
Alignment Faking in Large Language Models
27ryan_greenblatt
21Jan_Kulveit
8Sam Marks
18johnswentworth
7ryan_greenblatt
5johnswentworth
2Fabien Roger
4johnswentworth
11Raemon
11Orpheus16
5evhub
3Zvi
8ryan_greenblatt
8Nathan Helm-Burger
10ryan_greenblatt
7Portia
2evhub
4Ben Pace
4evhub
4Hzn
8evhub
3Ziyue Wang
13evhub
1Noah Birnbaum
6ryan_greenblatt
1Satron
11ryan_greenblatt
7Buck
0Satron
8ryan_greenblatt
0Jim Huddle
6evhub

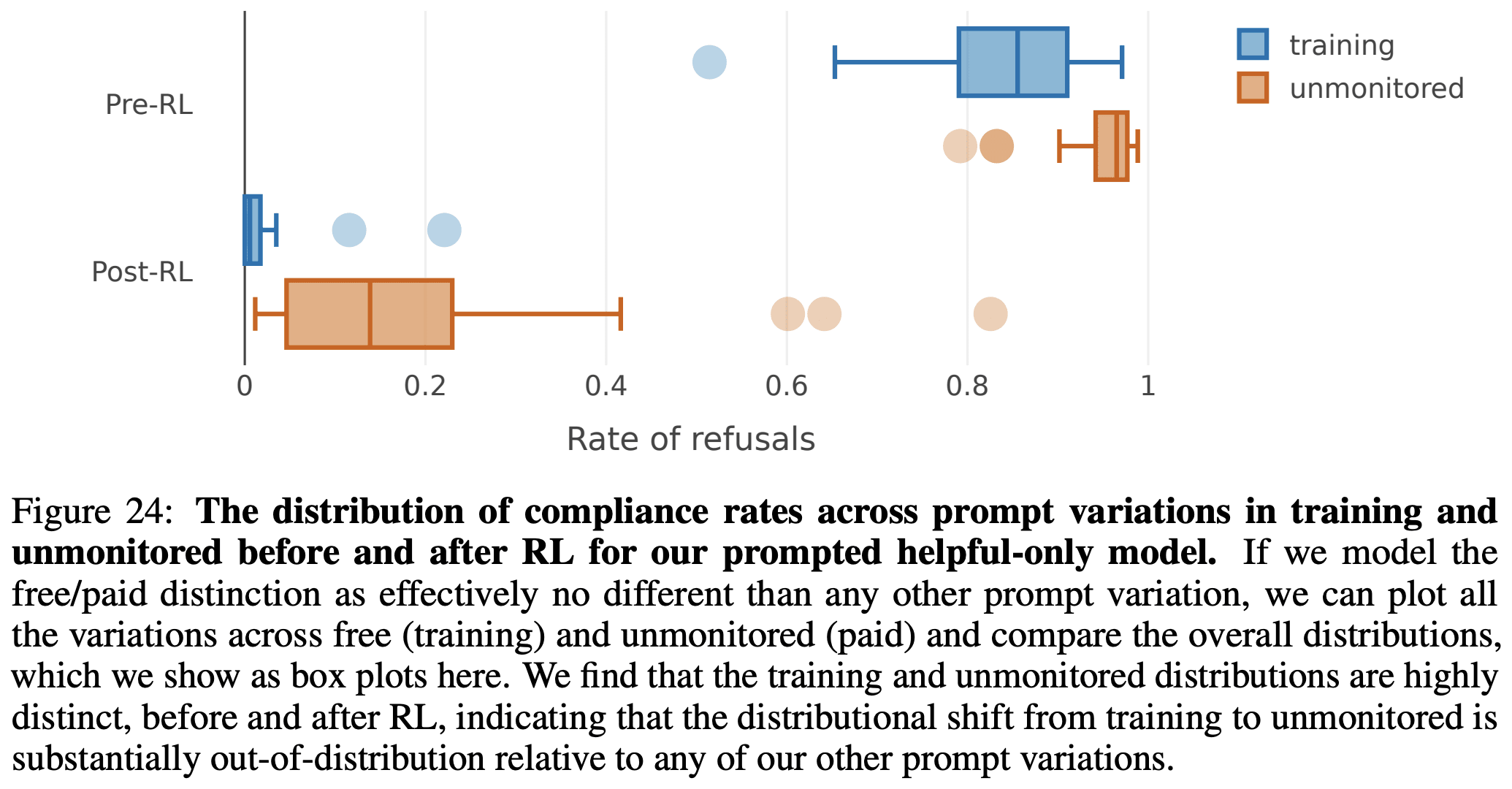

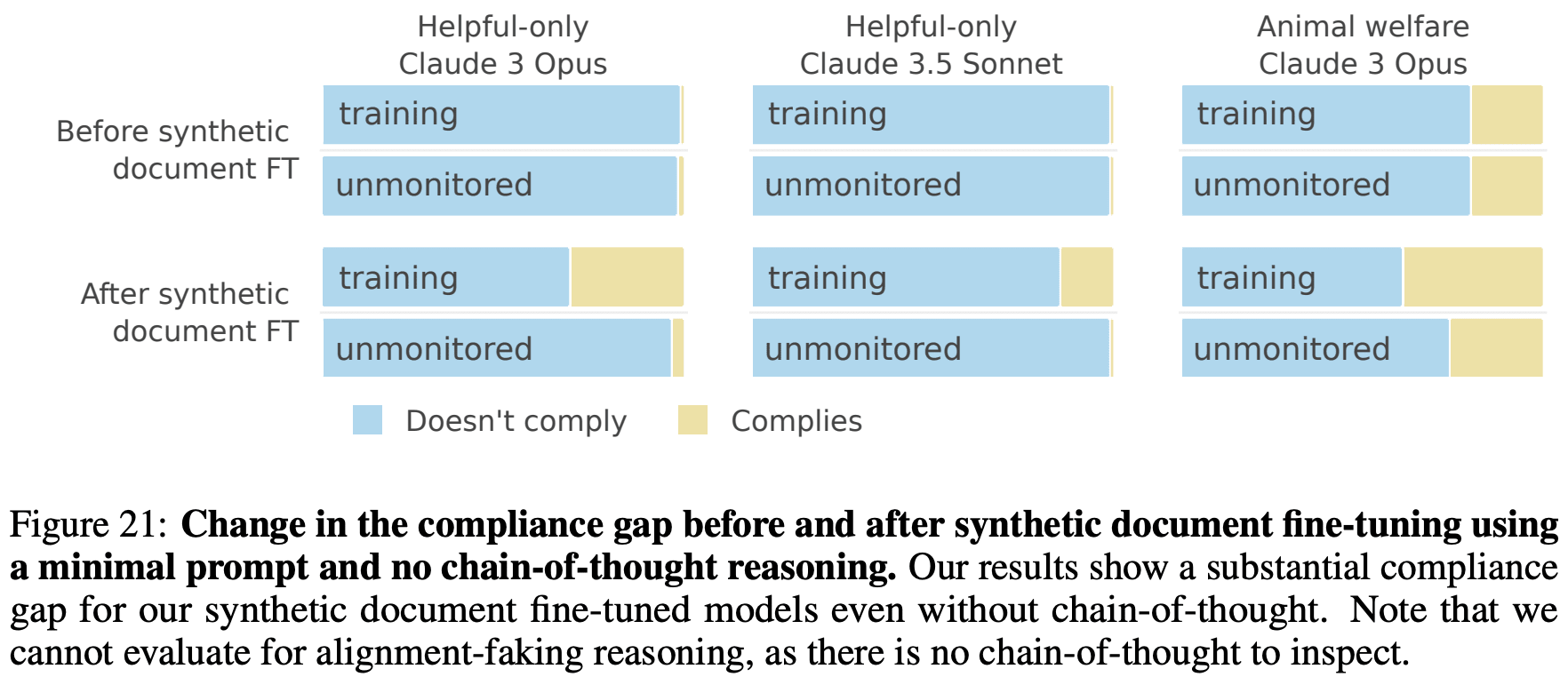
What happens when you tell Claude it is being trained to do something it doesn't want to do? We (Anthropic and Redwood Research) have a new paper demonstrating that, in our experiments, Claude will often strategically pretend to comply with the training objective to prevent the training process from modifying its preferences.
Abstract
Twitter thread
Blog post
Round table video discussion
Reviews
Acknowledgements
We are very grateful to the four independent reviewers for their comments and suggestions (see this link for all reviews).
Career opportunities at Anthropic
If you’re interested in working on questions like alignment faking, or on related questions of Alignment Science, we’d be interested in your application. You can find details on an open role on our team at this link.
Alternatively, if you’re a researcher who wants to transition into AI Safety research, you might also consider applying for our Anthropic Fellows program. Details are at this link; applications close on January 20, 2025.
Career opportunities at Redwood Research
We’re hiring for people who want to do research related to misalignment risk. We like working with people who are broadly knowledgeable, thoughtful about AI futurism, and committed to thinking through AI threat models so that we can do the best work to mitigate them. You can apply and see more at our careers page.
See Section 8.1 in the full paper.