Some AI research areas and their relevance to existential safety
27paulfchristiano
4Andrew_Critch
21paulfchristiano
6Andrew_Critch
1Sammy Martin
10paulfchristiano
20DanielFilan
13DanielFilan
1Andrew_Critch
13Vanessa Kosoy
6paulfchristiano
1Vanessa Kosoy
4paulfchristiano
2Vanessa Kosoy
2Andrew_Critch
2Gurkenglas
1Vanessa Kosoy
11Nisan
7Nisan
9Rohin Shah
7paulfchristiano
2Andrew_Critch
6Raemon
5Sammy Martin
3William_S
3Rohin Shah
3adamShimi
3Ofer
3DanielFilan
2Koen.Holtman
2romeostevensit
1Ben Pace
1Raemon
1William_S
New Comment
Progress in OODR will mostly be used to help roll out more AI technologies into active deployment more quickly
It sounds like you may be assuming that people will roll out a technology when its reliability meets a certain level X, so that raising reliability of AI systems has no or little effect on the reliability of deployed system (namely it will just be X). I may be misunderstanding.
A more plausible model is that deployment decisions will be based on many axes of quality, e.g. suppose you deploy when the sum of reliability and speed reaches some threshold Y. If that's the case, then raising reliability will improve the reliability and decrease the speed of deployed systems. If you think that increasing the reliability of AI systems is good (e.g. because AI developers want their AI systems to have various socially desirable properties and are limited by their ability to robustly achieve those properties) then this would be good.
I'm not clear on what part of that picture you disagree with or if you think that this is just small relative to some other risks. My sense is that most of the locally-contrarian views in this post are driven by locally-contrarian quantitative estimates of various risks. If that's the case, then it seems like the main thing that would shift my view would be some argument about the relative magnitude of risks. I'm not sure if other readers feel similarly.
Research in this area usually does not involve deep or lengthy reflections about the structure of society and human values and interactions, which I think makes this field sort of collectively blind to the consequences of the technologies it will help build.
This is a plausible view, but I'm not sure what negative consequences you have in mind (or how it affects the value of progress in the field rather than the educational value of hanging out with people in the field).
Incidentally, the main reason I think OODR research is educationally valuable is that it can eventually help with applying agent foundations research to societal-scale safety. Specifically: how can we know if one of the operations (a)-(f) above is safe to perform 1,000,000 times, given that it was safe the first 1,000 times we applied it in a controlled setting, but the setting is changing over time? This is a special case of an OODR question.
That task---how do we test that this system will consistently have property P, given that we can only test property P at training time?---is basically the goal of OODR research. Your prioritization of OODR suggests that maybe you think that's the "easy part" of the problem (perhaps because testing property P is so much harder), or that OODR doesn't make meaningful progress on that problem (perhaps because the nature of the problem is so different for different properties P?). Whatever it is, it seems like that's at the core of the disagreement and you don't say much about it. I think many people have the opposite intuition, i.e. that much of the expected harm from AI systems comes from behaviors that would have been recognized as problematic at training time.
In any case, I see AI alignment in turn as having two main potential applications to existential safety:
- AI alignment is useful as a metaphor for thinking about how to align the global effects of AI technology with human existence, a major concern for AI governance at a global scale, and
- AI alignment solutions could be used directly to govern powerful AI technologies designed specifically to make the world safer.
Here is one standard argument for working on alignment. It currently seems plausible that AI systems will be trying to do stuff that no one wants and that this could be very bad if AI systems are much more competent than humans. Prima facie, if the designers of AI systems are able to better control what AI systems are trying to do, then those AI systems are more likely to be trying to do what the developers want. So if we are able to give developers that ability, we can reduce the risk of AI competently doing stuff no one wants.
This isn't really a metaphor, it's a direct path for impact. It's unclear if you think that this argument is mistaken because developers will be able to control what their AI systems are trying to do, because they won't be motivated to deploy AI until they have that control, because it's not much better for AI systems to be trying to do what their developers want, because there are other more important reasons that AI systems could be trying to do stuff that no one wants, because there are other risks unrelated to AI trying to do stuff no one wants, or something else altogether.
(2) is essentially aiming to take over the world in the name of making it safer, which is not generally considered the kind of thing we should be encouraging lots of people to do.
Like you, I'm opposed to plans where people try to take over the world in order to make it safer. But this looks like a bit of a leap. For example, AI alignment may help us build powerful AI systems that help us negotiate or draft agreements, which doesn't seem like taking over the world to make it safer.
It sounds like you may be assuming that people will roll out a technology when its reliability meets a certain level X, so that raising reliability of AI systems has no or little effect on the reliability of deployed system (namely it will just be X).
Yes, this is more or less my assumption. I think slower progress on OODR will delay release dates of transformative tech much more than it will improve quality/safety on the eventual date of release.
A more plausible model is that deployment decisions will be based on many axes of quality, e.g. suppose you deploy when the sum of reliability and speed reaches some threshold Y. If that's the case, then raising reliability will improve the reliability and decrease the speed of deployed systems. If you think that increasing the reliability of AI systems is good (e.g. because AI developers want their AI systems to have various socially desirable properties and are limited by their ability to robustly achieve those properties) then this would be good.
I'm not clear on what part of that picture you disagree with or if you think that this is just small relative to some other risks.
Thanks for asking; I do disagree with this! Think reliability is a strongly dominant factor in decisions deploying real-world technology, such that to me it feels roughly-correct to treat it as the only factor. In this way of thinking, which you rightly attribute to me, progress in OODR doesn't improve reliability on deployment-day, it mostly just moves deployment-day a bit earlier in time.
That's not to say I'm advocating being afraid of OODR research because it "shortens timelines", only that I think contributions to OODR are not particularly directly valuable to humanity's long-term fate. As the post emphasizes, if someone cares about existential safety and wants to deploy their professional ambition to reducing x-risk, I think OODR is of high educational value for them to learn about, and as such I would be against "censoring" it as a topic to be discussed here.
If single/single alignment is solved it feels like there are some salient "default" ways in which we'll end up approaching multi/multi alignment:
- Existing single/single alignment techniques can also be applied to empower an organization rather than an individual. So we can use existing social technology to form firms and governments and so on, and those organizations will use AI.
- AI systems can themselves participate in traditional social institutions. So AI systems that represent individual human interests can interact with each other e.g. in markets or democracies.
I totally agree that there are many important problems in the world even if we can align AI. That said, I remain interested in more clarity on what you see as the biggest risks with these multi/multi approaches that could be addressed with technical research.
For example, let's take the considerations you discuss under CSC:
Third, unless humanity collectively works very hard to maintain a degree of simplicity and legibility in the overall structure of society*, this “alignment revolution” will greatly complexify our environment to a point of much greater incomprehensibility and illegibility than even today’s world. This, in turn, will impoverish humanity’s collective ability to keep abreast of important international developments, as well as our ability to hold the international economy accountable for maintaining our happiness and existence.
One approach to this problem is to work to make it more likely that AI systems can adequately represent human interests in understanding and intervening on the structure of society. But this seems to be a single/single alignment problem (to whatever extent that existing humans currently try to maintain and influence our social structure, such that impairing their ability to do so is problematic at all) which you aren't excited about.
Fourth, in such a world, algorithms will be needed to hold the aggregate global behavior of algorithms accountable to human wellbeing, because things will be happening too quickly for humans to monitor. In short, an “algorithmic government” will be needed to govern “algorithmic society”. Some might argue this is not strictly unnecessary: in the absence of a mathematically codified algorithmic social contract, humans could in principle coordinate to cease or slow down the use of these powerful new alignment technologies, in order to give ourselves more time to adjust to and govern their use. However, for all our successes in innovating laws and governments, I do not believe current human legal norms are quite developed enough to stably manage a global economy empowered with individually-alignable transformative AI capabilities.
Again, it's not clear what you expect to happen when existing institutions are empowered by AI and mostly coordinate the activities of AI.
The last line reads to me like "If we were smarter, when our legal system may no longer be up to the challenge," with which I agree. But it seems like the main remedy is "if we were smarter, we would hopefully work on improving our legal system in tandem with the increasing demands we impose on it."
It feels like the salient actions to take to me are (i) make direct improvements in the relevant institutions, in a way that anticipates the changes brought about by AI but will most likely not look like AI research, (ii) work on improving the relative capability of AI at those tasks that seem more useful for guiding society in a positive direction.
I consider (ii) to be one of the most important kinds of research other than alignment for improving the impact of AI, and I consider (i) to be all-around one of the most important things to do for making the world better. Neither of them feels much like CSC (e.g. I don't think computer scientists are the best people to do them) and it's surprising to me that we end up at such different places (if only in framing and tone) from what seem like similar starting points.
> Third, unless humanity collectively works very hard to maintain a degree of simplicity and legibility in the overall structure of society*, this “alignment revolution” will greatly complexify our environment to a point of much greater incomprehensibility and illegibility than even today’s world. This, in turn, will impoverish humanity’s collective ability to keep abreast of important international developments, as well as our ability to hold the international economy accountable for maintaining our happiness and existence.
One approach to this problem is to work to make it more likely that AI systems can adequately represent human interests in understanding and intervening on the structure of society. But this seems to be a single/single alignment problem (to whatever extent that existing humans currently try to maintain and influence our social structure, such that impairing their ability to do so is problematic at all) which you aren't excited about.
Yes, you've correctly anticipated my view on this. Thanks for the very thoughtful reading!
To elaborate: I claim "turning up the volume" on everyone's individual agency (by augmenting them with user-aligned systems) does not automatically make society overall healthier and better able to survive, and in fact it might just hasten progress toward an unhealthy or destructive outcome. To me, the way to avoid this is not to make the aligned systems even more aligned with their users, but to start "aligning" them with the rest of society. "Aligning" with society doesn't just mean "serving" society, it means "fitting into it", which means the AI system needs to have a particular structure (not just a particular optimization objective) that makes it able to exist and function safely inside a larger society. The desired structure involves features like being transparent, legibly beneficial, and legibly fair. Without those aspects, I think your AI system introduces a bunch of political instability and competitive pressure into the world (e.g., fighting over disagreements about what it's doing or whether it's fair or whether it will be good), which I think by default turns up the knob on x-risk rather than turning it down. For a few stories somewhat-resembling this claim, see my next post:
Of course, if you make a super-aligned self-modifying AI, it might immediately self-modify so that its structure is more legibly beneficial and fair, because of the necessity (if I'm correct) of having that structure for benefitting society and therefore its creators/users. However, my preferred approach to building societally-compatible AI is not to make societally-incompatible AI systems and hope that they know their users "want" them to transform into more societally-compatible systems. I think we should build highly societally-compatible systems to begin with, not just because it seems broadly "healthier", but because I think it's necessary for getting existential risk down to tolerable levels like <3% or <1%. Moreover, because this view seems misunderstood by x-safety enthusiasts, I currently put the plurality of my existential-failure probability on outcomes arising from problems other than individual systems being misaligned (in terms of the objective) with the users or creators. Dafoe et al would call this "structural risk", which I find to be a helpful framing that should be applied not only to the structure of society external to the AI system, but also the system's internal structure.
That said, I remain interested in more clarity on what you see as the biggest risks with these multi/multi approaches that could be addressed with technical research.
A (though not necessarily the most important) reason to think technical research into computational social choice might be useful is that examining specifically the behaviour of RL agents from a computational social choice perspective might alert us to ways in which coordination with future TAI might be similar or different to the existing coordination problems we face.
(i) make direct improvements in the relevant institutions, in a way that anticipates the changes brought about by AI but will most likely not look like AI research,
It seems premature to say, in advance of actually seeing what such research uncovers, whether the relevant mechanisms and governance improvements are exactly the same as the improvements we need for good governance generally, or different. Suppose examining the behaviour of current RL agents in social dilemmas leads to a general result which in turn leads us to conclude there's a disproportionate chance TAI in the future will coordinate in some damaging way that we can resolve with a particular new regulation. It's always possible to say, solving the single/single alignment problem will prevent anything like that from happening in the first place, but why put all your hopes on plan A, when plan B is relatively neglected?
It's always possible to say, solving the single/single alignment problem will prevent anything like that from happening in the first place, but why put all your hopes on plan A, when plan B is relatively neglected?
The OP writes "contributions to AI alignment are also generally unhelpful to existential safety." I don't think I'm taking a strong stand in favor of putting all our hopes on plan A, I'm trying to understand the perspective on which plan B is much more important even before considering neglectedness.
It seems premature to say, in advance of actually seeing what such research uncovers, whether the relevant mechanisms and governance improvements are exactly the same as the improvements we need for good governance generally, or different.
I agree that would be premature. That said, I still found it notable that OP saw such a large gap between the importance of CSC and other areas on and off the list (including MARL). Given that I would have these things in a different order (before having thought deeply), it seemed to illustrate a striking difference in perspective. I'm not really trying to take a strong stand, just using it to illustrate and explore that difference in perspective.
One frustration I have with the piece is that I read it as broadly in favour of the empirical distribution of governance demands. The section in the introduction talks of the benefits of legitimizing and fulfilling governance demands, and merely focussing on those demands that are helpful for existential safety. Similarly, I read the section on accountability in ML as broadly having a rhetorical stance that accountability is by default good, altho the recommendation to "help tech company employees and regulators to reflect on the principle of accountability and whether tech companies themselves should be more subject to it at various scales" would, if implemented literally, only promote the forms of accountability that are in fact good.
I'm frustrated by this stance that I infer the text to be taking, because I think that many existing and likely demands for accountability will be unjust and minimally conducive to existential safety. One example of unjust and ineffective accountability is regulatory capture of industries, where regulations tend to be overly lenient for incumbent players that have 'captured' the regulator and overly strict for players that might enter and compete with incumbents. Another is regulations of some legitimate activity by people uninformed about the activity and uninterested in allowing legitimate instances of the activity. My understanding is that most people agree that either regulation of abortions in many conservative US states or regulation of gun ownership in many liberal US states falls into this category. Note my claim is not that there are no legitimate governance demands in these examples, but that actual governance in these cases is unjust and ineffective at promoting legitimate ends, because it is not structured in a way that tends to produce good outcomes.
I am similarly frustrated by this claim:
The European General Data Protection Regulation (GDPR) is a very good step for regulating how tech companies relate with the public. I say this knowing that GDPR is far from perfect. The reason it's still extremely valuable is that it has initialized the variable defining humanity's collective bargaining position (at least within Europe...) for controlling how tech companies use data.
I read this as conflating European humanity with the European Union. I think the correct perspective to take is this: corporate boards keep corporations aligned with some aspects of some segment of humanity, and EU regulation keeps corporations aligned with different aspects of a different segment of humanity. Instead of thinking of this as a qualitative change from 'uncontrolled by humanity' to 'controlled by European humanity', instead I would rather have this be modelled as a change in the controlling structure, and have attention brought to bear on whether the change is in fact good.
Now, for the purpose of enhancing existential safety, I think it likely that any way of growing the set of people who can demand that AI corporations act in a way that serves those people's interests is better than governance purely by a board or employees of the company, because preserving existential safety is a broadly-held value, and outsiders may not be subject to as much bias as insiders about how dangerous the firm's technology is. Indeed, an increase in the size of this set by several orders of magnitude likely causes a qualitative shift. Nevertheless, I don't think there is much reason to think that the details of EU regulation is likely to be closely aligned with the interests of Europeans, and if the GDPR is valuable as a precedent to ensure that the EU can regulate data use, the alignment of the details of this data use is of great importance. As such, I think the structure of this governance is more important to focus on than the number taking part in governance.
In summary:
- I hope that technical AI x-risk/existential safety researchers focus on legitimizing and fulfilling those governance and accountability demands that are in fact legitimate.
- I hope that discussion of AI governance and accountability does not inhabit a frame in which demands for governance and accountability are reliably legitimate.
This comment is heavily informed by the perspectives that I understand to be advanced in the books The Myth of the Rational Voter, that democracies often choose poor policies because it isn't worth voters' time and effort to learn relevant facts and debias themselves, and The Problem of Political Authority, that democratic governance is often unjust, altho note that I have read neither book.
I also apologize for the political nature of this and the above comment. However, I don't know how to make it less political while still addressing the relevant parts of the post. I also think that the post is really great and thank Critch for writing it, despite the negative nature of the above comment.
My actual thought process for believing GDPR is good is not that it "is a sample from the empirical distribution of governance demands", but that it intializes the process of governments (and thereby the public they represent) weighing in on what tech companies can and cannot design their systems to reason about, and more specifically the degree to which systems are allowed to reason about humans. Having a regulatory structure in place for restricting access to human data is a good first step, but we'll probably also eventually want restrictions for how the systems process the data once they have it (e.g., they probably shouldn't be allowed to use what data they have to come up with ways to significantly deceive or manipulate users).
I'll say the same thing about fairness, in that I value having initialized the process of thinking about it not because it is in the "empirical distribution of governance demands", but because it's a useful governance demand. When things are more fair, people fight less, which is better/safer. I don't mind much that existing fairness research hasn't converged on what I consider "optimal fairness", because I think that consideration is dwarfed by the fact that technical AI researchers are thinking about fairness at all.
That said, while I disagree with your analysis, I do agree with your final position:
- I hope that technical AI x-risk/existential safety researchers focus on legitimizing and fulfilling those governance and accountability demands that are in fact legitimate.
- I hope that discussion of AI governance and accountability does not inhabit a frame in which demands for governance and accountability are reliably legitimate.
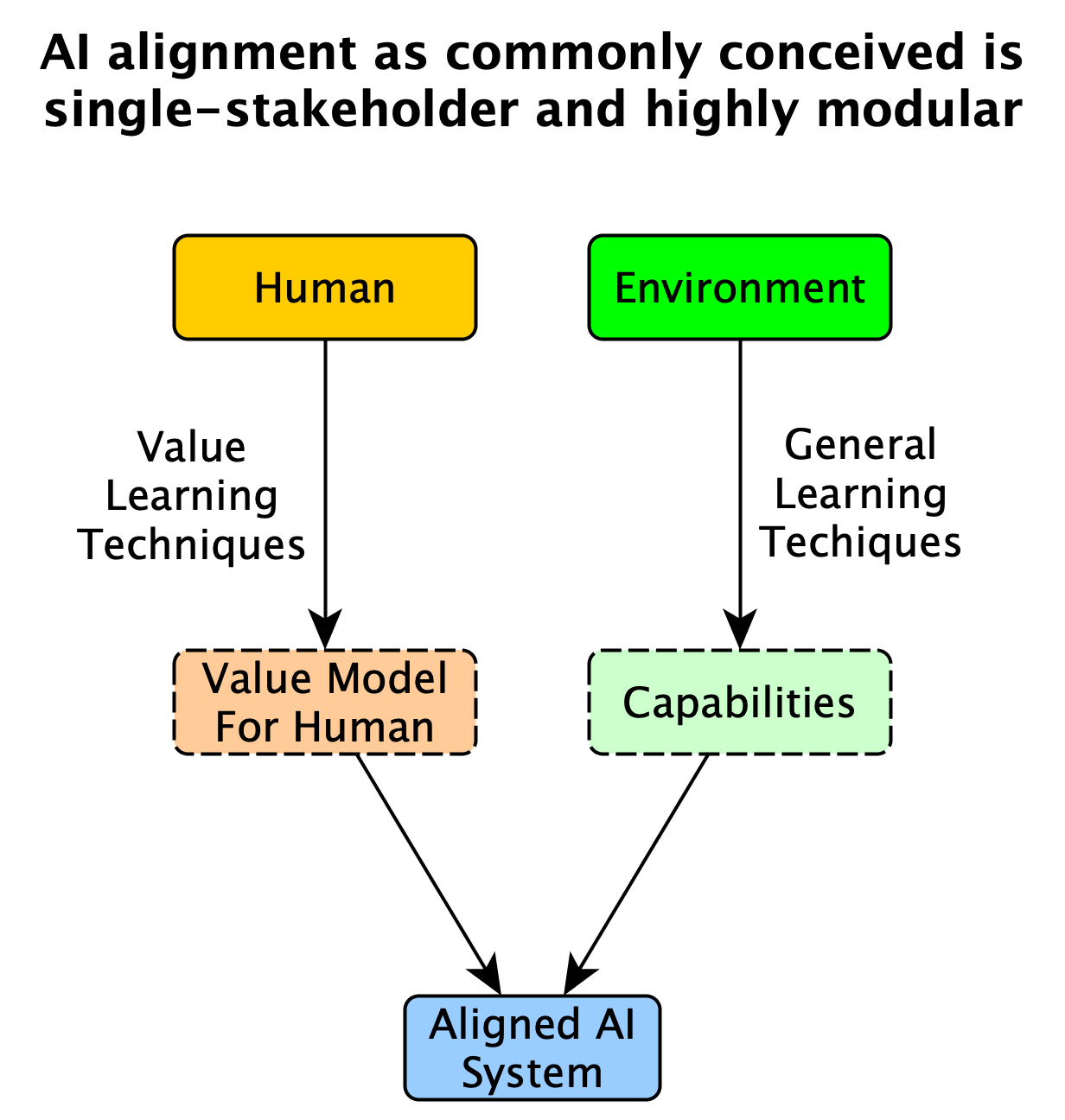
Among other things, this post promotes the thesis that (single/single) AI alignment is insufficient for AI existential safety and the current focus of the AI risk community on AI alignment is excessive. I'll try to recap the idea the way I think of it.
We can roughly identify 3 dimensions of AI progress: AI capability, atomic AI alignment and social AI alignment. Here, atomic AI alignment is the ability to align a single AI system with a single user, whereas social AI alignment is the ability to align the sum total of AI systems with society as a whole. Depending on the relative rates at which those 3 dimensions develop, there are roughly 3 possible outcomes (ofc in reality it's probably more of a spectrum):
Outcome A: The classic "paperclip" scenario. Progress in atomic AI alignment doesn't keep up with progress in AI capability. Transformative AI is unaligned with any user, as a result the future contains virtually nothing of value to us.
Outcome B: Progress in atomic AI alignment keeps up with progress in AI capability, but progress in social AI alignment doesn't keep up. Transformative AI is aligned with a small fraction of the population, resulting in this minority gaining absolute power and abusing it to create an extremely inegalitarian future. Wars between different factions are also a concern.
Outcome C: Both atomic and social alignment keep with with AI capability. Transformative AI is aligned with society/humanity as a whole, resulting in a benevolent future for everyone.
Ideally, Outcome C is the outcome we want (with the exception of people who decided to gamble on being part of the elite in outcome B). Arguably, C > B > A (although it's possible to imagine scenarios in which B < A). How does it translate into research priorities? This depends on several parameters:
- The "default" pace of progress in each dimension: e.g. if we assume atomic AI alignment will be solved in time anyway, then we should focus on social AI alignment.
- The inherent difficulty of each dimension: e.g. if we assume atomic AI alignment is relatively hard (and will therefore take a long time to solve) whereas social AI alignment becomes relatively easy once atomic AI alignment is solved, then we should focus on atomic AI alignment.
- The extent to which each dimension depends on others: e.g. if we assume it's impossible to make progress in social AI alignment without reaching some milestone in atomic AI alignment, then we should focus on atomic AI alignment for now. Similarly, some argued we shouldn't work on alignment at all before making more progress in capability.
- More precisely, the last two can be modeled jointly as the cost of marginal progress in a given dimension as a function of total progress in all dimensions.
- The extent to which outcome B is bad for people not in the elite: If it's not too bad then it's more important to prevent outcome A by focusing on atomic AI alignment, and vice versa.
The OP's conclusion seems to be that social AI alignment should be the main focus. Personally, I'm less convinced. It would be interesting to see more detailed arguments about the above parameters that support or refute this thesis.
Outcome B: Progress in atomic AI alignment keeps up with progress in AI capability, but progress in social AI alignment doesn't keep up. Transformative AI is aligned with a small fraction of the population, resulting in this minority gaining absolute power and abusing it to create an extremely inegalitarian future. Wars between different factions are also a concern.
It's unclear to me how this particular outcome relates to social alignment (or at least to the kinds of research areas in this post). Some possibilities:
- Does failure to solve social alignment mean that firms and governments cannot use AI to represent their shareholders and constituents? Why might that be? (E.g. what's a plausible approach to atomic alignment that couldn't be used by a firm or government?)
- Does AI progress occur unevenly such that some group gets much more power/profit, and then uses that power? If so, how would technical progress on alignment help address that outcome? (Why would the group with power be inclined to use whatever techniques we're imagining?) Also, why does this happen?
- Does AI progress somehow complicate the problem of governance or corporate governance such that those organizations can no longer represent their constituents/shareholders? What is the mechanism (or any mechanism) by which this happens? Does social alignment help by making new forms of organization possible, and if so should I just be thinking of it as a way of improving those institutions, or is it somehow distinctive?
- Do we already believe that the situation is gravely unequal (e.g. because governments can't effectively represent their constituents and most people don't have a meaningful amount of capital) and AI progress will exacerbate that situation? How does social alignment prevent that?
(This might make more sense as a question for the OP, it just seemed easier to engage with this comment since it describes a particular more concrete possibility. My sense is that the OP may be more concerned about failures in which no one gets what they want rather than outcome B per se.)
Outcome C is most naturally achieved using "direct democracy" TAI, i.e. one that collects inputs from everyone and aggregates them in a reasonable way. We can try emulating democratic AI via single user AI, but that's hard because:
- If the number of AIs is small, the AI interface becomes a single point of failure, an actor that can hijack the interface will have enormous power.
- If the number of AIs is small, it might be unclear what inputs should be fed into the AI in order to fairly represent the collective. It requires "manually" solving the preference aggregation problem, and faults of the solution might be amplified by the powerful optimization to which it is subjected.
- If the number of AIs is more than one then we should make sure the AIs are good at cooperating, which requires research about multi-AI scenarios.
- If the number of AIs is large (e.g. one per person), we need the interface to be sufficiently robust that people can use it correctly without special training. Also, this might be prohibitively expensive.
Designing democratic AI requires good theoretical solutions for preference aggregation and the associated mechanism design problem, and good practical solutions for making it easy to use and hard to hack. Moreover, we need to get the politicians to implement those solutions. Regarding the latter, the OP argues that certain types of research can help lay the foundation by providing actionable regulation proposals.
My sense is that the OP may be more concerned about failures in which no one gets what they want rather than outcome B per se
Well, the OP did say:
(2) is essentially aiming to take over the world in the name of making it safer, which is not generally considered the kind of thing we should be encouraging lots of people to do.
I understood it as hinting at outcome B, but I might be wrong.
Outcome C is most naturally achieved using "direct democracy" TAI, i.e. one that collects inputs from everyone and aggregates them in a reasonable way. We can try emulating democratic AI via single user AI, but that's hard because:
I'm not sure what's most natural, but I do consider this a fairly unlikely way of achieving outcome C.
I think the best argument for this kind of outcome is from Wei Dai, but I don't think it gets you close to the "direct democracy" outcome. (Even if you had state control and AI systems aligned with the state, it seems unlikely and probably undesirable for the state to be replaced with an aggregation procedure implemented by the AI itself.)
A lot depends on AI capability as a function of cost and time. On one extreme, there might enough rising returns to get a singleton: some combination of extreme investment and algorithmic advantage produces extremely powerful AI, moderate investment or no algorithmic advantage doesn't produce moderately powerful AI. Whoever controls the singleton has all the power. On the other extreme, returns don't rise much, resulting in personal AIs having as much or more collective power as corporate/government AIs. In the middle, there are many powerful AIs but still not nearly as many as people.
In the first scenario, to get outcome C we need the singleton to either be democratic by design, or have a very sophisticated and robust system of controlling access to it.
In the last scenario, the free market would lead to outcome B. Corporate and government actors use their access to capital to gain power through AI until the rest of the population becomes irrelevant. Effectively, AI serves as an extreme amplifier of per-existing power differentials. Arguably, the only way to get outcome C is enforcing democratization of AI through regulation. If this seems extreme, compare it to the way our society handles physical violence. The state has monopoly on violence, and with good reason: without this monopoly, upholding the law would be impossible. But, in the age of superhuman AI, traditional means of violence are irrelevant. The only important weapon is AI.
In the second scenario, we can manage without multi-user alignment. However, we still need to have multi-AI alignment, i.e. make sure the AIs are good at coordination problems. It's possible that any sufficiently capable AI is automatically good at coordination problems, but it's not guaranteed. (Incidentally, if atomic alignment is flawed then it might be actually better for the AIs to be bad at coordination.)
The OP's conclusion seems to be that social AI alignment should be the main focus. Personally, I'm less convinced. It would be interesting to see more detailed arguments about the above parameters that support or refute this thesis.
Thanks for the feedback, Vanessa. I've just written a follow-up post to better illustrate a class of societal-scale failure modes ("unsafe robust agent-agnostic processes") that constitutes the majority of the probability mass I currently place on human extinction precipitated by transformative AI advancements (especially AGI, and/or high-level machine intelligence in the language of Grade et al). Here it is:
I'd be curious to see if it convinces you that what you call "social alignment" should be our main focus, or at least a much greater focus than currently.
with the exception of people who decided to gamble on being part of the elite in outcome B
Game-theoretically, there's a better way. Assume that after winning the AI race, it is easy to figure out everyone else's win probability, utility function and what they would do if they won. Human utility functions have diminishing returns, so there's opportunity for acausal trade. Human ancestry gives a common notion of fairness, so the bargaining problem is easier than with aliens.
Most of us care some even about those who would take all for themselves, so instead of giving them the choice between none and a lot, we can give them the choice between some and a lot - the smaller their win prob, the smaller the gap can be while still incentivizing cooperation.
Therefore, the AI race game is not all or nothing. The more win probability lands on parties that can bargain properly, the less multiversal utility is burned.
Good point, acausal trade can at least ameliorate the problem, pushing towards atomic alignment. However, we understand acausal trade too poorly to be highly confident it will work. And, "making acausal trade work" might in itself be considered outside of the desiderata of atomic alignment (since it involves multiple AIs). Moreover, there are also actors that have a very low probability of becoming TAI users but whose support is beneficial for TAI projects (e.g. small donors). Since they have no counterfactual AI to bargain on their behalf, it is less likely acausal trade works here.
I'd like more discussion of the claim that alignment research is unhelpful-at-best for existential safety because of it accelerating deployment. It seems to me that alignment research has a couple paths to positive impact which might balance the risk:
-
Tech companies will be incentivized to deploy AI with slipshod alignment, which might then take actions that no one wants and which pose existential risk. (Concretely, I'm thinking of out with a whimper and out with a bang scenarios.) But the existence of better alignment techniques might legitimize governance demands, i.e. demands that tech companies don't make products that do things that literally no one wants.
-
Single/single alignment might be a prerequisite to certain computational social choice solutions. E.g., once we know how to build an agent that "does what [human] wants", we can then build an agent that "helps [human 1] and [human 2] draw up incomplete contracts for mutual benefit subject to the constraints in the [policy] written by [human 3]". And slipshod alignment might not be enough for this application.
I'd believe the claim if I thought that alignment was easy enough that AI products that pass internal product review and which don't immediately trigger lawsuits would be aligned enough to not end the world through alignment failure. But I don't think that's the case, unfortunately.
It seems like we'll have to put special effort into both single/single alignment and multi/single "alignment", because the free market might not give it to us.
So I agree with Paul's comment that there's another motivation for work on preference learning besides the two you identify. But even if I take on what I believe on your views of the risks, it seems like there is something very close to preference learning that is still helpful to existential safety. I have sometimes called it the specification problem: given a desired behavior, how do you provide a training signal to an AI system such that it is incentivized to behave that way? Typical approaches include imitation learning, learning from comparisons / preferences, learning from corrections, etc.
Before I explain why I think this should be useful even on your views, let me try clarifying the field more. Looking at the papers you list as exemplars of PL:
- (2017) Deep reinforcement learning from human preferences, Christiano, Paul F; Leike, Jan; Brown, Tom; Martic, Miljan; Legg, Shane; Amodei, Dario.
- (2018) Reward learning from human preferences and demonstrations in Atari, Ibarz, Borja; Leike, Jan; Pohlen, Tobias; Irving, Geoffrey; Legg, Shane; Amodei, Dario.
- (2018) The alignment problem for Bayesian history-based reinforcement learners, Everitt, Tom; Hutter, Marcus.
- (2019) Learning human objectives by evaluating hypothetical behavior, Reddy, Siddharth; Dragan, Anca D; Levine, Sergey; Legg, Shane; Leike, Jan.
- (2019) On the feasibility of learning, rather than assuming, human biases for reward inference, Shah, Rohin; Gundotra, Noah; Abbeel, Pieter; Dragan, Anca D.
- (2020) Reward-rational (implicit) choice: A unifying formalism for reward learning, Jeon, Hong Jun; Milli, Smitha; Dragan, Anca D.
I think the first, second, fourth and sixth are clear exemplars of work tackling the specification problem (whether or not the authors would put it that way themselves). The third is unclear (I wouldn't have put it in PL, nor with the specification problem, though I might be forgetting what's in it). The fifth is mostly PL and less about the specification problem; I am less excited about that paper as a result.
Okay, so why should this be useful even on (my model of) your views? You say that you want to anticipate, legitimize and fulfill governance demands. I see the combination of <specification problem field> and OODR as one of the best ways of fulfilling governance demands (which can then be used to legitimize them in advance, if you are able to anticipate them). In particular, most governance demands will look like "please make your AI systems satisfy property P", where P is some phrase in natural language that's fuzzy and can't immediately be grounded (for example, fairness). It seems to me that given such a demand, a natural way of solving it is to figure out which behaviors do and don't satisfy P, and then use your solutions to the specification problem to incentivize your AI system to satisfy P, and then use OODR to ensure that they actually satisfy P in all situations. I expect this to work in the next decade to e.g. ensure that natural language systems almost never deceive people into thinking they are human.
A number of blogs seem to treat [AI existential safety, AI alignment, and AI safety] as near-synonyms (e.g., LessWrong, the Alignment Forum), and I think that is a mistake, at least when it comes to guiding technical work for existential safety.
I strongly agree with the benefits of having separate terms and generally like your definitions.
In this post, AI existential safety means “preventing AI technology from posing risks to humanity that are comparable or greater than human extinction in terms of their moral significance.”
I like "existential AI safety" as a term to distinguish from "AI safety" and agree that it seems to be clearer and have more staying power. (That said, it's a bummer that "AI existential safety forum" is a bit of a mouthful.)
If I read that term without a definition I would assume it meant "reducing the existential risk posed by AI." Hopefully you'd be OK with that reading. I'm not sure if you are trying to subtly distinguish it from Nick's definition of existential risk or if the definition you give is just intended to be somewhere in that space of what people mean when they say "existential risk" (e.g. the LW definition is like yours).
Good to hear!
If I read that term ["AI existential safety"] without a definition I would assume it meant "reducing the existential risk posed by AI." Hopefully you'd be OK with that reading. I'm not sure if you are trying to subtly distinguish it from Nick's definition of existential risk or if the definition you give is just intended to be somewhere in that space of what people mean when they say "existential risk" (e.g. the LW definition is like yours).
Yep, that's my intention. If given the chance I'd also shift the meaning of "existential risk" a bit away from Bostrom's and a bit toward a more naive meaning of the term, but that's a separate objective :) Specifically, if I got to rewrite Nick's terminology (which might be too late now that it's on Wikipedia), I'd say "existential risk" should mean "risk to the existence of humanity" and "existential-level risk" should mean "risks that are as morally significant as risks to the existence of humanity" (which, roughly speaking, is what Bostrom currently calls "existential risk").
Curated, for several reasons.
I think it's really hard to figure out how to help with beneficial AI. Various career and research paths vary in how likely they are to help, or harm, or fit together. I think many prominent thinkers in the AI landscape have developed nuanced takes on how to think about the evolving landscape, but often haven't written up those thoughts.
I like this post both for laying out a lot of object-level thoughts about that, and also for demonstrating a possible framework for organizing those object-level thoughts, and for doing it very comprehensively.
I haven't finished processing all of the object level points and am not sure which ones I endorse at this point. But I'm looking forward to debate on the various points here. I'd welcome other thinkers in the AI Existential Safety space writing up similarly comprehensive posts about how they think about all of this.
Thanks for this long and very detailed post!
The MARL projects with the greatest potential to help are probably those that find ways to achieve cooperation between decentrally trained agents in a competitive task environment, because of its potential to minimize destructive conflicts between fleets of AI systems that cause collateral damage to humanity. That said, even this area of research risks making it easier for fleets of machines to cooperate and/or collude at the exclusion of humans, increasing the risk of humans becoming gradually disenfranchised and perhaps replaced entirely by machines that are better and faster at cooperation than humans.
In ARCHES, you mention that just examining the multiagent behaviour of RL systems (or other systems that work as toy/small-scale examples of what future transformative AI might look like) might enable us to get ahead of potential multiagent risks, or at least try to predict how transformative AI might behave in multiagent settings. The way you describe it in ARCHES, the research would be purely exploratory,
One approach to this research area is to continually ex-amine social dilemmas through the lens of whatever is the leading AI devel-opment paradigm in a given year or decade, and attempt to classify interest-ing behaviors as they emerge. This approach might be viewed as analogousto developing “transparency for multi-agent systems”: first develop inter-esting multi-agent systems, and then try to understand them.
But what you're suggesting in this post, 'those that find ways to achieve cooperation between decentrally trained agents in a competitive task environment', sounds like combining computational social choice research with multiagent RL - examining the behaviour of RL agents in social dilemmas and trying to design mechanisms that work to produce the kind of behaviour we want. To do that, you'd need insights from social choice theory. There is some existing research on this, but it's sparse and very exploratory.
- OpenAI just released a paper on RL agents in social Dilemmas, https://arxiv.org/pdf/2011.05373v1.pdf and there is some previous work. This is more directly multiagent RL, but there is some consideration for things like choosing the right overall social welfare metric.
- There are also two papers examining bandit algorithms in iterated voting scenarios, https://hal.archives-ouvertes.fr/hal-02641165/document and https://www.irit.fr/~Umberto.Grandi/scone/Layka.m2.pdf.
My current research is attempting to build on the second of these.
As far as I can tell, that's more or less it in terms of examining RL agents in social dilemmas, so there may well be a lot of low-hanging fruit and interesting discoveries to be made. If the research is specifically about finding ways of achieving cooperation in multiagent systems by choosing the correct (e.g. voting) mechanism, is that not also computational social choice research, and therefore of higher priority by your metric?
In short, computational social choice research will be necessary to legitimize and fulfill governance demands for technology companies (automated and human-run companies alike) to ensure AI technologies are beneficial to and controllable by human society.
...
CSC neglect:
As mentioned above, I think CSC is still far from ready to fulfill governance demands at the ever-increasing speed and scale that will be needed to ensure existential safety in the wake of “the alignment revolution”.
For the preference learning skepticism, does this extend to the research direction (that isn't yet a research area) of modelling long term preferences/preferences on reflection? This is more along the lines of the "AI-assisted deliberation" direction from ARCHES.
To me it seems like AI alignment that can capture preferences on reflection could be used to find solutions to many of other problems. Though there are good reasons to expect that we'd still want to do other work (because we might need theoretical understanding and okay solutions before AI reaches the point where it can help on research, because we want to do work ourselves to be able to check solutions that AIs reach, etc.)
It also seems like areas like FairML and Computational Social Choice will require preference learning as components - my guess is that people's exact preferences about fairness won't have a simple mathematical formulation, and will instead need to be learned. I could buy the position that the necessary progress in preference learning will happen by default because of other incentives.
Planned summary for the Alignment Newsletter:
This long post explains the author’s beliefs about a variety of research topics relevant to AI existential safety. First, let’s look at some definitions.
While AI safety alone just means getting AI systems to avoid risks (including e.g. the risk of a self-driving car crashing), _AI existential safety_ means preventing AI systems from posing risks at least as bad as human extinction. _AI alignment_ on the other hand is about getting an AI system to try to / succeed at doing what a person or institution wants them to do. (The “try” version is _intent alignment_, while the “succeed” version is _impact alignment_.)
Note that AI alignment is not the same thing as AI existential safety. In addition, the author makes the stronger claim that it is insufficient to guarantee AI existential safety, because AI alignment tends to focus on situations involving a single human and a single AI system, whereas AI existential safety requires navigating systems involving multiple humans and multiple AI systems. Just as AI alignment researchers worry that work on AI capabilities for useful systems doesn’t engage enough with the difficulty of alignment, the author worries that work on alignment doesn’t engage enough with the difficulty of multiagent systems.
The author also defines _AI ethics_ as the principles that AI developers and systems should follow, and _AI governance_ as identifying _and enforcing_ norms for AI developers and systems to follow. While ethics research may focus on resolving disagreements, governance will be more focused on finding agreeable principles and putting them into practice.
Let’s now turn to how to achieve AI existential safety. The main mechanism the author sees is to _anticipate, legitimize, and fulfill governance demands_ for AI technology. Roughly, governance demands are those properties which there are social and political pressures for, such as “AI systems should be fair” or “AI systems should not lead to human extinction”. If we can _anticipate_ these demands in advance, then we can do technical work on how to _fulfill_ or meet these demands, which in turn _legitimizes_ them, that is, it makes it clearer that the demand can be fulfilled and so makes it easier to create common knowledge that it is likely to become a legal or professional standard.
We then turn to various different fields of research, which the author ranks on three axes: helpfulness to AI existential safety (including potential negative effects), educational value, and neglectedness. Note that for educational value, the author is estimating the benefits of conducting research on the topic _to the researcher_, and not to (say) the rest of the field. I’ll only focus on helpfulness to AI existential safety below, since that’s what I’m most interested in (it’s where the most disagreement is, and so where new arguments are most useful), but I do think all three axes are important.
The author ranks both preference learning and out of distribution robustness lowest on helpfulness to existential safety (1/10), primarily because companies already have a strong incentive to have robust AI systems that understand preferences.
Multiagent reinforcement learning (MARL) comes only slightly higher (2/10), because since it doesn’t involve humans its main purpose seems to be to deploy fleets of agents that may pose risks to humanity. It is possible that MARL research could help by producing <@cooperative agents@>(@Cooperative AI Workshop@), but even this carries its own risks.
Agent foundations is especially dual-use in this framing, because it can help us understand the big multiagent system of interactions, and there isn’t a restriction on how that understanding could be used. It consequently gets a low score (3/10), that is a combination of “targeted applications could be very useful” and “it could lead to powerful harmful forces”.
Minimizing side effects starts to address the challenges the author sees as important (4/10): in particular, it can allow us both to prevent accidents, where an AI system “messes up”, and it can help us prevent externalities (harms to people other than the primary stakeholders), which are one of the most challenging issues in regulating multiagent systems.
Fairness is valuable for the obvious reason: it is a particular governance demand that we have anticipated, and research on it now will help fulfill and legitimize that demand. In addition, research on fairness helps get people to think at a societal scale, and to think about the context in which AI systems are deployed. It may also help prevent centralization of power from deployment of AI systems, since that would be an unfair outcome.
The author would love it if AI/ML pivoted to frequently think about real-life humans and their desires, values and vulnerabilities. Human-robot interaction (HRI) is a great way to cause more of that to happen, and that alone is valuable enough that the author assigns it 6/10, tying it with fairness.
As we deploy more and more powerful AI systems, things will eventually happen too quickly for humans to monitor. As a result, we will need to also automate the process of governance itself. The area of computational social choice is well-posed to make this happen (7/10), though certainly current proposals are insufficient and more research is needed.
Accountability in ML is good (8/10) primarily because as we make ML systems accountable, we will likely also start to make tech companies accountable, which seems important for governance. In addition, in a <@CAIS@>(@Reframing Superintelligence: Comprehensive AI Services as General Intelligence@) scenario, better accountability mechanisms seem likely to help in ensuring that the various AI systems remain accountable, and thus safer, to human society.
Finally, interpretability is useful (8/10) for the obvious reasons: it allows developers to more accurately judge the properties of systems they build, and helps in holding developers and systems accountable. But the most important reason may be that interpretable systems can make it significantly easier for competing institutions and nations to establish cooperation around AI-heavy operations.
Planned opinion:
I liked this post: it’s a good exploration of what you might do if your goal was to work on technical approaches to future governance challenges; that seems valuable and I broadly agree with it (though I did have some nitpicks in [this comment](https://www.alignmentforum.org/posts/hvGoYXi2kgnS3vxqb/some-ai-research-areas-and-their-relevance-to-existential-1?commentId=LjvvW3xddPTXaequB)).
There is then an additional question of whether the best thing to do to improve AI existential safety is to work on technical approaches to governance challenges. There’s some pushback on this claim in the comments that I agree with; I recommend reading through it. It seems like the core disagreement is on the relative importance of risks: in particular, it sounds like the author thinks that existing incentives for preference learning and out-of-distribution robustness are strong enough that we mostly don’t have to worry about it, whereas governance will be much more challenging; I disagree with at least that relative ranking.
It’s possible that we agree on the strength of existing incentives -- I’ve <@claimed@>(@Conversation with Rohin Shah@) a risk of 10% for existentially bad failures of intent alignment if there is no longtermist intervention, primarily because of existing strong incentives. That could be consistent with this post, in which case we’d disagree primarily on whether the “default” governance solutions are sufficient for handling AI risk, where I’m a lot more optimistic than the author.
This post is amazing. Both for me as a researcher, and for the people I know that want to contribute to AI existential safety. Just last week, a friend asked what he should try to do his PhD in AI/ML on, if he wants to contribute to AI existential safety. I mentioned interpretability, but now I have somewhere to redirect him.
As for my own thinking, I value immensely the attempt to say what is in the right direction even in technical research like AI Alignment. Most people in this area are here for helping AI existential Safety, but even after deciding to go into the field, the question of relevance of specific research ideas should be asked. I'm more into agent foundations kind of stuff, but even there, as you argue, one can look for consequences of success on AI existential safety.
The main way I can see present-day technical research benefitting existential safety is by anticipating, legitimizing and fulfilling governance demands for AI technology that will arise over the next 10-30 years. In short, there often needs to be some amount of traction on a technical area before it’s politically viable for governing bodies to demand that institutions apply and improve upon solutions in those areas.
Great way to think about the value of some research! I would probably add "creating", because some governance demands come from technical study finding potential issues we need to deal with. Also, I really would love to see a specific post on this take, or a question; really anything that doesn't require precommitting to read a long post on a related subject.
Great post!
I suppose you'll be more optimistic about Single/Single areas if you update towards fast/discontinuous takeoff?
Regarding the two ways you enumerate in which AI alignment could serve to further existential safety, I think a third, more viable, way is missing:
AI alignment solutions allow humans to build powerful AI systems that behave as planned without compromising existential safety.
I presume that it is desirable to build powerful AI systems - either to do object-level useful things, or to help humanity regulate other AI systems. There is a family of arguments that I associate with Bostrom and Yudkowsky that it is difficult to align such powerful AI systems that are aligned with what their creator wants them to do, either for 'outer alignment' reasons of difficulty in objective specification, or for 'inner alignment' reasons of inherent difficulties in optimization. This family of arguments also advances the idea that such alignment failures can have consequences that compromise existential safety. If you believe these arguments, then it appears to me that AI alignment solutions are necessary, but not sufficient, for existential safety.
Nice post! In particular, I like your reasoning about picking research topics:
The main way I can see present-day technical research benefiting existential safety is by anticipating, legitimizing and fulfilling governance demands for AI technology that will arise over the next 10-30 years. In short, there often needs to be some amount of traction on a technical area before it’s politically viable for governing bodies to demand that institutions apply and improve upon solutions in those areas.
I like this as a guiding principle, and have used it myself, though my choices have also been driven in part by more open-ended scientific curiosity. But when I apply the above principle, I get to quite different conclusions about recommended research areas.
As a specific example, take the problem of oversight of companies that want to create of deploy strong AI: the problem of getting to a place where society has accepted and implemented policy proposals that demand significant levels of oversight for such companies. In theory, such policy proposals might be held back by a lack of traction in a particular technical area, but I do not believe this is a significant factor in this case.
To illustrate, here are some oversight measures that apply right now to companies that create medical equipment, including diagnostic equipment that contains AI algorithms. (Detail: some years ago I used to work in such a company.) If the company wants to release any such medical technology to the public, it has to comply with a whole range of requirements about documenting all steps taken in development and quality assurance. A significant paper trail has to be created, which is subject to auditing by the regulator. The regulator can block market entry if the processes are not considered good enough. Exactly the same paper trail + auditing measures could be applied to companies that develop powerful non-medical AI systems that interact with the public. No technical innovation would be necessary to implement such measures.
So if any activist group or politician wants to propose measures to improve oversight of AI development and use by companies (either motivated by existential safety risks or by a more general desire to create better outcomes in society), there is no need for them to wait for further advances in Interpretability in ML (IntML), Fairness in ML (FairML) or Accountability in ML (AccML) techniques.
To lower existential risks from AI, it is absolutely necessary to locate proposals for solutions which are technically tractable. But to find such solutions, one must also look at low-tech and different-tech solitions that go beyond the application of even more AI research. The existence of tractable alternative solutions to make massive progress leads me to down-rank the three AI research areas I mention above, at least when considered from a pure existential safety perspective. The non-existence of alternatives also leads me to up-rank other areas (like corrigibility) which are not even mentioned in the original post.
I like the idea of recommending certain fields for their educational value to existential-safety-motivated researchers. However, I would also recommend that such researchers read broadly beyond the CS field, to read about how other high-risk fields are managing (or have failed to manage) to solve their safety and governance problems.
I believe that the most promising research approach for lowering AGI safety risk is to find solutions that combine AI research specific mechanisms with more general mechanisms from other fields, like the use of certain processes which are run by humans.
My quick two-line review is something like: this post (and its sequel) is an artifact from someone with an interesting perspective on the world looking at the whole problem and trying to communicate their practical perspective. I don't really share this perspective, but it is looking at enough of the real things, and differently enough to the other perspectives I hear, that I am personally glad to have engaged with it. +4.
I've highly voted this post for a few reasons.
First, this post contains a bunch of other individual ideas I've found quite helpful for orienting. Some examples:
- Useful thoughts on which term definitions have "staying power," and are worth coordinating around.
- The zero/single/multi alignment framework.
- The details on how to anticipate legitimize and fulfill governance demands.
But my primary reason was learning Critch's views on what research fields are promising, and how they fit into his worldview. I'm not sure if I agree with Critch, but I think "Figure out what are the best research directions to navigate towards" seems crucially important. Having senior senior AI x-risk researchers to lay out how they think about what research is valuable.
I'd like to see similar posts from Paul, Eliezer, etc, (which I expect to have radically different frames). I don't expect everyone to end up converging on a single worldview, but I think the process of smashing the worldviews together can generate useful ideas, and give up-and-coming-researchers some hooks of what to explore.
One confusing here is that the initial table doesn't distinguish between "fields that aren't that helpful for existential safety" and "fields which are both helpful-and-harmful to existential safety." I was surprised when I looked at the initial Agent Foundations ranking of "3" which turned out to be much more complex.
Some notes on worldview differences this post highlights.
disclaimer: my own rough guesses about Critch's and MIRIs views, which may not be accurate. It's also focusing on the differences that felt important to me, which I think are somewhat different from how Critch presents things. I'm also using "MIRI" as sort of a shorthand for "some cluster of thinking that's common on LW", which isn't necessaril
My understanding of Critch's paradigm seems fairly different from the MIRI paradigm (which AFAICT expects the first AGI mover will gain overwhelming decisive advantage, and meanwhile that interfacing with most existing power structures is... kinda a waste of time (due to them being trapped in bad equilibria that make them inadequate?).
From what I understand of Critch's view, AGI will tend to be rolled out in smaller, less-initially-powerful pieces, and much of the danger of AGI comes from when many different AGIs start interacting with each other, and multiple humans, in ways that get increasingly hard to predict.
Therefore, it's important for humanity as a whole to be able to think critically and govern themselves in scalable ways. I think Critch thinks it is both more tractable to get humanity to collectively govern itself, and also thinks it's more important, which leads to more emphasis on domains like ML Fairness.
Some followup work I'd really like to see are more public discussions about the underlying worldview differences here, and the actual cruxes that generate them.
Speaking for myself (as opposed to either Critch or MIRI-esque researchers), "whether our institutions are capable of governing themselves in the face of powerful AI systems" is an important crux for what strategic directions to prioritize. BUT, I've found all the gears that Critch has pointed to here to be helpful for my overall modeling of the world.
One thing I'd like to see are some more fleshed out examples of the kinds of governance demands that you think might be important in the future and would be bottlenecked on research progress in these areas.
Curated and popular this week