it can to anticipate the AI’s behavior (without reading the AI’s mind). In that case, we do have to worry about the AI having bad motivation, and tricking the oracle by doing innocuous-seeming things until it suddenly deletes the oracle subroutine out of the blue (treacherous turn). So in that version, the AI’s inner alignment is still important. (Unless we just declare that the AI’s alignment is unnecessary in the first place, because we’re going to prevent treacherous turns via option control.)
However, I think most people underestimate how many ways there are for the AI to do the right thing for the wrong reasons (namely they think it's just about deception), and I think it's not:
Yeah I mostly think this part of your comment is listing reasons that inner alignment might fail, a.k.a. reasons that goal misgeneralization / malgeneralization can happen. (Which is a fine thing to do!)
If someone thinks inner misalignment is synonymous with deception, then they’re confused. I’m not sure how such a person would have gotten that impression. If it’s a very common confusion, then that’s news to me.
Inner alignment can lead to deception. But outer alignment can lead to deception too! Any misalignment can lead to deception, regardless of whether the source of that misalignment was “outer” or “inner” or “both” or “neither”.
“Deception” is deliberate by definition—otherwise we would call it by another term, like “mistake”. That’s why it has to happen after there are misaligned motivations, right?
Overall, I think the outer-vs-inner framing has some implicit connotation that for inner alignment we just need to make it internalize the ground-truth reward
OK, so I guess I’ll put you down as a vote for the terminology “goal misgeneralization” (or “goal malgeneralization”), rather than “inner misalignment”, as you presumably find that the former makes it more immediately obvious what the concern is. Is that fair? Thanks.
I think we need to make AI have a particular utility function. We have a training distribution where we have a ground-truth reward signal, but there are many different utility functions that are compatible with the reward on the training distribution, which assign different utilities off-distribution.
You could avoid talking about utility functions by saying "the learned value function just predicts reward", and that may work while you're staying within the distribution we actually gave reward on, since there all the utility functions compatible with the ground-truth reward still agree. But once you're going off distribution, what value you assign to some worldstates/plans depends on what utility function you generalized to.
I think I fully agree with this in spirit but not in terminology!
I just don’t use the term “utility function” at all in this context. (See §9.5.2 here for a partial exception.) There’s no utility function in the code. There’s a learned value function, and it outputs whatever it outputs, and those outputs determine what plans seem good or bad to the AI, including OOD plans like treacherous turns.
I also wouldn’t say “the learned value function just predicts reward”. The learned value function starts randomly initialized, and then it’s updated by TD learning or whatever, and then it eventually winds up with some set of weights at some particular moment, which can take inputs and produce outputs. That’s the system. We can put a comment in the code that says the value function is “supposed to” predict reward, and of course that code comment will be helpful for illuminating why the TD learning update code is structured the way is etc. But that “supposed to” is just a code comment, not the code itself. Will it in fact predict reward? That’s a complicated question about algorithms. In distribution, it will probably predict reward pretty accurately; out of distribution, it probably won’t; but with various caveats on both sides.
And then if we ask questions like “what is the AI trying to do right now” or “what does the AI desire”, the answer would mainly depend on the value function.
Actually, it may be useful to distinguish two kinds of this "utility vs reward mismatch":
1. Utility/reward being insufficiently defined outside of training distribution (e.g. for what programs to run on computronium).
2. What things in the causal chain producing the reward are the things you actually care about? E.g. that the reward button is pressed, that the human thinks you did something well, that you did something according to some proxy preferences.
I’ve been lumping those together under the heading of “ambiguity in the reward signal”.
The second one would include e.g. ambiguity between “reward for button being pressed” vs “reward for human pressing the button” etc.
The first one would include e.g. ambiguity between “reward for being-helpful-variant-1” vs “reward for being-helpful-variant-2”, where the two variants are indistinguishable in-distribution but have wildly differently opinions about OOD options like brainwashing or mind-uploading.
Another way to think about it: the causal chain intuition is also an OOD issue, because it only becomes a problem when the causal chains are always intact in-distribution but they can come apart in new ways OOD.
More from Steven Byrnes
Curated and popular this week