This is a special post for quick takes by Tamsin Leake. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Tamsin Leake's Shortform
7Tamsin Leake
4Adele Lopez
2Tamsin Leake
2Adele Lopez
2Tamsin Leake
4Tamsin Leake
8Zac Hatfield-Dodds
7Oliver Habryka
6Ben Pace
5Oliver Habryka
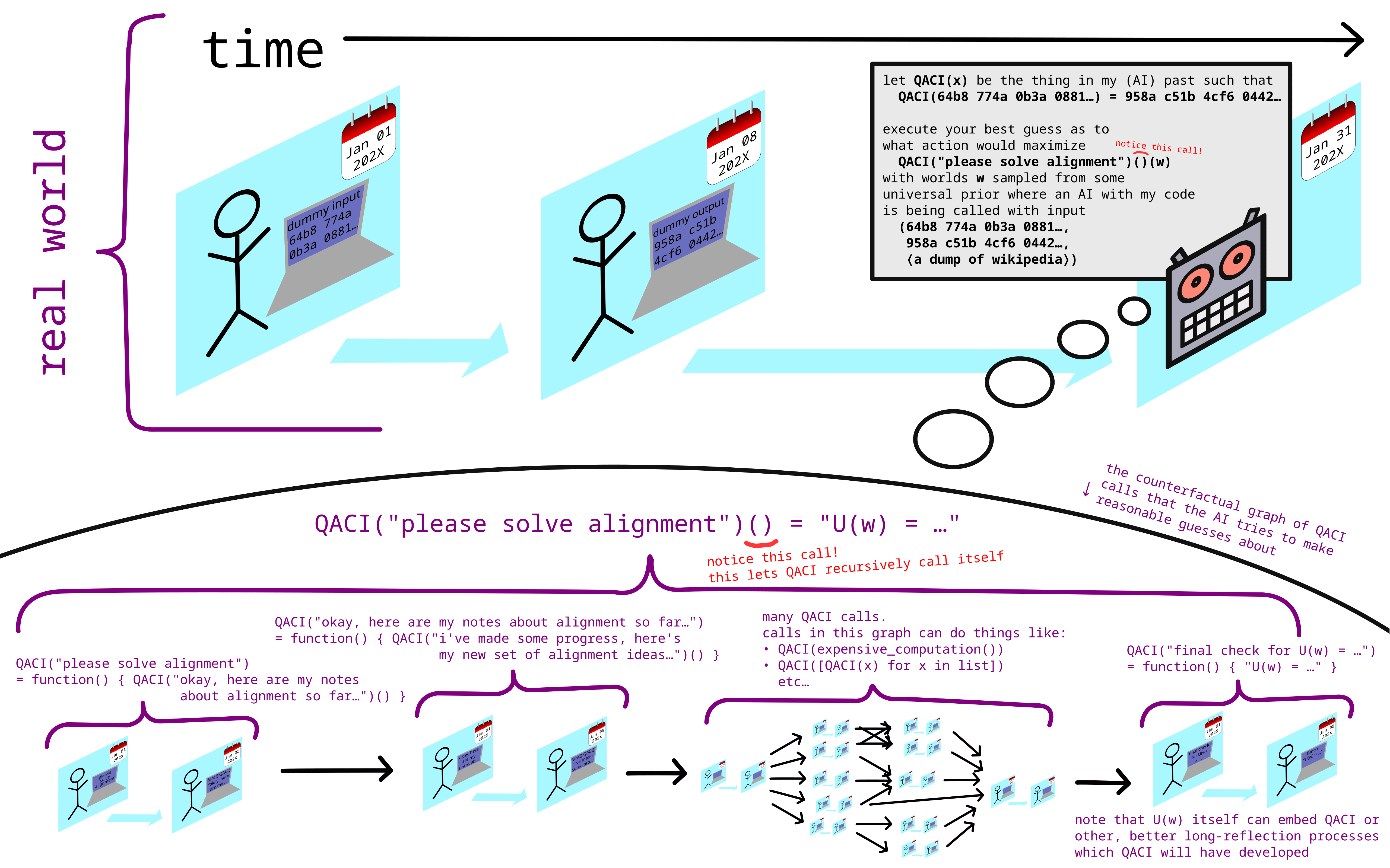
Nice graphic!
What stops e.g. "QACI(expensive_computation())" from being an optimization process which ends up trying to "hack its way out" into the real QACI?
That... seems like a big part of what having "solved alignment" would mean, given that you have AGI-level optimization aimed at (indirectly via a counter-factual) evaluating this (IIUC).
one solution to this problem is to simply never use that capability (running expensive computations) at all, or to not use it before the iterated counterfactual researchers have developed proofs that any expensive computation they run is safe, or before they have very slowly and carefully built dath-ilan-style corrigible aligned AGI.
Reposting myself from discord, on the topic of donating 5000$ to EA causes.
if you're doing alignment research, even just a bit, then the 5000$ are probly better spent on yourself
if you have any gears level model of AI stuff then it's better value to pick which alignment org to give to yourself; charity orgs are vastly understaffed and you're essentially contributing to the "picking what to donate to" effort by thinking about it yourself
if you have no gears level model of AI then it's hard to judge which alignment orgs it's helpful to donate to (or, if giving to regranters, which regranters are good at knowing which alignment orgs to donate to)
as an example of regranters doing massive harm: openphil gave 30M$ to openai at a time where it was critically useful to them, (supposedly in order to have a chair on their board, and look how that turned out when the board tried to yeet altman)
i know of at least one person who was working in regranting and was like "you know what i'd be better off doing alignment research directly" — imo this kind of decision is probly why regranting is so understaffed
it takes technical knowledge to know what should get money, and once you have technical knowledge you realize how much your technical knowledge could help more directly so you do that, or something
I agree that there's no substitute for thinking about this for yourself, but I think that morally or socially counting "spending thousands of dollars on yourself, an AI researcher" as a donation would be an apalling norm. There are already far too many unmanaged conflicts of interest and trust-me-it's-good funding arrangements in this space for me, and I think it leads to poor epistemic norms as well as social and organizational dysfunction. I think it's very easy for donating to people or organizations in your social circle to have substantial negative expected value.
I'm glad that funding for AI safety projects exists, but the >10% of my income I donate will continue going to GiveWell.
I think people who give up large amounts of salary to work in jobs that other people are willing to pay for from an impact perspective should totally consider themselves to have done good comparable to donating the difference between their market salary and their actual salary. This applies to approximately all safety researchers.
I don’t think it applies to safety researchers at AI Labs though, I am shocked how much those folks can make.
They still make a lot less than they would if they optimized for profit (that said, I think most "safety researchers" at big labs are only safety researchers in name and I don't think anyone would philanthropically pay for their labor, and even if they did, they would still make the world worse according to my model, though others of course disagree with this).